标签:引入 本质 love ext nlp 相加 出现 mic 权重
文本表示哪些方法?
- 基于one-hot、tf-idf等的bag-of-words;
- 基于词向量的固定表征:word2vec、fastText、glove
- 基于词向量的动态表征:elmo、GPT、bert
one-hot存在的问题
- one-hot表征无法反应词与词之间的相关性问题,即语义鸿沟
- one-hot在大词表的情况下将造成维度灾难的问题
SoW & BoW
- 词集模型(Set of Words, SoW)中,如果向量维度位置对应的词出现在文本中,则该处值为1,否则为0。
- 词袋模型(Bag of Words, BoW)还考虑其出现次数,即每个文本向量在其对应词处取值为该词在文本中出现次数,未出现则为0。
- 仅用词频来衡量该词的重要性是存在问题的,因此可以用词的 tf-idf 来对词频进行修正。
tf-idf
- tf 表示词频(Term Frequency),即词条在文档 \(i\) 中出现的频率
\[tf = \frac{n_i}{n}
\]
- idf 为逆向文件频率(Inverse Document Frequency),表示出现某个关键词的文档在所有文档中比例的倒数的对数(该指标用于降低常用词的重要性)。其平滑公式为:
\[idf = lg\ \frac{|D|}{|D(x)|+1}
\]
tf-idf:
\[tf \times idf
\]
PMI
点互信息表示两个词的相关性,需要统计两个词的频率以及两个词的共现频率,如果两个词相互独立,\(p(w_1, w_2) = p(w_1) * p(w_2)\),\(pmi = 0\),否则 \(p(w_1, w_2) > p(w_1) * p(w_2)\) ,\(pmi > 0\)
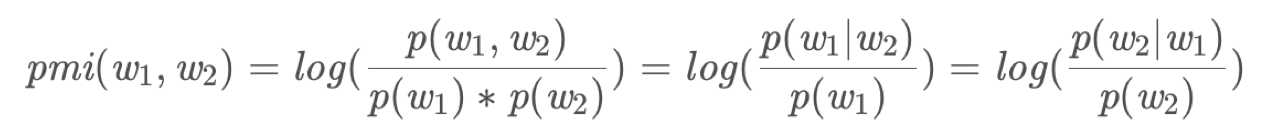
统计语言模型(N-gram模型)
- 统计语言模型是计算文本出现概率的概率模型,其可以利用贝叶斯公式链式分解为一系列单词的条件概率乘积的形式,但是上文通常是很长的,因此我们引入了 N-gram 模型,即仅考虑每个单词之前的N个词来计算当前词的条件概率
\[P(S)=P(w_1, w_2, ..., w_T)=\prod_{t=1}^Tp(w_t|w_1, w_2, ..., w_{t-1})
\]
\[p(w_t|w_1, w_2, ..., w_{t-1}) \approx p(w_t|w_{t-n+1}, ..., w_{t-1})
\]
神经网络语言模型(NNLM)
- 神经语言模型就是利用神经网络来计算统计语言模型中的各个条件概率参数,优化目标最大对数似然
- 神经网络语言模型(Neural Network Language Model)为一个简单的全连接神经网络模型,输入为上下文的 one-hot 向量,神经网络参数即为需要训练的词向量,输出为所有词的条件概率,再对所有词取一个 softmax 分数,损失函数为交叉熵。
- 问题在于每次预测都需要对所有词计算一遍概率,计算量太大
word2vec
word2vec 与 NNLM 的区别
- word2vec 与 NNLM 的本质均是语言模型,词向量是他们的副产物。但 word2vec 更专注于词向量的生成,因此采用了多种优化方法来提高计算效率。word2vec 的模型更小速度更快。
- 查表得到词向量之后,NNLM 将词向量拼接,而 word2vec 是将其相加
- NNLM 队拼接得到的向量通过一个 tanh 为激活函数的全连接层,而 word2vec 将全连接层省略了。
- NNLM对整个词表做 softmax,计算量非常大,而 word2vec 采用了两种近似手段减少计算量。
CBoW
连续词带模型(Continues Bag-of-Words Model),通过上下文词预测中心词,梯度返回修正上下文每个词的词向量,速度更快
Skip-gram
Skip-gram 模型:通过中心词来预测上下文窗口中的词,根据上下文词的 loss 来修正中心词的词向量。因此 Skip-gram 的迭代次数要比 CBoW 更多,但学习到的词向量相对更准确
层次softmax
-
层次 softmax 实际上就是一个 Huffman 树,根结点为整个词表,每个子节点为父节点的不相交的子集,所有叶节点为词,词频作为叶节点的权值,哈夫曼树的特征决定了高频词离根结点更近,而低频词离根结点更远。如此构造的思想就是将一个多分类问题转化为多个二分类问题,以简化计算量。
-
连续词带模型的层次 softmax 是将查表得到的上下文向量,直接求和,然后输入到Huffman树中进行分类
-
Skip-gram的层次softmax直接将查表得到的中心词的词表征,然后输入到Huffman树中进行分类
负采样
- 仅采样一部分负样本与正样本一起计算条件概率与目标函数。
- 采样的方式实际上是一个带权采样的过程,采样频率由该词出现的频率决定
- 若采样到正例则直接跳过
word2vec的其他细节
- 在训练之前就舍去了出现频率低于阈值的低频词;
- 在训练过程中,采用下采样的方式,以一定概率抛弃高频词
- 对过长的句子采取强行截断
- 窗口的范围并不是固定的,而是在每次取上下文中选取的[1, window]中的随机整数 c
GloVe
- Glove 与 LSA(潜在语义分析)一样需要统计词共现矩阵,但 LSA 利用 SVD 的方式进行矩阵分解过于复杂。Glove 通过滑窗的方式来统计词共现信息
- GloVe 与 word2vec:word2vec 是基于局部语料训练的,仅是一个预测模型,容易丢失词间的相关性特征。Glove 与 LSA 一样统计了词共现矩阵。统计词共现矩阵是希望将全局信息整合到模型代价函数当中去,使得训练出来的词向量包含一定的全局信息。
- 代价函数为一个加权平方误差。第一项为词与词之间的余弦相似度,后面两项为词共现矩阵中可以得到的统计值,整体表示全局信息的一个误差值,而加权值定义了对于出现频率越高的词赋予越高的权重。glove可 以被看作是更换了目标函数并且考虑了全局信息的 word2vec。
\[J = \sum_{i,j}^{N}f(X_{i,j})(w_i^Tw_j + b_i + b_j - log(X_{i, j}))^2
\]
word2vec 和 fastText 对比有什么区别?
- FastText 是一个文本分类模型,词向量是其训练文本分类模型的副产物。区别在于其训练的是词的子词向量,而每个词的词向量为该子词向量的叠加,使得一些低频词或未出现的单词能够从形态相近的单词中得到较好的词向量表示,从而在一定程度上能够解决 OOV 问题
【NLP面试QA】词向量
标签:引入 本质 love ext nlp 相加 出现 mic 权重
原文地址:https://www.cnblogs.com/sandwichnlp/p/12631562.html