标签:正则 png 因此 pca int 成绩 normal sort ima
学习目标
sklearn中的Pipeline
偏差与方差
模型正则化之L1正则、L2正则
一、sklearn中的Pipeline
研究一个因变量与一个或多个自变量间多项式的回归分析方法,称为多项式回归(Polynomial Regression)。多项式回归是线性回归模型的一种,其回归函数关于回归系数是线性的。其中自变量x和因变量y之间的关系被建模为n次多项式。
如果自变量只有一个时,称为一元多项式回归;如果自变量有多个时,称为多元多项式回归。在一元回归分析中,如果变量y与自变量x的关系为非线性的,但是又找不到适当的函数曲线来拟合,则可以采用一元多项式回归。
由于任一函数都可以用多项式逼近,因此多项式回归有着广泛应用。
多项式回归的思路是:添加一个特征,即对于X中的每个数据进行平方。
import numpy as np import matplotlib.pyplot as plt x = np.random.uniform(-3, 3, size=100) X = x.reshape(-1, 1) y = 0.5 + x**2 + x + 2 + np.random.normal(0, 1, size=100) plt.scatter(x, y) plt.show() from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X, y) y_predict = lin_reg.predict(X) plt.scatter(x, y) plt.plot(x, y_predict, color=‘r‘) plt.show() #添加一个特征值 (X**2).shape # 凭借一个新的数据数据集 X2 = np.hstack([X, X**2]) # 用新的数据集进行线性回归训练 lin_reg2 = LinearRegression() lin_reg2.fit(X2, y) y_predict2 = lin_reg2.predict(X2) plt.scatter(x, y) plt.plot(np.sort(x), y_predict2[np.argsort(x)], color=‘r‘) plt.show() #%%一元多项式回归 #sklearn中的多项式回归 #多项式回归可以看作是对数据进行预处理,给数据添加新的特征,所以调用的库在preprocessing中 from sklearn.preprocessing import PolynomialFeatures poly=PolynomialFeatures(degree=2)# 这个degree表示我们使用多少次幂的多项式 poly.fit(X) X2 = poly.transform(X) X2.shape X2[:5,:] #X2的结果第一列常数项,可以看作是加入了一列x的0次方;第二列一次项系数(原来的样本X特征),第三列二次项系数(X平方前的特征)。 from sklearn.linear_model import LinearRegression reg=LinearRegression() reg.fit(X2,y) y_pre=reg.predict(X2) plt.scatter(x,y) plt.plot(np.sort(x),y_pre[np.argsort(x)],color=‘r‘) plt.show() #argsort函数返回的是数组值从小到大的索引值 reg.coef_ reg.intercept_ #%%多元 import numpy as np X = np.arange(1, 11).reshape(5, 2) # 5行2列 10个元素的矩阵 X.shape from sklearn.preprocessing import PolynomialFeatures poly = PolynomialFeatures() poly.fit(X) # 将X转换成最多包含X二次幂的数据集 X2 = poly.transform(X) # 5行6列 X2.shape X2 poly = PolynomialFeatures(degree=3) poly.fit(X) x3 = poly.transform(X) x3.shape #PolynomiaFeatures,将所有的可能组合,升维的方式呈指数型增长。这也会带来一定的问题。 # ============================================================================= # #在具体编程实践时,可以使用sklearn中的pipeline对操作进行整合。 # 首先我们回顾多项式回归的过程: # 将原始数据通过PolynomialFeatures生成相应的多项式特征 # 多项式数据可能还要进行特征归一化处理 # 将数据送给线性回归 # Pipeline就是将这些步骤都放在一起。参数传入一个列表,列表中的每个元素是管道中的一个步骤。每个元素是一个元组,元组的第一个元素是名字(字符串),第二个元素是实例化。 # # ============================================================================= x = np.random.uniform(-3, 3, size=100) X = x.reshape(-1, 1) y = 0.5 + x**2 + x + 2 + np.random.normal(0, 1, size=100) from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression from sklearn.preprocessing import StandardScaler poly_reg=Pipeline([ (‘poly‘,PolynomialFeatures(degree=2)), (‘std_scale‘,StandardScaler()), (‘lin_reg‘,LinearRegression()) ]) poly_reg.fit(x, y) y_predict = poly_reg.predict(x) plt.scatter(x, y) plt.plot(np.sort(x), y_predict[np.argsort(x)], color=‘r‘) plt.show() y =np.random.normal(0, 1, size=5) # ============================================================================= # 其实多项式回归在算法并没有什么新的地方,完全是使用线性回归的思路, #关键在于为数据添加新的特征,而这些新的特征是原有的特征的多项式组合,采用这样的方式就能解决非线性问题。 # 这样的思路跟PCA这种降维思想刚好相反,而多项式回归则是升维,添加了新的特征之后,使得更好地拟合高维数据。 # =============================================================================
二、偏差与方差
过拟合过拟合和欠拟合都会使训练好的机器学习模型在真实的数据中出现错误。我们可以将错误分为偏差(Bias)和方差(Variance)两类和欠拟合都会使训练好的机器学习模型在真实的数据中出现错误。我们可以将错误分为偏差(Bias)和方差(Variance)两类
偏差(bias):偏差衡量了模型的预测值与实际值之间的偏离关系。例如某模型的准确度为96%,则说明是低偏差;反之,如果准确度只有70%,则说明是高偏差。
方差(variance):方差描述的是训练数据在不同迭代阶段的训练模型中,预测值的变化波动情况(或称之为离散情况)。从数学角度看,可以理解为每个预测值与预测均值差的平方和的再求平均数。通常在模型训练中,初始阶段模型复杂度不高,为低方差;随着训练量加大,模型逐步拟合训练数据,复杂度开始变高,此时方差会逐渐变高。
四种情况
模型误差 = 偏差 + 方差 + 不可避免的误差(噪音)。一般来说,随着模型复杂度的增加,方差会逐渐增大,偏差会逐渐减小,见下图:
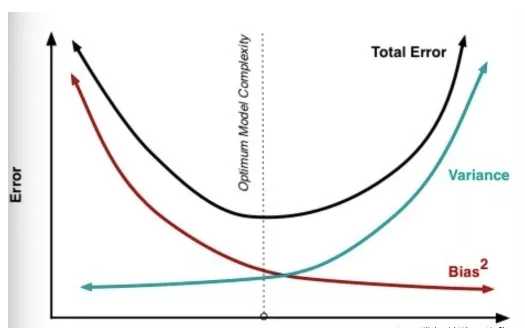
产生原因
一个模型有偏差,主要的原因可能是对问题本身的假设是不正确的,或者欠拟合。如:针对非线性的问题使用线性回归;或者采用的特征和问题完全没有关系,如用学生姓名预测考试成绩,就会导致高偏差。
方差表现为数据的一点点扰动就会较大地影响模型。即模型没有完全学习到问题的本质,而学习到很多噪音。通常原因可能是使用的模型太复杂,如:使用高阶多项式回归,也就是过拟合。
有一些算法天生就是高方差的算法,如kNN算法。非参数学习算法通常都是高方差,因为不对数据进行任何假设。
有一些算法天生就是高偏差算法,如线性回归。参数学习算法通常都是高偏差算法,因为对数据有迹象。
权衡
偏差和方差通常是矛盾的。降低偏差,会提高方差;降低方差,会提高偏差。
这就需要在偏差和方差之间保持一个平衡。
以多项式回归模型为例,我们可以选择不同的多项式的次数,来观察多项式次数对模型偏差&方差的影响
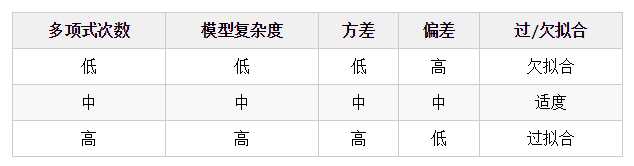
我们要知道偏差和方差是无法完全避免的,只能尽量减少其影响。
其实在机器学习领域,主要的挑战来自方差。处理高方差的手段有:
参数或者线性的算法一般是高偏差低方差;非参数或者非线性的算法一般是低偏差高方差。所以我们需要调整参数来去衡量方差和偏差的关系
三、模型正则化之L1正则、L2正则
模型正则化(Regularization),对学习算法的修改,限制参数的大小,减少泛化误差而不是训练误差。我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当你用比较复杂的模型比如神经网络,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。
正则化的策略包括:约束和惩罚被设计为编码特定类型的先验知识 偏好简单模型 其他形式的正则化,如:集成的方法,即结合多个假说解释训练数据
在实践中,过于复杂的模型不一定包含数据的真实的生成过程,甚至也不包括近似过程,这意味着控制模型的复杂程度不是一个很好的方法,或者说不能很好的找到合适的模型的方法。实践中发现的最好的拟合模型通常是一个适当正则化的大型模型。
所谓的L1正则化,就是在目标函数中加了L1范数这一项。使用L1正则化的模型叫做LASSO回归。

在这里有几个细节需要注意:
,取值范围是1~n,即不包含。这是因为,不是任何一个参数的系数,是截距。反映到图形上就是反映了曲线的高低,而不决定曲线每一部分的陡峭与缓和。所以模型正则化时不需要。
对于超参数\alpha系数,在模型正则化的新的损失函数中,要让每个都尽可能小的程度占整个优化损失函数程度的多少。即\alpha的大小表示优化的侧重
我们说,LASSO回归的全称是:Least Absolute Shrinkage and Selection OperatorRegression.
这里面有一个特征选择的部分,或者说L1正则化可以使得参数稀疏化,即得到的参数是一个稀疏矩阵。
稀疏模型,很多参数是0,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,即使去掉对模型也没有什么影响,此时我们就可以只关注系数是非零值的特征。
这相当于对模型进行了一次特征选择,只留下一些比较重要的特征,提高模型的泛化能力,降低过拟合的可能。
由此可见:加入L1正则项相当于倾向将参数向离原点近的方向去压缩。直观上来说,就是加上正则项,参数空间会被缩小,意味着模型的复杂度会变小。
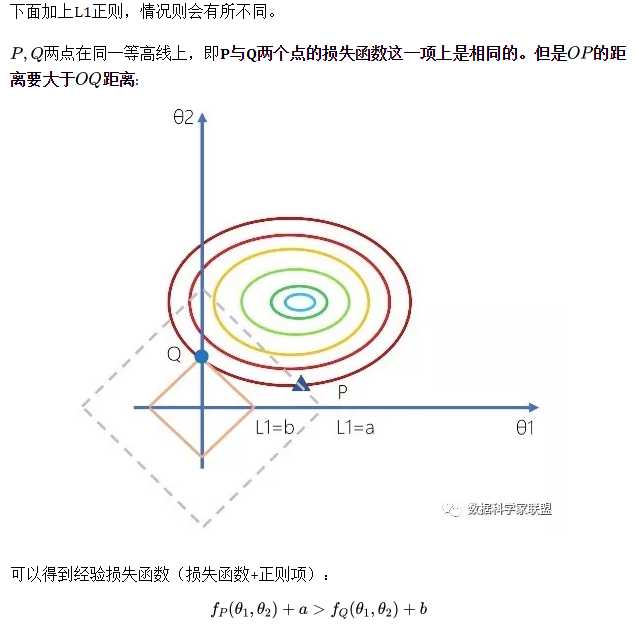

我们利用第一节得到的数据来对比使用LASSO回归进行正则化的方式。
在sklearn中,包含了一个方法:Lasso。下面我们以Pipeline的方式去封装一个LASSO回归的过程:
#%%lasso import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import PolynomialFeatures from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split x = np.random.uniform(-3, 3, size=100) X = x.reshape(-1, 1) y = 0.5 + x**2 + x + 2 + np.random.normal(0, 1, size=100) plt.scatter(x, y) np.random.seed(666) #过拟合 lin_reg = LinearRegression() def PolynomialRegression(degree): return Pipeline([ (‘poly‘,PolynomialFeatures(degree)), (‘std_scaler‘,StandardScaler()), (‘lin_reg‘,lin_reg) ]) np.random.seed(666) X_train, X_test, y_train, y_test = train_test_split(X,y) poly30_reg = PolynomialRegression(degree=30) poly30_reg.fit(X_train,y_train) y30_predict = poly30_reg.predict(X_test) mean_squared_error(y_test,y30_predict) X_plot = np.linspace(-3,3,100).reshape(100,1) y_plot = poly30_reg.predict(X_plot) plt.scatter(X,y) plt.plot(X_plot[:,0],y_plot,color=‘r‘) plt.axis([-3,3,0,10]) plt.show() #lasso from sklearn.linear_model import Lasso def LassoRegression(degree,alpha): return Pipeline([ (‘poly‘,PolynomialFeatures(degree=degree)), (‘std_scaler‘,StandardScaler()), (‘lasso_reg‘,Lasso(alpha=alpha)) ]) #调参 lasso_reg1 = LassoRegression(30,0.0001) lasso_reg1.fit(X_train,y_train) y1_predict=lasso_reg1.predict(X_test) mean_squared_error(y_test,y1_predict) lasso_reg3 = LassoRegression(30,10) #放大alpha后的模型线更加平了,则alpha的选取也很重要 lasso_reg3.fit(X_train,y_train) y3_predict=lasso_reg3.predict(X_test) mean_squared_error(y_test,y3_predict) #%%岭回归

from sklearn.linear_model import Ridge from sklearn.pipeline import Pipeline # 需要传入一个多项式项数的参数degree以及一个alpha值 def ridgeregression(degree,alpha): return Pipeline([ ("poly", PolynomialFeatures(degree=degree)), ("standard", StandardScaler()), ("ridge_reg", Ridge(alpha=alpha)) #alpha值就是正则化那一项的系数 ]) ridge1_reg = ridgeregression(degree=30,alpha=0.0001) ridge1_reg.fit(X_train,y_train) y1_predict = ridge1_reg.predict(X_test) mean_squared_error(y_test,y1_predict) #如果我们调整系数,将其变大,意味着对参数的约束又变强了,曲线会更加光滑 ridge2_reg = ridgeregression(degree=30,alpha=1) ridge2_reg.fit(X_train,y_train) y2_predict = ridge2_reg.predict(X_test) mean_squared_error(y_test,y2_predict)
可见LASSO回归和岭回归类似,alpha取值过大反而会导致误差增加,拟合曲线为直线。但是LASSO更趋向于使得一部分theta的值为0,拟合曲线更趋向于直线,所以可以作为特征选择来使用,去除一些模型认为不需要的特征。LASSO可能会去除掉正确的特征,从而降低准确度,但如果特征特别大,使用LASSO可以使模型变小。
总结
L1正则化就是在损失函数后边所加正则项为L1范数,加上L1范数容易得到稀疏解(0比较多),一般来说L1正则化较常使用。
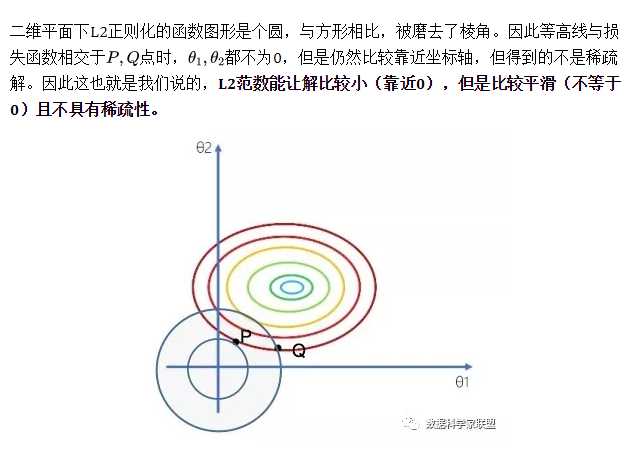
L2正则化就是损失后边所加正则项为L2范数,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于0(但不是等于0,所以相对平滑)的维度比较多,降低模型的复杂度。
标签:正则 png 因此 pca int 成绩 normal sort ima
原文地址:https://www.cnblogs.com/wjAllison/p/12636673.html