标签:lib pat rup 聚合 override ORC 操作 gif 单表
要解决什么问题?
解决的都是同一个问题,即将两张“表‘进行join操作。
reduce join是在map阶段完成数据的标记,在reduce阶段完成数据的合并
map join是直接在map阶段完成数据的合并,没有reduce阶段
比如有如下问题:
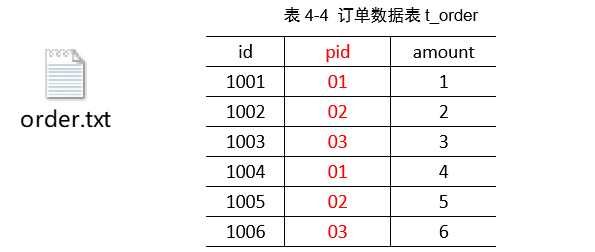
这是订单表。
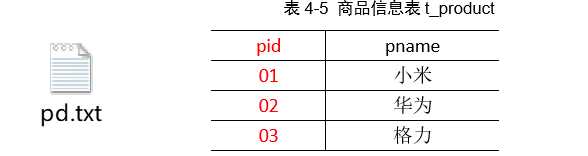
这是商品表。
现在需要将商品表中的商品名称填充到订单表中。得到如下的联合表:
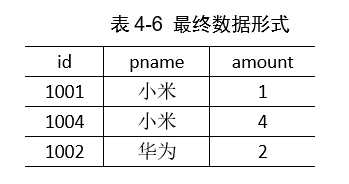
也就是对商品表和订单表根据pid进行join操作,同时剔除联合表中的pid属性。
Reduce Join
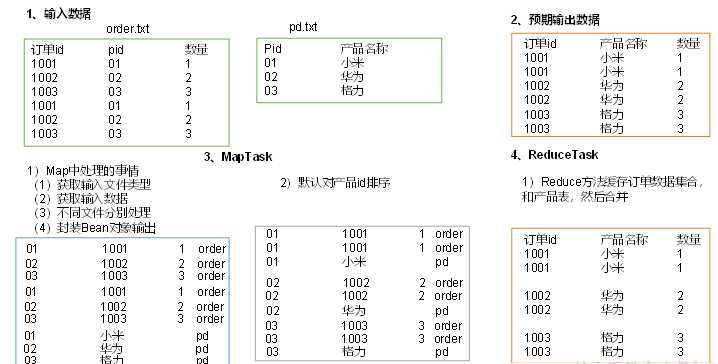
map:
将输入数据统一封装为一个Bean,此Bean包含了商品表和订单表的所有公共和非公共属性,相当于进行了全外连接,并新增加一个属性——文件名称,以区分数据是来自与商品表还是订单表;map输出的key是pid,value是bean
shuffle:
根据pid对bean进行排序,所有pid相同的数据都会被聚合到同一个key下,发往同一个reducetask
reduce:
对同一个pid下所有的bean,首先要区分出它们是来自于哪个表,是商品表还是订单表。如果是商品表,数据只有一条,保存其中的pname属性;如果是订单表,数据有多条,用保存的pname属性替换pid属性,并输出
map join
没有reduce过程,所有的工作都在map阶段完成,极大减少了网络传输和io的代价。如何实现:
上述的join过程可以看作外表与内表的连接过程,外表是订单表,外表大,内表是商品表,内表小。所以可以把内表事先缓存于各个maptask结点,然后等到外表的数据传输过来以后,直接用外表的数据连接内表的数据并输出即可

1)在driver中设置加载缓存文件,这样每个maptask就可以获取到该文件;设置reducetask个数为0,去除reduce阶段
2)在setup方法中读取缓存文件,并将结果以kv的形式存入hashmap,k是pid,v是pname
3)在map方法中,根据pid,通过hashmap找到pname,替换pid,写出结果;
完整的示例代码如下:
mapper
package mapjoin; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.util.HashMap; import java.util.Map; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MapJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> { private Map<String,String> produs = new HashMap<>(); Text text = new Text(); @Override protected void setup(Context context) throws IOException, InterruptedException { //获取缓存文件的输入流 URI[] uris=context.getCacheFiles(); String path=uris[0].getPath().toString(); BufferedReader br=new BufferedReader(new InputStreamReader(new FileInputStream(path),"UTF-8")); //将小表中的数据,封装进HashMap中 String line = null; while(StringUtils.isNotEmpty((line=br.readLine()))) { String[] fields = line.split("\t"); produs.put(fields[0], fields[1]); } } @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //这里的记录,只来源于order表,也就是大表,直接切割并封装 String[] fields = value.toString().split("\t"); String pname = produs.get(fields[1]); pname = (pname==null)?"":pname; String s = fields[0]+"\t"+pname+"\t"+fields[2]; text.set(s); context.write(text, NullWritable.get()); } }
driver
package mapjoin; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MapJoinDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException { // TODO Auto-generated method stub // 0 根据自己电脑路径重新配置 args = new String[]{"e:/input/table/order.txt", "e:/output/table2"}; // 1 获取job信息 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2 设置加载jar包路径 job.setJarByClass(MapJoinDriver.class); // 3 关联map job.setMapperClass(MapJoinMapper.class); // 4 设置最终输出数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 5 设置输入输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 加载缓存数据 job.addCacheFile(new URI("file:///e:/input/inputcache/pro.txt")); // 7 Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0 job.setNumReduceTasks(0); // 8 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }

标签:lib pat rup 聚合 override ORC 操作 gif 单表
原文地址:https://www.cnblogs.com/chxyshaodiao/p/12636768.html