标签:机器学习 产生 png http 例子 inf 标签 处理 就会
一. 什么是机器学习
机器学习是从人工智能中产生的一个重要学科分支,是实现智能化的关键。
机器学习是一门多领域的交叉学科,设计概率论,统计学,逼近论,凸分析,算法复杂度理论等多门学科,专门研究计算机怎样模拟或实现人类的学习行为,以获取新知识或技能,重新组织已有的知识结构使之不断改善自身的性能。 ——百度百科
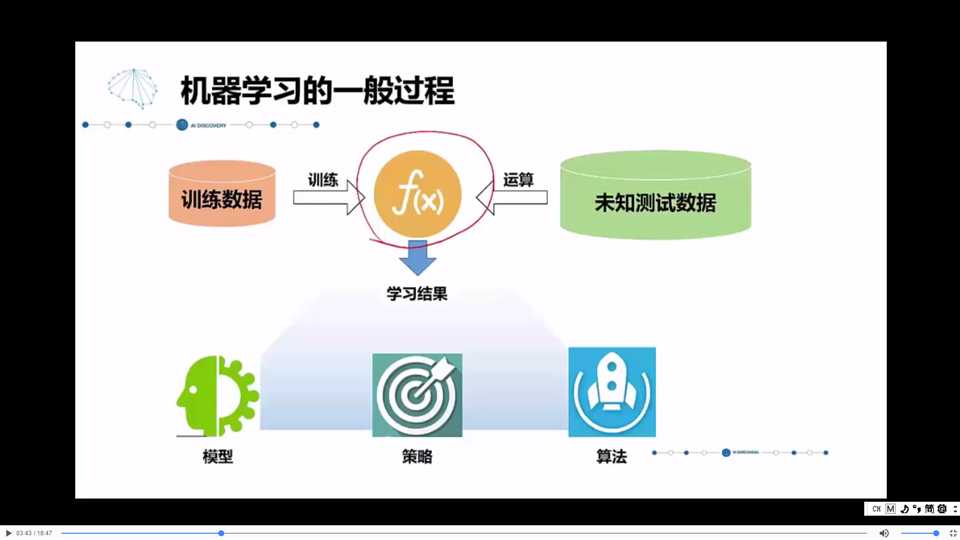
二. 发展历程

三. 机器学习方法
1. 有监督学习

有监督学习分为分类和回归。
分类形象地说就像是做考试的选择题,在训练集中满足这个条件的一堆,满足那个条件的一堆.....,最后根据你给出的测试集的条件判断它是属于哪一堆;
回归形象地说就像是做考试的填空题,根据训练集里给出的数据来大致模拟出一个函数模型,最后将给的测试集数据代入来推测答案。
2. 无监督学习
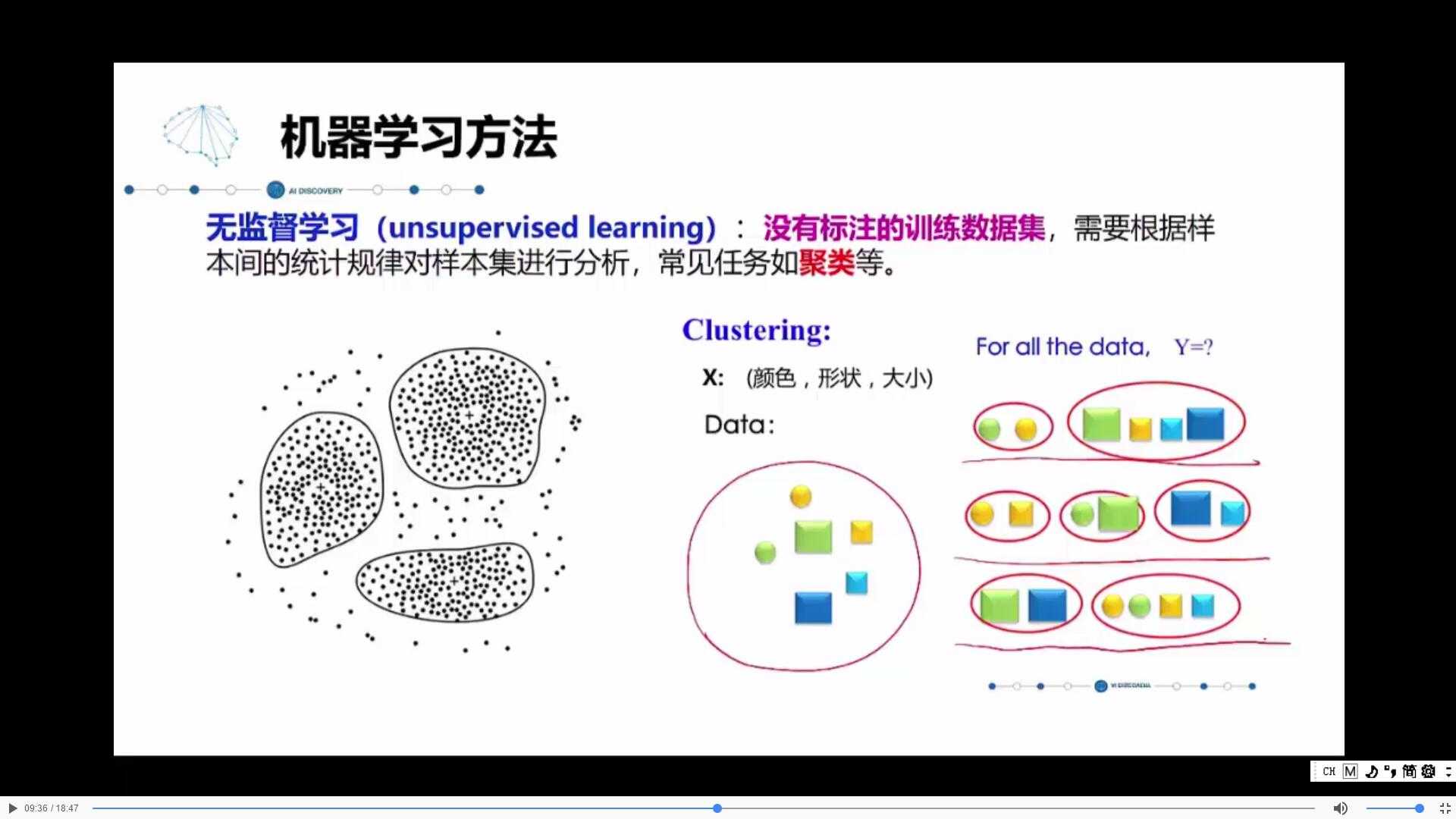
无监督学习分为聚类等。
无监督学习就没有固定的答案和方法,说白了就是找规律,只要你言之有理就行。例如上面的例子,将训练集进行找规律分类,既可以把“玩具”按照形状分,也可以按照颜色分,也可以按照大小分,只要有共同点就行。
3. 半监督学习
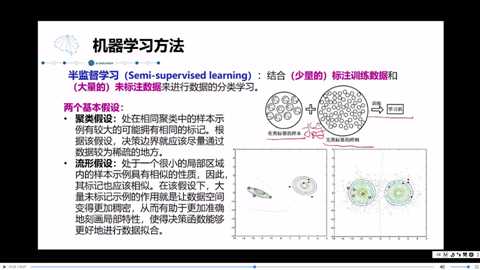
半监督学习:是把监督和无监督结合,因为生活中监督学习比较少,所以使用两者结合。
将无类标签的简单聚类分:按形状,按大小,按颜色....;由有类标签来确定到底是需要按形的,还是按色的...
聚类假设和流行假设的区别:聚类假设是处理处在相同聚类中的样本,而流行假设处理的是小的局部区域。数据越多拟合起来越真实。
4. 增强学习和多任务学习
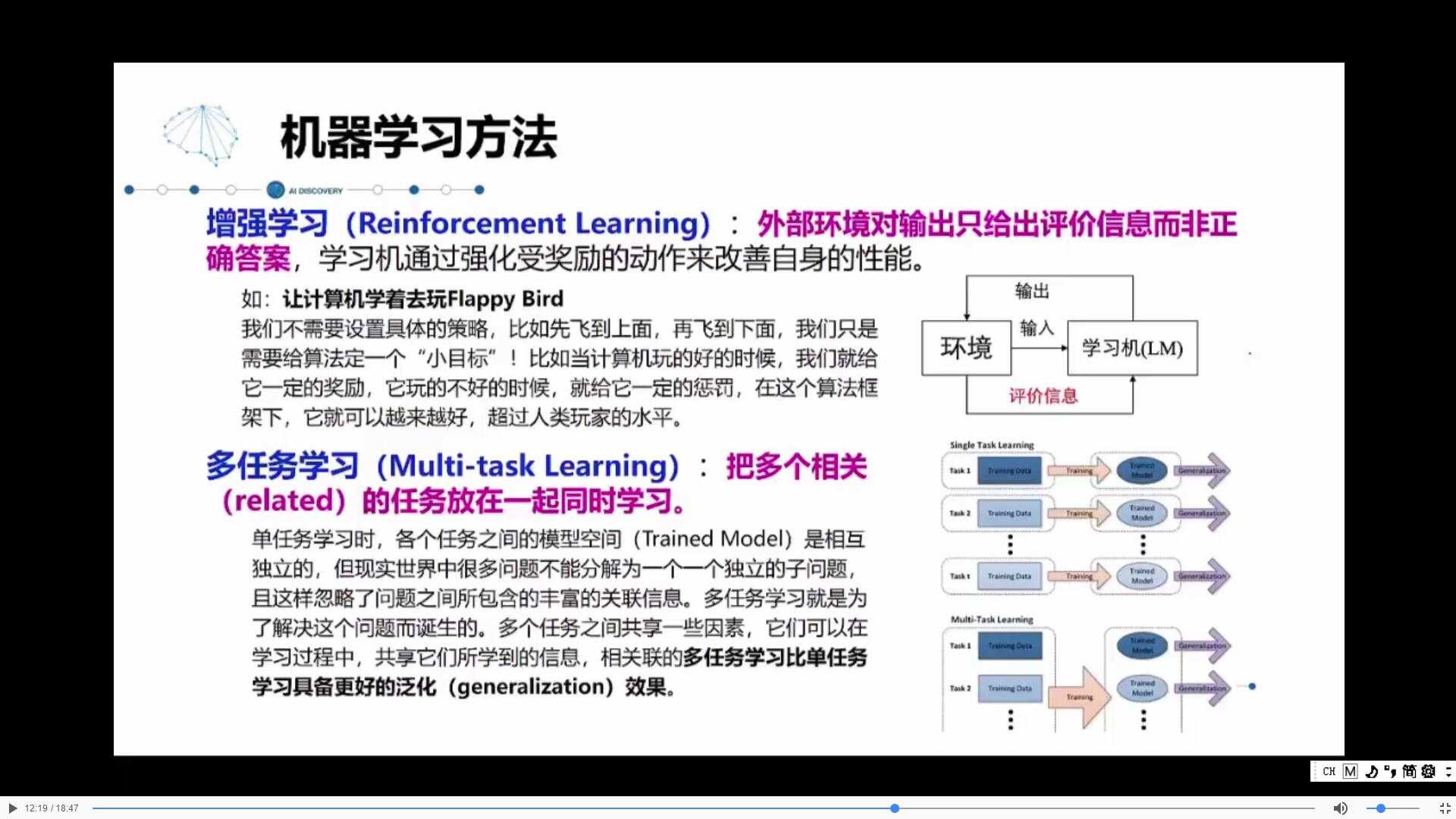
增强学习:就像养猫,我们不告诉猫对错,只是对他的行为进行“奖惩”,慢慢的他自己就会学习来增强性能。
多任务学习:有的问题可以独立解决,但实际上很多问题是不能独立解决的,他们之间是有关系的,而多任务学习的出现就使有关联的任务之间可以共享信息。
标签:机器学习 产生 png http 例子 inf 标签 处理 就会
原文地址:https://www.cnblogs.com/guojiaxue/p/12638668.html