标签:ret 函数 模型 this 并发 个数 进程 字符 shuf
因为如果要对海量数据进行计算,计算机的内存可能会不够。
因此可以把海量数据切割成小块多次计算。
而分布式系统可以把小块分给多态机器并行计算。
MapReduce是一种分布式计算模型,由Google提出主要用于搜索领域,解决海量数据的计算问题。
适合场景:任务可以被分解成相互独立的子问题。
MapReduce是运行在yarn上的
Map :负责把数据切割成小块各自计算。
Reduce:把各个Map的中间结果汇总。
用户只要继承Mapper类和Reduce类,重写map()和reduce()就可以实现分布式计算
两个函数的形参是key、value。
数据上传到HDFS
shell向Resource Manager发送计算请求。
Node Manager通过心跳,向Resource Manager领取计算任务。
Resource Manager分配资源,开始执行输入(InputFormat),先对文件进行分片,然后读取数据输入到Map中。
Mapper读取输入内容,解析成键值对,1行内容解析成1个键值对,每个键值对调用一次map方法。
每个键值对执行map重写的方法,把输入的键值对转换成新的键值对。
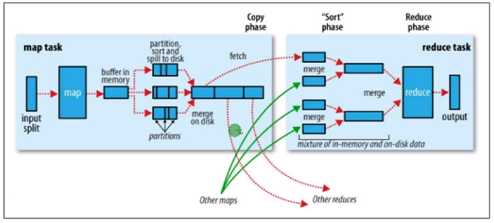
多个Mapper的输出,按照不同的分区,通过网络复制到不同的Reducer节点。
Map shuffle阶段。
Reduce shuffle阶段
对多个Mapper的输出进行合并、排序,执行重写的reduce方法,再次输出新的键值对。
把最后的结果保存到文件中。

对于HDFS中的words文件,输入是默认是按键值对输入(Hadoop内置的),内容是:
<开始字节数,本行内容>,比如第一行由9个字符,加上换行是10个字符,因此第二行输出键是10。
Mapper执行的是把输入

注意导入的包一定不能错
Mapper类有以下几个方法
setup是map方法启动的时候会执行
cleanup是map方法结束后会执行
每行数据传入一次,就执行一次map方法,而我们要重写的就是map方法

WCMapper,继承Mapper类,重写map方法
package com.rzp.utils; ? import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; ? import java.io.IOException; ? ? //继承Mapper类,泛型前两个为输入的键值对的泛型,后两个是输出的键值对泛型 //LongWritable是long对应Hadoop的序列化的类型 //Text是String对应Hadoop的序列化类型 //Hadoop的序列化机制和java不一样,所以要使用Hadoop特定的类型 //Mapper读取数据时是一行一行的读取 //输入的key(KEYIN)表示每一行的起始的字节数 //输入的value(VALUEIN)表示一行的内容 //输出key(KEYOUT)的是不同的单词 //输出的value(VALUEOUT)是1,用于后续统计累加 public class WCMapper extends Mapper<LongWritable, Text,Text,LongWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { ? String line = value.toString(); String[] words = line.split(" "); for (String word : words) { //使用context类,做一个键值对的输出 context.write(new Text(word),new LongWritable(1)); } } } ?
Reducer类也有和Mapper相同的方法名称

WCReducer继承Reducer类,重写reduce方法
package com.rzp.utils; ? import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; ? import java.io.IOException; /** * KEYIN:Reducer阶段输入的数据类型就是Mapper输出的key类型 * VALUEIN:Reducer阶段输入的数据类型就是Mapper输出的value类型 * KEYOUT:Reducer阶段输出的数据key类型,本案例中就是单词Text * VALUEOUT:Reducer阶段输出的value的数据类型,本案例中就是LongWritable * * Reducer接收所有来自Mapper处理的数据后,按照key的字典进行排序 * <hello,1>,<tom,1>,<hello,1>.... * 排序后 * <hello,1>,<hello,1>..... * 按照key是否相同,作为一组调用reduce方法 * 每一组的value作为一个迭代器传入reduce方法 */ ? public class WCReducer extends Reducer<Text, LongWritable,Text,LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { //定义一个计算器 int count = 0; for (LongWritable value : values) { //Hadoop的基础数据类型提供了get方法,可以直接获取Java的基础数据类型 count+= value.get(); } //Hadoop的基础数据类型构造器可以通过输入Java的基础数据类型来实例化 context.write(key,new LongWritable(count)); } }
main方法
package com.rzp.utils; ? import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; ? ? import java.io.IOException; ? public class WordCount { ? public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //通过Job这个类封装本次MR要执行的任务 Job job = Job.getInstance(new Configuration()); System.setProperty("HADOOP_USER_NAME","root"); ? //指定本次jap的jar包运行的主类 job.setJarByClass(WordCount.class); ? //设置Mapper相关属性 //指定本次的Mapper类 job.setMapperClass(WCMapper.class); //指定Mapper输出的 k,v的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //指定本次执行的数据来源 //默认在hdfs文件系统的根路径下,以后可以通过main输入的args来使用 FileInputFormat.setInputPaths(job,new Path("/words.txt")); ? //设置Reducer相关属性 //指定本次的Reducer类 job.setReducerClass(WCReducer.class); //指定Reducer输出的 k,v的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //指定本次执行最终结果的输出地址 FileOutputFormat.setOutputPath(job,new Path("/wcout")); //job.submit();提交job,但是一般不用 //这个方法会提交并且打印日志 job.waitForCompletion(true); } ? ? }
?把MapReduce程序达成jar包,提交给yarn集群,分发到节点上并发执行。
数据的处理和输出结果都位于HDFS文件系统
生成jar包
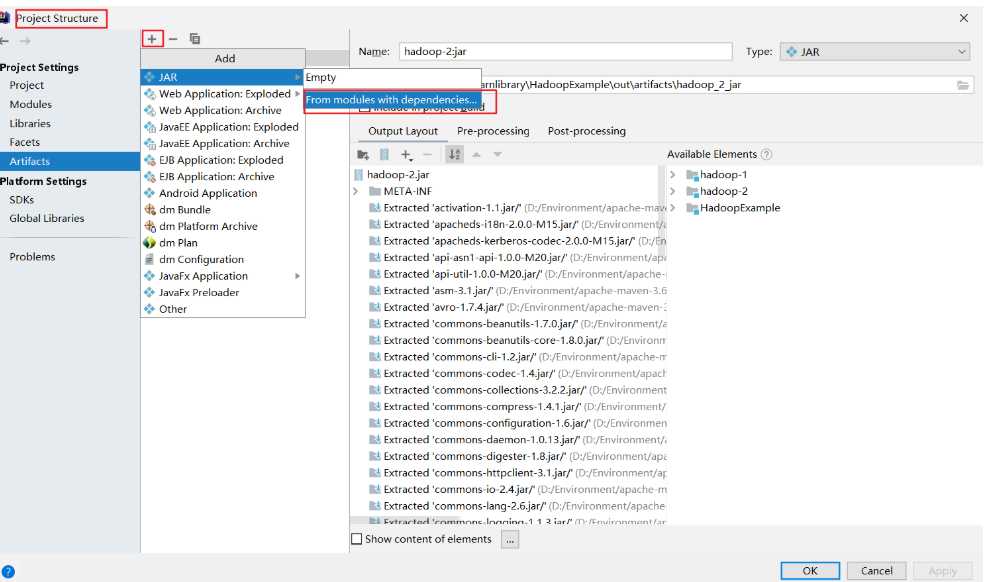
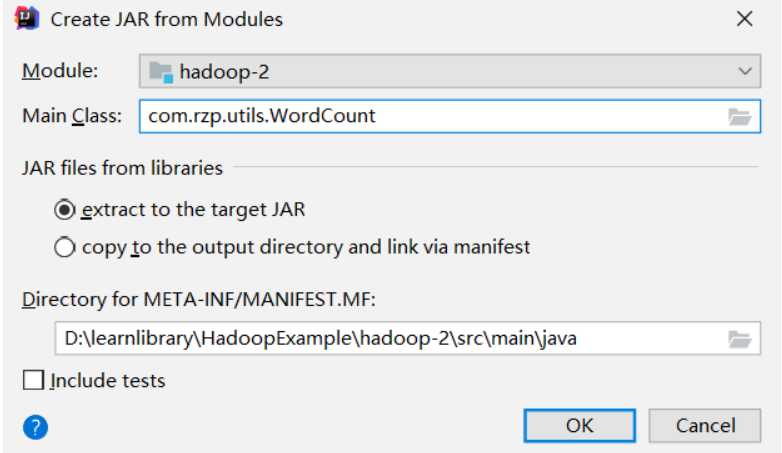
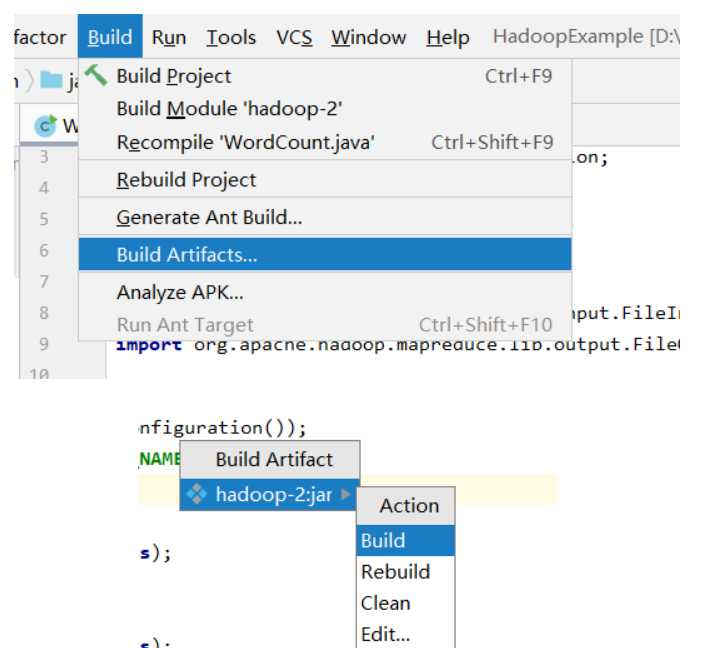
把jar包复制到服务器使用命令执行
hadoop jar xxxx.jar
程序运行情况和日志可以在8088端口查看
MapReduce程序是提交给LocalJobRunner在本地以单进程的形式运行
而处理的数据和输出结果可以在本地文件系统,也可以在HDFS上
要实现本地运行,要写一个程序,不要带集群的配置文件(core-site.xml要删除掉)
并且配置本地执行:
conf.set("mapreduce.framework.name","local");
package com.rzp.utils; ? import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; ? ? import java.io.IOException; ? public class WordCount { ? public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //通过Job这个类封装本次MR要执行的任务 Configuration conf = new Configuration(); conf.set("mapreduce.framework.name","local"); Job job = Job.getInstance(conf); ? System.setProperty("HADOOP_USER_NAME","root"); ? //指定本次jap的jar包运行的主类 job.setJarByClass(WordCount.class); ? //设置Mapper相关属性 //指定本次的Mapper类 job.setMapperClass(WCMapper.class); //指定Mapper输出的 k,v的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //指定本次执行的数据来源 //默认在hdfs文件系统的根路径下,以后可以通过main输入的args来使用 //和远程不同,input要指定到文件名 FileInputFormat.setInputPaths(job,new Path("D:\\Hoptest\\input\\1.txt")); ? //设置Reducer相关属性 //指定本次的Reducer类 job.setReducerClass(WCReducer.class); //指定Reducer输出的 k,v的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //指定本次执行最终结果的输出地址 FileOutputFormat.setOutputPath(job,new Path("D:\\Hoptest\\output")); //job.submit();提交job,但是一般不用 //这个方法会提交并且打印日志 // job.submit(); job.waitForCompletion(true); } ? ? } ?
配置本地的Hadoop库(不需完整安装,但是要有环境支持)
下载文件
https://github.com/speedAngel/hadoop2.7.7
解压到任意路径,没有中文字符和空格
把解压包的bin替换到解压路径
把bin中的Hadoop.dll复制到C:\Windows\System32
配置环境变量
HADOOP_HOME D:\Environment\hadoop-2.7.7 HADOOP_CONF_DIR D:\Environment\hadoop-2.7.7\etc\hadoop YARN_CONF_DIR %HADOOP_CONF_DIR% PATH %HADOOP_HOME%\bin
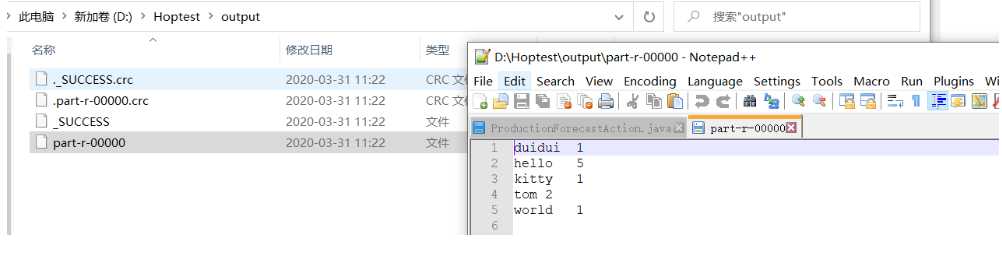
运行测试
l 第一阶段是把输入文件逻辑切片。
默认情况下,Split size = Block size。每一个切片由一个MapTask处理。
l 第二阶段是对切片中的数据解析成<key,value>对。
默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
l 第三阶段是调用Mapper类中的map方法。
上阶段中每解析出来的一个<k,v>,调用一次map方法。每次调用map方法会输出零个或多个键值对。
l 第四阶段是按照Reducer的数量进行分区。
分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务(默认是只有一个区)。
l 第五阶段是对每个分区中的键值对进行排序。
首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。
如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中。
l 第六阶段是对数据进行局部聚合处理(combiner)。
键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
l 第一阶段是Reducer任务会主动从复制Mapper输出的键值对到本地。
Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
l 第二阶段是合并复制后的数据并排序
即把分散的数据合并成一个大的数据。再对合并后的数据排序。
l 第三阶段是调用reduce方法。
键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
Mapper第四阶段,默认是一个分区,但是可以使用以下代码修改分区数量
//分两个区 job.setNumReduceTasks(2);
1个区的Reducer就会生成1个结果文件,比如上面设置成2,就会有2个结果文件。
数据分区的原理是用map输出的key.hashcode对NumReduceTasks取模:
key.hashcode % NumReduceTasks(2)
BooleanWritable ByteWritable DoubleWritable FloatWritable IntWritable LongWritable Text NullWritable ArrayWritable--Writable类型的数组
自定义引用类有以下几个要求:
必须实现Writable接口,用于序列化
如果要作为key使用,或者需要比较数值,需要实现WritableComparable接口
如果使用默认分区类而且有多个reducer的情况下,要实现hashCode和equals方法
一定要给一个无参构造
但是习惯上接口都应该实现
我们把map的数据递交给reduce的时候,很多时候不能只传递1个数值,这个时候我们可以把多个数值封装成一个对象,那么传递的就是这个对象,就可以同时传递多个数值,比如以下需求:
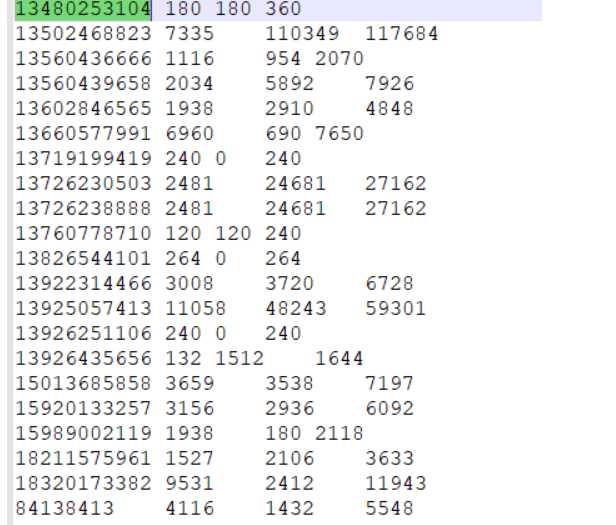
对以下文件,要做一个统计:按照手机号统计上行流量、下行流量和总流量
上行流量:第一行为例,第7个数2481是上行流量,第8个数24681是下行流量
注意第二行没有域名(对应第一行的i02.c.aliimg.com),因此第二行第6个数是上行流量...
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200 1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200 1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200 1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200 1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200 1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200 1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200 1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200 1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200 1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200 1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200 1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200 1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200 1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200 1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200 1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200 1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200 1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200 1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200 1363157985066 13726238888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200 1363157993055 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
map负责收集数据:收集手机号和流量
最终要统计的流量是3个值:上行流量,下行流量,总流量。这个时候我们可以创建一个类,里面存这3个值。
Reduce负责统计。
这个时候就有一个问题:我们在第一个程序中传递的值是类型是Hadoop封装的序列化类型,比如String,我们使用的是Text。
而我们自定义的类如果要传递,也要实现Hadoop的序列化机制。因此引出了MapReduce的序列化机制。
序列化(Serialization)是指把结构化对象转化为字节流。
反序列化(Deserialization)是序列化的逆过程。把字节流转为结构化对象。
Java的序列化包含了很多额外的信息,必须如各种校验信息,header,继承体系(父类的信息也会序列化)
因此Hadoop使用的是自己的序列化机制,只保存需要的信息(键值对)
紧凑
快速
可扩展:继承Hadoop的序列化接口Writable就可以自定义
互操作:支持多种语言
序列化接口Writable
1. public interface Writable {
//序列化方法
2. void write(DataOutput out) throws IOException;
//反序列化方法
3. void readFields(DataInput in) throws IOException;
4. }
?
自定义实体类Flowbean
package com.rzp.pojo; ? import org.apache.hadoop.io.Writable; ? import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; ? ? //继承Hadoop序列化接口 //省略了get/set和有参无参构造器 public class Flowbean implements Writable { private long upFlow;//上行 private long downFlow;//下行 private long sumFlow;//总 ? //重写Writable的序列化方法 public void write(DataOutput out) throws IOException { //使用Hadoop封装的方法把基本数据类型序列化 out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } ? //重写Writable的反序列化方法 public void readFields(DataInput in) throws IOException { //注意反序列化的顺序一定要和序列化一样 this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); ? } ? //自定义构造器 public Flowbean(long upFlow, long downFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow+downFlow; } ? //增加一个同时设置3个属性的方法,免去map方法中set3次,减少代码量 public void set(long upFlow, long downFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow+downFlow; } ? @Override public String toString() { return upFlow+"\t"+downFlow+"\t"+sumFlow+"\t"; } }
Mapper
package com.rzp.flosum; ? import com.rzp.pojo.Flowbean; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; ? import java.io.IOException; ? /** * 在mr程序中,可以把自定义类作为mr的数据类型 * 但是自定义类一定要实现Hadoop序列化接口 */ public class FlowSumMapper extends Mapper<LongWritable, Text,Text, Flowbean> { ? //提高作用域,先new一个出来,重复使用,避免造成大量的内存使用 Text k = new Text(); Flowbean v = new Flowbean(); ? @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); //数据使用制表符分割的 String[] fields = line.split("\t"); String phoneNum = fields[1]; //因为部分数据前面少了一个域名,有些流量是第7位,有些是第6位 //因此我们反过来获取,倒数第3个和倒数第2个 long upFlow = Long.parseLong(fields[fields.length-3]); long downFlow = Long.parseLong(fields[fields.length-2]); ? k.set(phoneNum); v.set(upFlow,downFlow); ? context.write(k,v); ? ? } }
Reducer
package com.rzp.flosum; ? import com.rzp.pojo.Flowbean; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; ? import java.io.IOException; ? public class FlowSumReducer extends Reducer<Text, Flowbean,Text,Flowbean> { ? Flowbean v = new Flowbean(); ? @Override protected void reduce(Text key, Iterable<Flowbean> values, Context context) throws IOException, InterruptedException { long upFlowCount = 0; long downFlowCount = 0; //统计流量 for (Flowbean value : values) { upFlowCount += value.getUpFlow(); downFlowCount += value.getDownFlow(); ? } //写到Flowbean对象中 v.set(upFlowCount,downFlowCount); //输出 context.write(key,v); } } ?
FlowSumDrive,主程序
package com.rzp.flosum; ? import com.rzp.pojo.Flowbean; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; ? import java.io.IOException; ? public class FlowSumDrive { ? public static void main(String[] args) throws Exception { //通过Job这个类封装本次MR要执行的任务 Configuration conf = new Configuration(); conf.set("mapreduce.framework.name","local"); Job job = Job.getInstance(conf); ? System.setProperty("HADOOP_USER_NAME","root"); ? //指定本次jap的jar包运行的主类 job.setJarByClass(FlowSumDrive.class); ? //设置Mapper相关属性 //指定本次的Mapper类 job.setMapperClass(FlowSumMapper.class); //指定Mapper输出的 k,v的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Flowbean.class); //指定本次执行的数据来源 //默认在hdfs文件系统的根路径下,以后可以通过main输入的args来使用 FileInputFormat.setInputPaths(job,new Path("D:\\Hoptest\\flowsum\\input\\1.dat")); ? //设置Reducer相关属性 //指定本次的Reducer类 job.setReducerClass(FlowSumReducer.class); //指定Reducer输出的 k,v的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Flowbean.class); //指定本次执行最终结果的输出地址 FileOutputFormat.setOutputPath(job,new Path("D:\\Hoptest\\flowsum\\output")); ? job.waitForCompletion(true); ? } }
?执行结果
在上一个结果的基础上,要实现按总流量倒序排序的需求。
map输入的内容就是上一个统计的结果。
MapReduce中想要实现排序,就只能是在key上排序,实际上上一个结果可以看到就是按照手机号升序排序的。
MapReduce中对手机号排序的方法其实就是调用了compareTo方法。
因此我们要自定义排序,首先要把Flowbean作为key,并且重写Flowbean的排序方法即可
一定要先排序grouping需要的字段
在Flowbean中加入compareTo的重写
//重写compareTo方法 public int compareTo(Flowbean o) { //o1.compareTo(o2) //o1大于o2的时候,o1取-1排在前面 return this.sumFlow > o.getSumFlow()?-1:1; }
Mapper
package com.rzp.flosum2; import com.rzp.pojo.Flowbean; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; //输出的key要使用Flowbean,而手机号作为value,那么MapReduce就会自动按多态调用子类的compareTo方法 public class FlowSumMapper2 extends Mapper<LongWritable, Text,Flowbean,Text> { Text v = new Text(); Flowbean k = new Flowbean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = line.split("\t"); String phoneNum = fields[0]; long upFlow = Long.parseLong(fields[1]); long downFlow = Long.parseLong(fields[2]); v.set(phoneNum); k.set(upFlow,downFlow); context.write(k,v); } }
Reduce
package com.rzp.flosum2; import com.rzp.pojo.Flowbean; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class FlowSumReducer2 extends Reducer<Flowbean, Text,Text,Flowbean> { @Override protected void reduce(Flowbean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //只有一行数据,只要反过来就可以了 context.write(values.iterator().next(),key); } }
测试类,注意类名修改了,Mapper的输出类型修改了。
package com.rzp.flosum2; import com.rzp.pojo.Flowbean; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowSumDrive2 { public static void main(String[] args) throws Exception { //通过Job这个类封装本次MR要执行的任务 Configuration conf = new Configuration(); conf.set("mapreduce.framework.name","local"); Job job = Job.getInstance(conf); System.setProperty("HADOOP_USER_NAME","root"); //指定本次jap的jar包运行的主类 job.setJarByClass(FlowSumDrive2.class); //设置Mapper相关属性 //指定本次的Mapper类 job.setMapperClass(FlowSumMapper2.class); //指定Mapper输出的 k,v的类型 job.setMapOutputKeyClass(Flowbean.class); job.setMapOutputValueClass(Text.class); //指定本次执行的数据来源 //默认在hdfs文件系统的根路径下,以后可以通过main输入的args来使用 FileInputFormat.setInputPaths(job,new Path("D:\\Hoptest\\flowsum\\output\\part-r-00000")); //设置Reducer相关属性 //指定本次的Reducer类 job.setReducerClass(FlowSumReducer2.class); //指定Reducer输出的 k,v的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Flowbean.class); //指定本次执行最终结果的输出地址 FileOutputFormat.setOutputPath(job,new Path("D:\\Hoptest\\flowsum\\output2")); job.waitForCompletion(true); } }
标签:ret 函数 模型 this 并发 个数 进程 字符 shuf
原文地址:https://www.cnblogs.com/renzhongpei/p/12635209.html