标签:页面 地址 html ado 文章 host requests ref zha
本次爬取使用了代理IP,爬取全站为1个小时,当然也可以不用代理proxy,但是要设置爬取速度 time.sleep(5)
先附上完整代码,下面有详解
import csv
from fake_useragent import UserAgent
import json
from lxml import etree
import requests
# 代理服务器
proxyHost = "http-dyn.abuyun.com"
proxyPort = "9020"
# 代理隧道验证信息
proxyUser = "HM89Z6WLA4F6N05D"
proxyPass = "C8CF37D06DBED9DB"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host": proxyHost,
"port": proxyPort,
"user": proxyUser,
"pass": proxyPass,
}
proxies = {
"http": proxyMeta,
"https": proxyMeta,
}
headers = {"User-Agent": ‘{}‘.format(UserAgent().random),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-us",
"Connection": "keep-alive",
"Accept-Charset": "GB2312,utf-8;q=0.7,*;q=0.7"}
#-------- 获取 游戏名称 和 url ------------#
directory_url = ‘https://www.douyu.com/directory‘
Web = requests.get(directory_url, headers=headers, proxies=proxies).text
dom = etree.HTML(Web)
Game_urls_list = []
Game_names_list = []
for i in range(3, 13):
Game_names = dom.xpath(‘//*[@id="allCate"]/section/div[{}]/ul/li/a/strong/text()‘.format(i))
Game_urls = dom.xpath(‘//*[@id="allCate"]/section/div[{}]/ul/li/a/@href‘.format(i))
#--------------游戏名和游戏url放入新的列表,并分割游戏url(后面会用到)----------#
for Gn in Game_names:
Game_names_list.append(Gn)
for Gu in Game_urls:
G_url = Gu.split(‘_‘)[1]
Game_urls_list.append(G_url)
#----------把名字和url存入字典------------#
All_game = dict(zip(Game_names_list, Game_urls_list))
#----------依次取出字典的 key 循环----------#
for G_name in All_game.keys():
print("===========正在爬取========", G_name)
count = 1 # 因为不同游戏分区,爬取页数不一样,用count计数做一个灵活的爬取办法
for page in range(1, 350): #观察得一个游戏最多不会超过350页
# time.sleep(5)
base_api = ‘https://m.douyu.com/api/room/list?page={}&type={}‘.format(page, All_game[‘{}‘.format(G_name)])
try:
response = requests.get(base_api, headers=headers, proxies=proxies, timeout=30, verify=False).text
except IOError:
pass
RoomList = json.loads(response).get(‘data‘).get(‘list‘)
if len(RoomList) > 1:
# 本页api有数据,count+1
count += 1
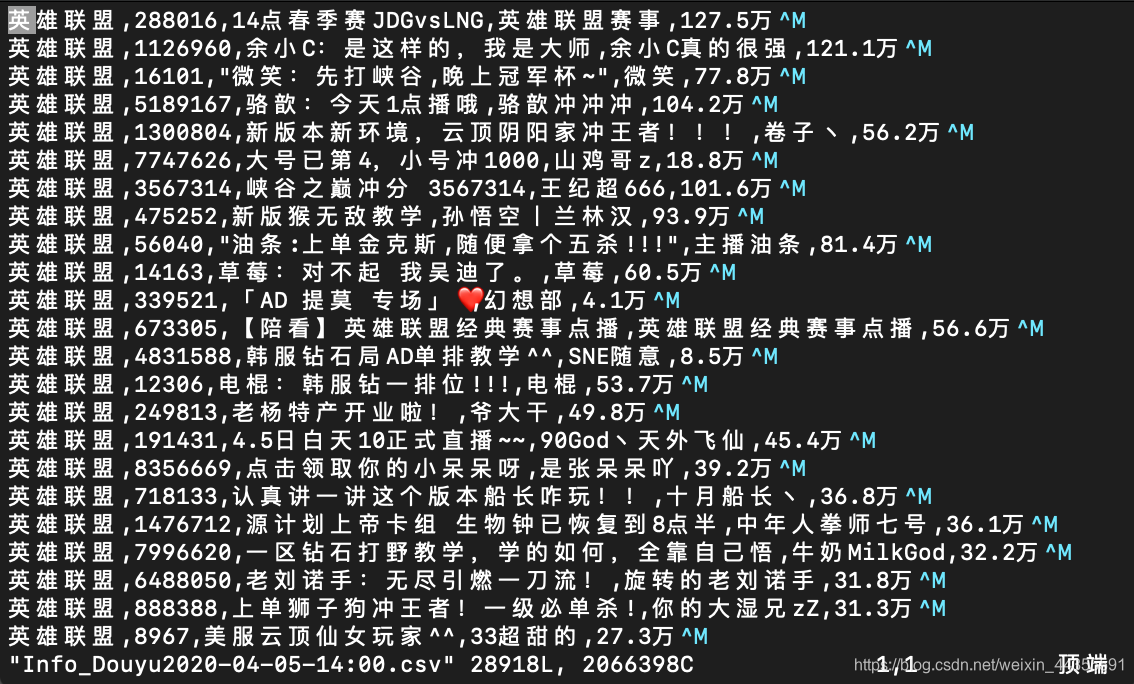
path = ‘/home/liuyang/Spider/Scrapy_Project/BS_Spider/Douyu/Info_Douyu2020-04-05-14:00.csv‘
for room in RoomList:
GameName = G_name
RoomId = room.get(‘rid‘)
RoomName = room.get(‘roomName‘)
BlogName = room.get(‘nickname‘)
HotSpots = room.get(‘hn‘)
with open(path, "a+", encoding=‘utf-8-sig‘) as f:
writer = csv.writer(f, dialect="excel")
csv_write = csv.writer(f)
csv_data = [G_name, RoomId, RoomName, BlogName, HotSpots]
csv_write.writerow(csv_data)
f.close()
print(G_name, RoomId, RoomName, BlogName, HotSpots)
else:
count -= 10
# 本页没有数据,count减去10,
# 因为前面只要有数据 count就会 +1,如果page=1 那么 count=2 ,page=2 则count=3......
# 一旦有一页(最后一页)没有数据,那么count -10 ,满足conut<page 则 break,就说明这个游戏所有页数全部爬取完了,开始爬取下一个游戏
print(count, page)
if count < page:
# 因为有的游戏只有 10多页 而有的游戏有350多页,所以没必要对一个10多页游戏的api重复请求350次
break
如果需要IP代理的话推荐阿布云,可以按小时计算 1h 1块钱,毕竟家境贫寒,代理IP可以看看一看这片文章https://zhuanlan.zhihu.com/p/36207770
我们是先把各个游戏的名称和url爬取下来并存入字典,然后再依次取出字典进入各个游戏分区对所有直播间进行爬取
先从斗鱼的分类地址获取所有游戏:https://www.douyu.com/directory
directory_url = ‘https://www.douyu.com/directory‘
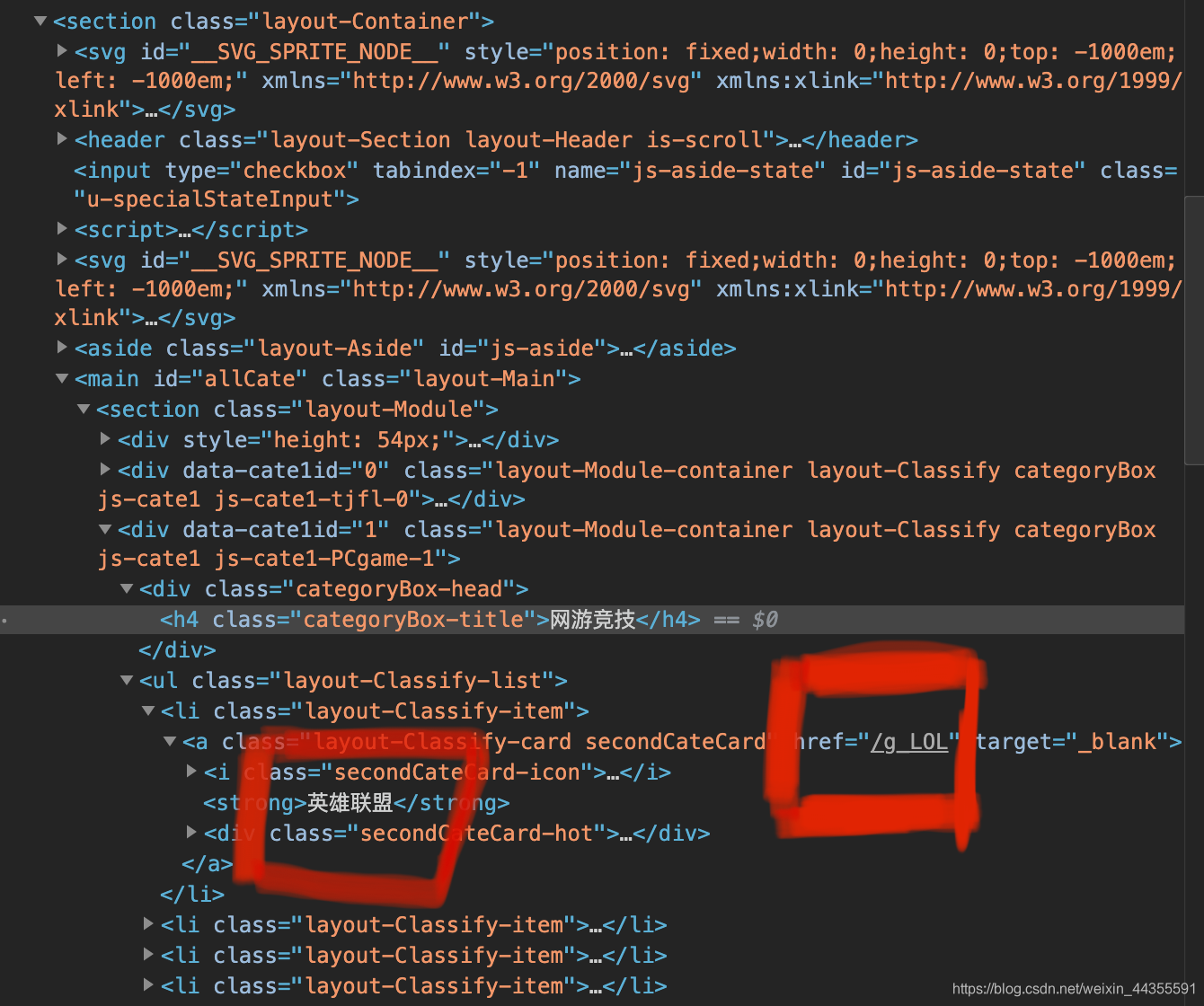
获取一个游戏所有直播数据:
先从斗鱼的分类地址:https://www.douyu.com/directory,中点开一个游戏,就LOL了

点进去后,不用进入直播间,我们直接从api接口获取数据,比如LOL第1页的API链接就是:https://m.douyu.com/api/room/list?page=1{}&type=LOL
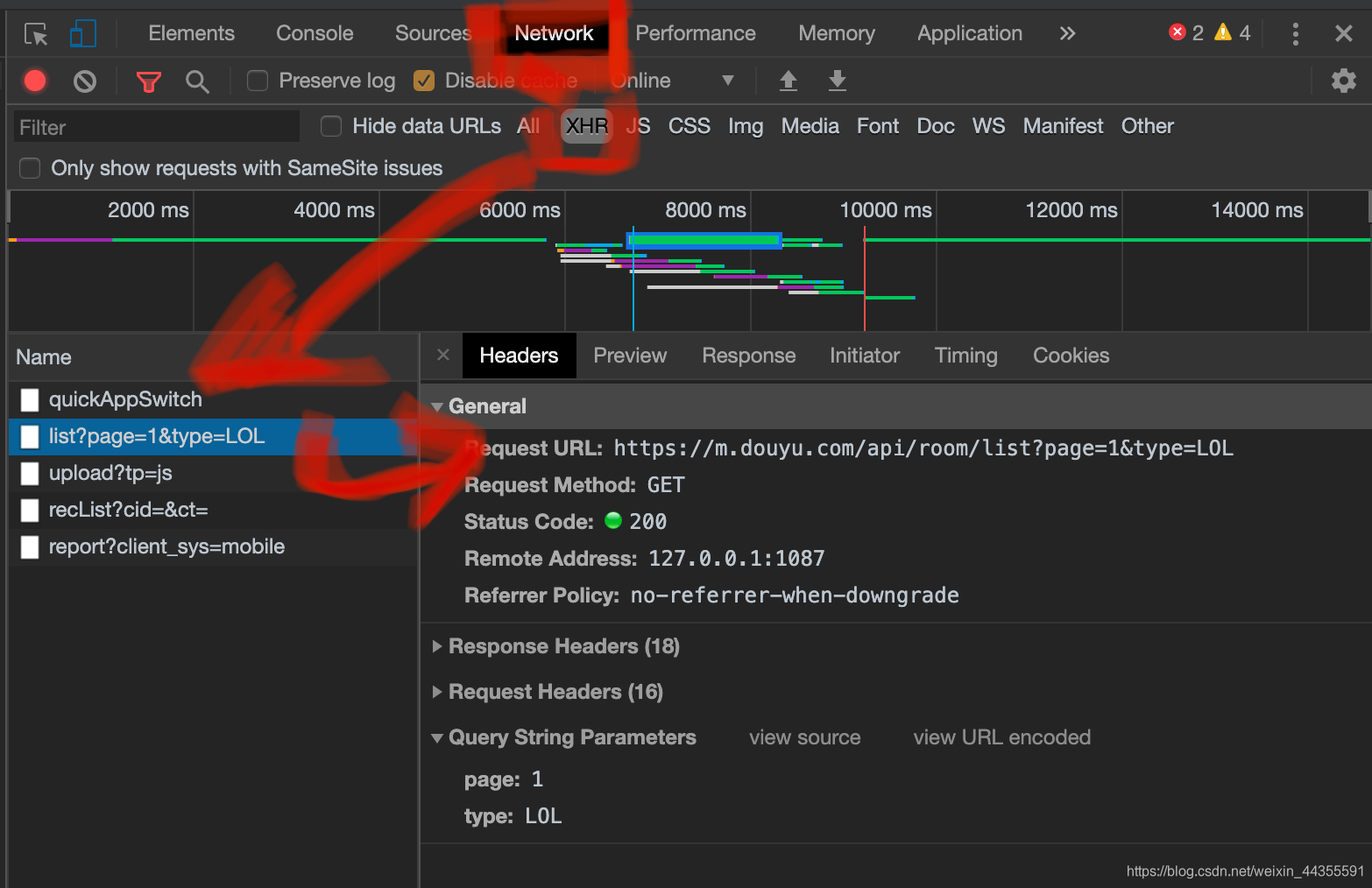
API 页面是这样的

Over!
最后欢迎访问我的个人博客:wangwanghub.com
郑重声明:本项目及所有相关文章,仅用于经验技术交流,禁止将相关技术应用到不正当途径,因为滥用技术产生的风险与本人无关。
标签:页面 地址 html ado 文章 host requests ref zha
原文地址:https://www.cnblogs.com/wangwanghub/p/12638690.html