标签:scale 蓝色 排序 分支 sam hash 分布 因此 通过
GridWorld这个例子比较有意思,它还是运用了Reinforcement Learning来进行学习的,不同的是它运用了视觉观察值(Visual Observations)来训练agent。
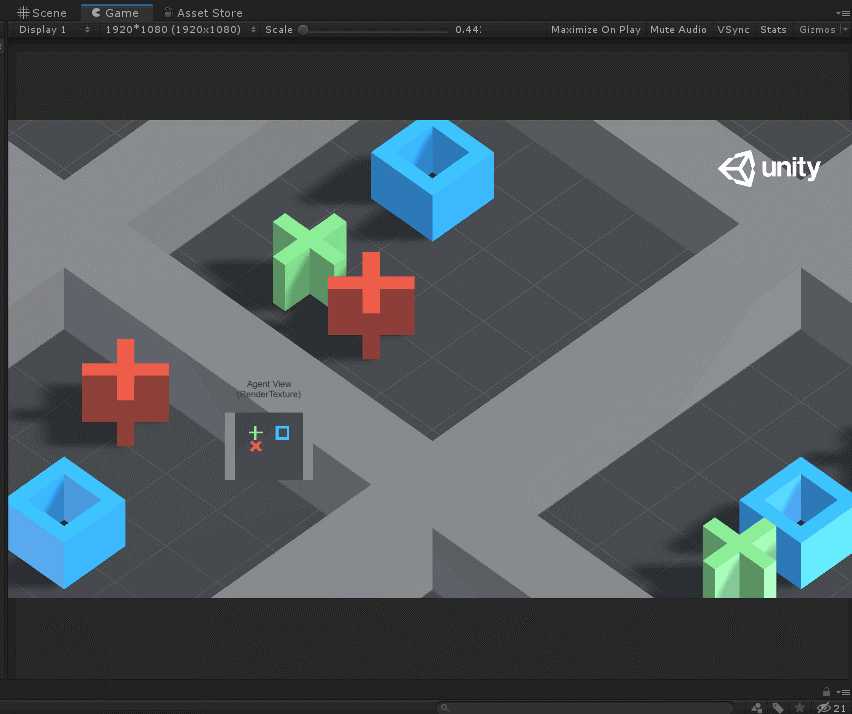
如上图所示,Agent就是蓝色的方块,每次它可以移动一格(上、下、左、右),要求不能碰到红叉,最终到达绿色加号目标。
先来了解一下视觉观察值是怎么回事。在ml-agents里主要通过CameraSensor或RenderTextureSensor两种方式来向Agent提供视觉观察。通过这两个组件收集的图像信息输入到agent policy的CNN(卷积神经网络)中,这使得agent可以从观察图像的图像规律中学习。Agent可以同时使用视觉观察值( Visual Observations)和矢量观察值( Vector Observations)。
使用视觉观察可以使得Agent可以捕获任意复杂的状态,并且在难以用数字描述的状态时非常有用。当然,视觉观察训练相比矢量观察训练,效率低、速度慢,而且有时完全不能成功。因此,只有当使用vector observations或者ray-cast observations(之后会研究到,是射线观察)不能解决问题时,才使用visual observations。
视觉观察结果可以从场景中的Cameras或者RenderTextures获得。为了给agent添加视觉观察组件,需要在agent上添加Camera Sensor Component或者Render Texture Sensor Component组件,然后将Camera或者RenderTexture拖入相应的地方(如下图)。同时给一个Agent可以加一个以上的camera或者render texture组件,甚至可以两种组件进行组合。对于每个视觉观察组件,需要设置图像的宽度和高度(以像素为单位),以及观察值是彩色还是灰色。
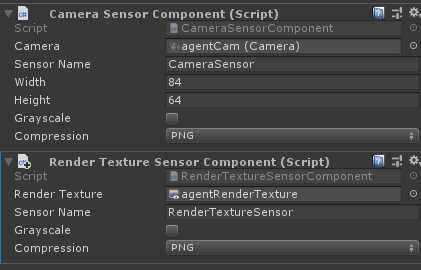
使用相同策略的Agent必须有相同数量的visual observations,并且这些视觉组件需要有相同的分辨率(包括灰度设置)。另外,在Agent的Sensor Component必须有自己单独的Sensor Name以便可以确定地对其排序(名称对于该Agent必须是唯一的,但是多个Agent可以具有同名的Sensor组件)。
当使用Render Texture Sensor Component组件时,可以利用Canvas来调试,需要将在Canvas下建立带有Raw Image组件的物体,然后将Agent的RenderTexture设置到Raw Image的Texture中,例如下图。
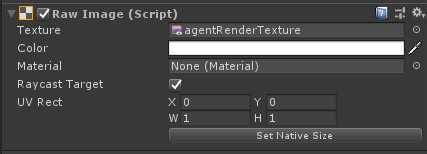
Grid World示例则是展示了怎样去使用RenderTexture组件去调试和观察。注意,在此示例中,将Camera渲染为RenderTexture,然后将其用于观察和调试。为了更新RenderTexture,Camera必须在代码中要求每次做出决定时,都需要进行画面渲染。当直接使用Camera作为观察值时,Agent会自动完成此操作。
CameraSensor组件或RenderTextureSensor组件Greyscale(灰度图)除了Visual Observation,在这个示例中还使用了action mask。下面也先来介绍一下这个概念。
当我们使用离散动作反馈(Discrete Actions)时,可以指定某些动作对于下一决策是不可能发生的。即当Agent被神经网络控制时,agent将无法执行指定的操作。注意,当agent被人为控制时(Heuristic Type),agent仍然能够决定执行被屏蔽的操作。为了屏蔽某些动作,需要在Agent脚本中重写Agent.CollectDiscreteActionMasks()虚函数,同时需要在函数中调用DiscreteActionMasker.SetMask(),如下图
public override void CollectDiscreteActionMasks(DiscreteActionMasker actionMasker){
actionMasker.SetMask(branch, actionIndices)
}
其中:
branch:你想屏蔽操作分支的索引(从0开始)actionIndices:对应于agent无法执行操作的索引相对应的int列表上面的branch就是Behviour Parameters组件中Vector Action中Branches Sizes属性。
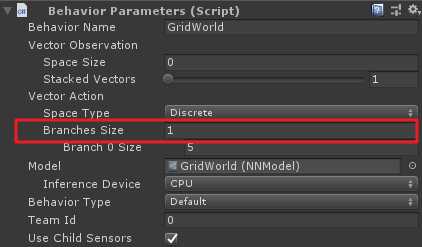
例如,如果一个Agent有两个branch,第一个branch(branch 0)有四个动作枚举:"do nothing", "jump", "shoot" and "change weapon",分别对应索引值0,1,2,3。如果Agent需要在shoot时不可以jump且change weapon,则代码如下:
public override void CollectDiscreteActionMasks(DiscreteActionMasker actionMasker){
if(agent.action==3) //伪代码,意思是当agent动作为shoot时
actionMasker.SetMask(0, new int[2]{1,3}); //重点是这句
}
Notes:
Set Mask多次Continuous Type 中的连续动作OK,有以上基础,下面就来研究一下Grid World示例。
先来根据官方文档参数翻译一下项目参数:
设定:场景包含代理、目标和障碍
目标:agent必须在找到目标的同时,避开障碍
Agent:环境中包含九个具有相同行为参数的Agent
Agent奖励设定
行为参数
Discrete类型)Size为4,对应代理上下左右四个方向运动。此外,在环境中,默认情况下会启动动作遮罩(action masking,可以在对应组件上进行勾选开启或关闭)。源工程中提供的训练模型是在启动屏蔽的情况下生成的。这里利用action mask其实就是限制蓝色方块代理不要走出grid的范围,后面看代码就知道了。泛化参数:gridSize,障碍物数量(numObstacles)和目标数量(numGoals)三个。具体关于泛化的解释请查看之前的文章
基准平均奖励:0.8
以一个基本的Agent为单位,先看一下在Scene视图中:
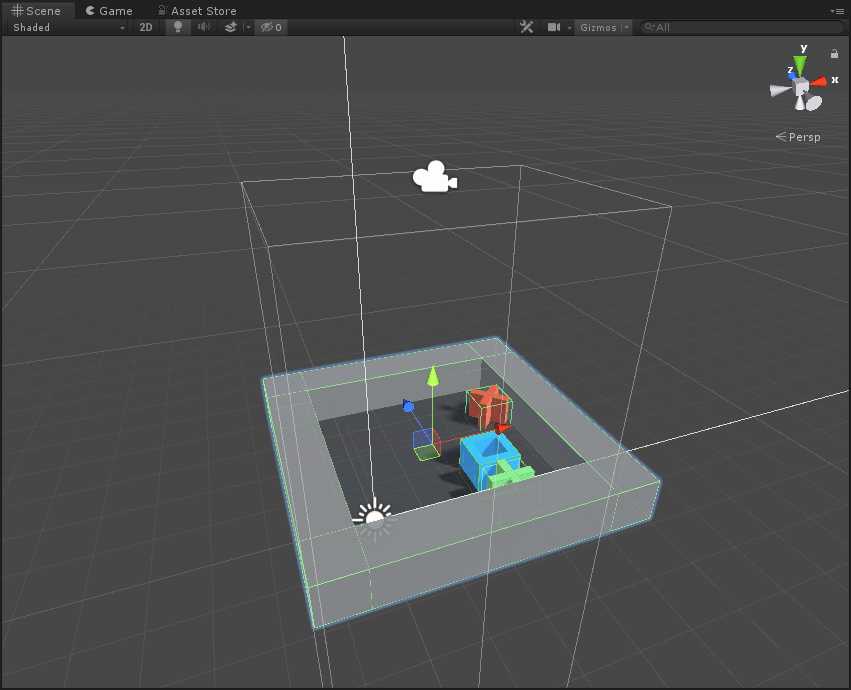
其Hierarchy层级为:
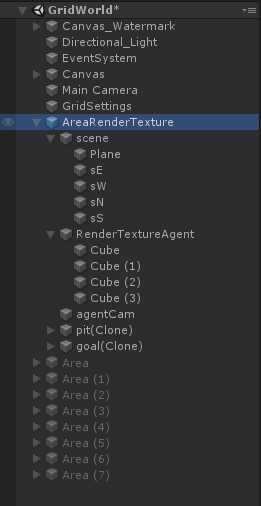
其中scene为组成Grid范围的父物体,包括一个plane和四个墙体;RenderTextureAgent则是蓝色方块,即为agent;agentCam为渲染相机,通过该相机观察而渲染得到的Texture就作为CNN的输入数据;pit和goal分别代表了障碍物和目标,这里是在运行时才在grid中随机位置生成。
注意这里的父节点AreaRenderTexutre上挂有Grid Area脚本,该脚本主要是初始化环境(包括墙体生成,目标、障碍随机生成等)、重置Agent以及环境的作用。
此外,你会发现这个AreaRenderTexutres单元和其他训练单元不同,因为该训练单元的Camera负责渲染输出了RenderTexture,即在运行时的小画面。
GridArea.cs
using System.Collections.Generic;
using UnityEngine;
using System.Linq;
using MLAgents;
using MLAgents.SideChannels;
public class GridArea : MonoBehaviour
{
[HideInInspector]
public List<GameObject> actorObjs;//障碍物和目标物GameObjects List
[HideInInspector]
public int[] players;//障碍物和目标物数组,其中“1”的个数代表障碍物个数,“0”的个数代表目标个数
public GameObject trueAgent;//代理
public GameObject goalPref;//目标预制体
public GameObject pitPref;//障碍物预制体
IFloatProperties m_ResetParameters;//泛化参数
Camera m_AgentCam;//基本单元的相机,需要设置相机的位置和orthographicSize
GameObject[] m_Objects;//存储目标和障碍的预制体
//地面以及四个墙面
GameObject m_Plane;
GameObject m_Sn;
GameObject m_Ss;
GameObject m_Se;
GameObject m_Sw;
Vector3 m_InitialPosition;//父预制体初始位置
public void Start()
{
//参数初始化
m_ResetParameters = Academy.Instance.FloatProperties;
m_Objects = new[] { goalPref, pitPref };
m_AgentCam = transform.Find("agentCam").GetComponent<Camera>();
actorObjs = new List<GameObject>();
var sceneTransform = transform.Find("scene");
m_Plane = sceneTransform.Find("Plane").gameObject;
m_Sn = sceneTransform.Find("sN").gameObject;
m_Ss = sceneTransform.Find("sS").gameObject;
m_Sw = sceneTransform.Find("sW").gameObject;
m_Se = sceneTransform.Find("sE").gameObject;
m_InitialPosition = transform.position;
}
/// <summary>
/// 设置环境
/// </summary>
public void SetEnvironment()
{
//初始化父结点位置,因为场景中有9个训练单元,根据gridSize来使各个训练单元分布开来
transform.position = m_InitialPosition * (m_ResetParameters.GetPropertyWithDefault("gridSize", 5f) + 1);
//初始化players数组,其中“1”代表障碍物,“0”代表目标物
var playersList = new List<int>();
for (var i = 0; i < (int)m_ResetParameters.GetPropertyWithDefault("numObstacles", 1f); i++)
{
playersList.Add(1);
}
for (var i = 0; i < (int)m_ResetParameters.GetPropertyWithDefault("numGoals", 1f); i++)
{
playersList.Add(0);
}
players = playersList.ToArray();
//初始化地面和墙体的位置以及比例,gridSize代表场景中格子数
var gridSize = (int)m_ResetParameters.GetPropertyWithDefault("gridSize", 5f);
m_Plane.transform.localScale = new Vector3(gridSize / 10.0f, 1f, gridSize / 10.0f);
m_Plane.transform.localPosition = new Vector3((gridSize - 1) / 2f, -0.5f, (gridSize - 1) / 2f);
m_Sn.transform.localScale = new Vector3(1, 1, gridSize + 2);
m_Ss.transform.localScale = new Vector3(1, 1, gridSize + 2);
m_Sn.transform.localPosition = new Vector3((gridSize - 1) / 2f, 0.0f, gridSize);
m_Ss.transform.localPosition = new Vector3((gridSize - 1) / 2f, 0.0f, -1);
m_Se.transform.localScale = new Vector3(1, 1, gridSize + 2);
m_Sw.transform.localScale = new Vector3(1, 1, gridSize + 2);
m_Se.transform.localPosition = new Vector3(gridSize, 0.0f, (gridSize - 1) / 2f);
m_Sw.transform.localPosition = new Vector3(-1, 0.0f, (gridSize - 1) / 2f);
//初始化正交相机
m_AgentCam.orthographicSize = (gridSize) / 2f;//相机正交视野
m_AgentCam.transform.localPosition = new Vector3((gridSize - 1) / 2f, gridSize + 1f, (gridSize - 1) / 2f);//相机位置
}
/// <summary>
/// 环境重置
/// </summary>
public void AreaReset()
{
var gridSize = (int)m_ResetParameters.GetPropertyWithDefault("gridSize", 5f);//网格数
foreach (var actor in actorObjs)
{//销毁当前所有目标和障碍
DestroyImmediate(actor);
}
SetEnvironment();//环境重置
actorObjs.Clear();
//利用HashSet,计算出players.Length+1个(所有障碍和目标数量+1个Agent)不重复的随机值
var numbers = new HashSet<int>();
while (numbers.Count < players.Length + 1)
{
numbers.Add(Random.Range(0, gridSize * gridSize));
}
var numbersA = Enumerable.ToArray(numbers);
//采用x=randomNum/gridSize,y=randomNum%gridSize来确定每个物体的位置
for (var i = 0; i < players.Length; i++)
{//障碍物与目标物随机放置
var x = (numbersA[i]) / gridSize;
var y = (numbersA[i]) % gridSize;
var actorObj = Instantiate(m_Objects[players[i]], transform);
actorObj.transform.localPosition = new Vector3(x, -0.25f, y);
actorObjs.Add(actorObj);
}
//Agent位置随机重置
var xA = (numbersA[players.Length]) / gridSize;
var yA = (numbersA[players.Length]) % gridSize;
trueAgent.transform.localPosition = new Vector3(xA, -0.25f, yA);
}
}
环境重置代码总体来讲比较简单,以上代码加注释基本大多都没问题。
在之前3D Ball中,初始化在InitializeAgent()中,重置在AgentReset()中,从某种意义上讲,初始化与重置其实是一样的。在本示例Grid World中,将环境和Agent的初试化重置都放到了GridArea.cs脚本中,除此之外,可以来看一下Agent脚本初始化的变量。
public class GridAgent : Agent
{
[FormerlySerializedAs("m_Area")]//[FormerlySerializedAs(name)]特性可以防止当“area”变量改名时,导致原序列化对象丢失,具体操作见后文
[Header("Specific to GridWorld")]//[Header(string)]使该变量前有一个说明型标题
public GridArea area;//环境重置脚本
public float timeBetweenDecisionsAtInference;//代理行动速度,每隔timeBetweenDecisionsAtInference秒移动一次
float m_TimeSinceDecision;//决策时间计时器
public Camera renderCamera;//要输出RenderTexture的相机
public bool maskActions = true;//动作遮罩开关,若禁用,可能会使得有动作遮罩的训练模型达不到最佳训练效果
//方块代理的动作值
const int k_NoAction = 0;//无动作
const int k_Up = 1;//向上移动
const int k_Down = 2;//向下移动
const int k_Left = 3;//向左移动
const int k_Right = 4;//向右移动
public override void InitializeAgent()
{//为空
}
public override void AgentReset()
{
area.AreaReset();//代理重置
}
}
以上代码大多数都有注释,问题不大,下面说里面两个Unity中的特性。
[FormerlySerializedAs(string name)]
这个特性可以使得脚本中被序列化的属性或变量在保持引用对象不丢失的情况下重命名。具体使用方式如下,假设有脚本Test.cs:
Test.cs
using UnityEngine;
public class Test : MonoBehaviour
{
public GridArea Area;
void Start()
{
}
}
将其放到场景中某物体上,并且将任意符合脚本拖到“Area”变量上。
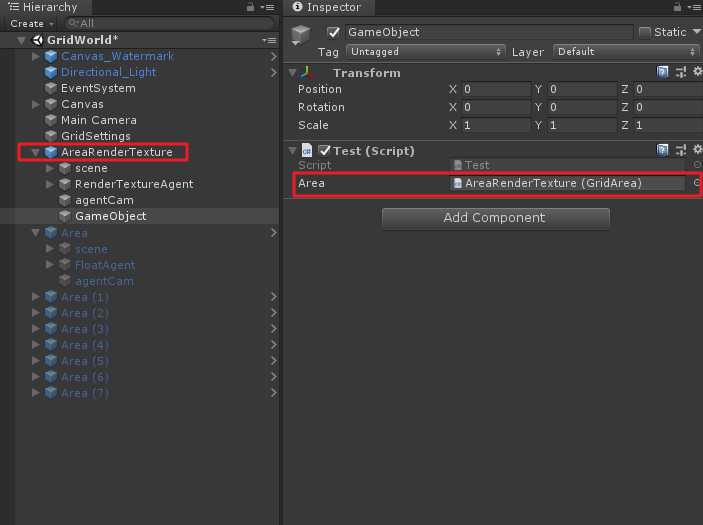
如果此时若改变Area变量名为Area_1,会出现以下现象:
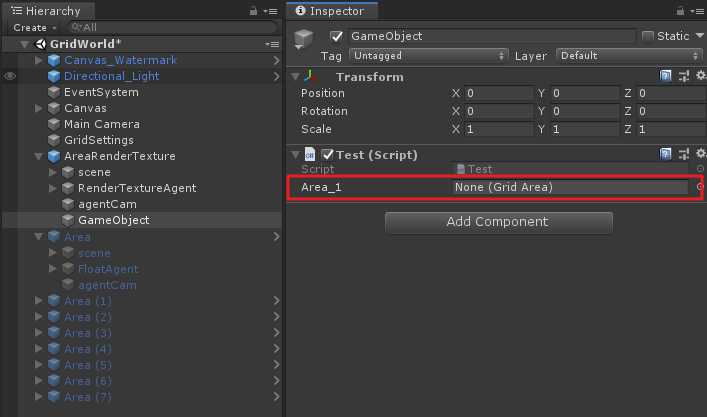
会发现原先的引用变量丢失,为了防止如上情况,则需要使用[FormerlySerializedAs]特性来避免,例如这里我们继续将原来的引用赋给Area_1里去。
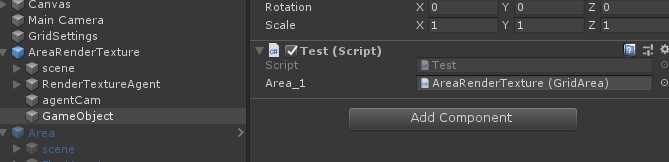
然后在重命名Area_1前,给它加上FormerlySerializedAs特性,如下:
using UnityEngine;
using UnityEngine.Serialization;
public class Test : MonoBehaviour
{
[FormerlySerializedAs("Area_1")]
public GridArea Area;
void Start()
{
}
}
再来看原先变量的引用:
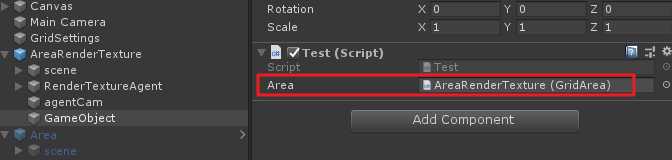
会返现该引用存在,当然若此处的引用还有许多参数变量,也可以使得这些变量序列化不丢失。不过这种拖物体到脚本上的方法其实在开发中一般是不推荐的,如果一个工程较大,许多物体都采用这种方式来引用的话,场景中的物体引用丢失就很难统一管理。
[Header(string content)]
直接看效果就行,这个特性比较简单。
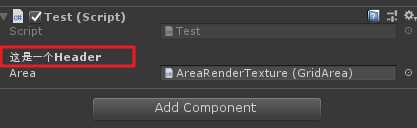
关于动作遮罩上文中已介绍,来看一下Grid World中对于遮罩的设置。
public override void CollectDiscreteActionMasks(DiscreteActionMasker actionMasker)
{
if (maskActions)//动作遮罩开关
{
//防止agent碰到墙体
var positionX = (int)transform.position.x;//agent的x位置
var positionZ = (int)transform.position.z;//agent的z位置
//agent移动的最大位置
var maxPosition = (int)Academy.Instance.FloatProperties.GetPropertyWithDefault("gridSize", 5f) - 1;
if (positionX == 0)
{//当agent在最左边时,不能再向左
actionMasker.SetMask(0, new int[] { k_Left });
}
if (positionX == maxPosition)
{//当agent在最右边时,不能再向右
actionMasker.SetMask(0, new int[] { k_Right });
}
if (positionZ == 0)
{//当agent在最下边时,不能再向下
actionMasker.SetMask(0, new int[] { k_Down });
}
if (positionZ == maxPosition)
{//当agent在最上边时,不能再向上
actionMasker.SetMask(0, new int[] { k_Up });
}
}
}
配合以下图:
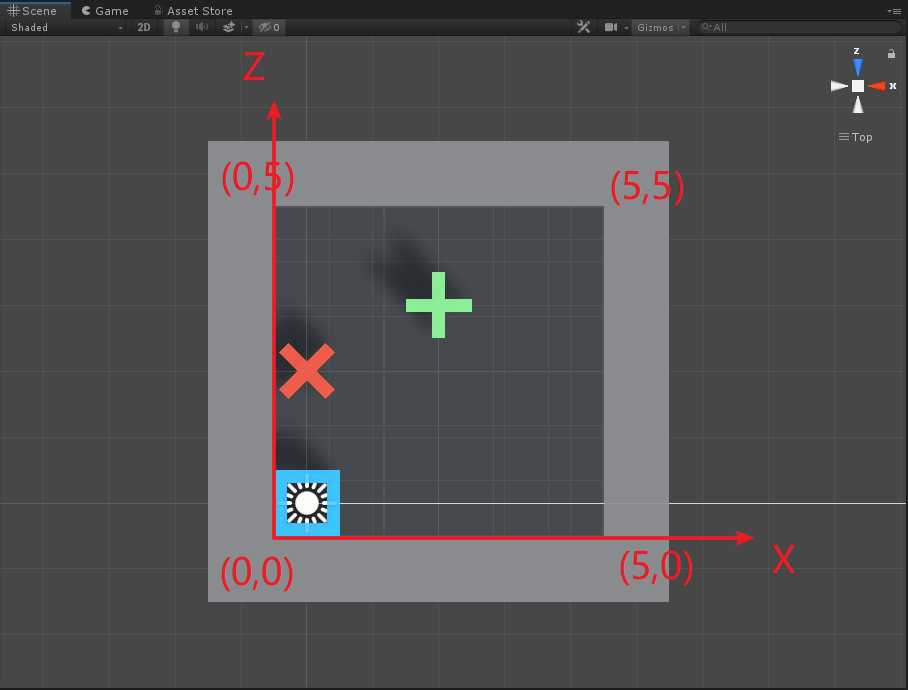
基本上代码配合图,动作遮罩就明白了,此外动作遮罩只适用于Discrete Type,即离散空间反馈时才可以使用动作遮罩。
下面看一下agent的动作反馈函数AgentAction()。
public override void AgentAction(float[] vectorAction)
{
AddReward(-0.01f); //每一步都惩罚0.01,为使得agent可以尽快找到目标
//反馈参数转换为整数
var action = Mathf.FloorToInt(vectorAction[0]);
//根据action参数计算agent将要移动的下一个位置targetPos
var targetPos = transform.position;
switch (action)
{
case k_NoAction:
// do nothing
break;
case k_Right:
targetPos = transform.position + new Vector3(1f, 0, 0f);
break;
case k_Left:
targetPos = transform.position + new Vector3(-1f, 0, 0f);
break;
case k_Up:
targetPos = transform.position + new Vector3(0f, 0, 1f);
break;
case k_Down:
targetPos = transform.position + new Vector3(0f, 0, -1f);
break;
default:
throw new ArgumentException("Invalid action value");
}
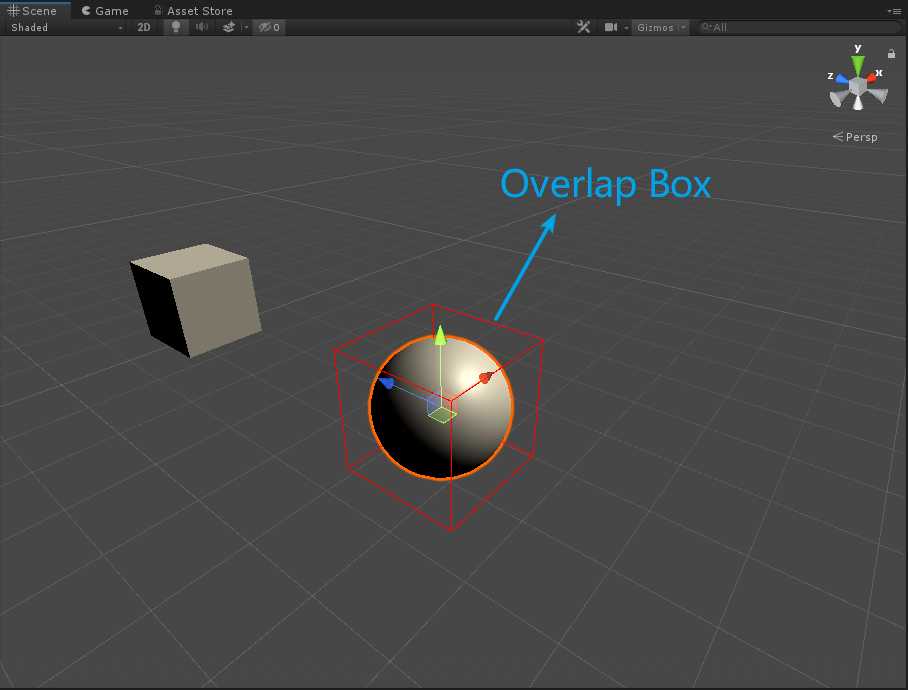
//定义Box型射线检测,在agent将要移动的下一个位置生成一个Box射线检测
var hit = Physics.OverlapBox(
targetPos, new Vector3(0.3f, 0.3f, 0.3f));
if (hit.Where(col => col.gameObject.CompareTag("wall")).ToArray().Length == 0)
{//若agent的下一个位置没有碰到墙体("wall"标签的物体),则移动agent
transform.position = targetPos;
if (hit.Where(col => col.gameObject.CompareTag("goal")).ToArray().Length == 1)
{//如果移动的下一个位置是目标(goal),则奖励1,此次训练完成
SetReward(1f);
Done();
}
else if (hit.Where(col => col.gameObject.CompareTag("pit")).ToArray().Length == 1)
{//如果移动的下一个位置是障碍物(pit),则惩罚1,此次训练完成
SetReward(-1f);
Done();
}
}
}
以上代码经过注释后,也没有太难理解的地方。注意以下两点:
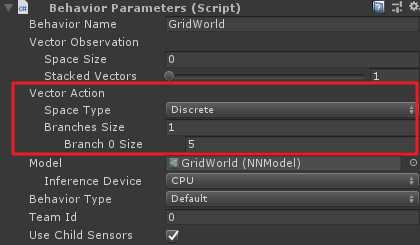
形参vectorAction代表了agent的运动矢量空间,grid world的agent每次只有一个离散的动作运动,即Branches Size为1,而这个运动可以包括五个选择k_NoAction、k_Right、k_Left、k_Up和k_Down,因此Branch 0 Size为5.
Physics.OverlapBox为Box型射线,如下图。此外,这里可以提供一个思路,可以在计算出来的下一个位置先生成一个射线检测或者碰撞体来检测下一个位置是否是符合条件的位置。
在Agent脚本中,还注意到运用了FixedUpdate()来影响agent的brain做出决策:
public void FixedUpdate()
{
WaitTimeInference();//每帧调用
}
void WaitTimeInference()
{
if (renderCamera != null)
{//若渲染相机不为空,则每帧手动使相机渲染
renderCamera.Render();
}
if (Academy.Instance.IsCommunicatorOn)
{//判断是否环境是否与Python相连,若相连,则每帧使agent的brain做出决策
RequestDecision();
}
else
{//若未与外界相连,则timeBetweenDecisionsAtInference秒后,使得brain做出决策
if (m_TimeSinceDecision >= timeBetweenDecisionsAtInference)
{
m_TimeSinceDecision = 0f;
RequestDecision();
}
else
{
m_TimeSinceDecision += Time.fixedDeltaTime;//决策计时器
}
}
}
手动操作代码具体如下:
public override float[] Heuristic()
{
if (Input.GetKey(KeyCode.D))
{
return new float[] { k_Right };
}
if (Input.GetKey(KeyCode.W))
{
return new float[] { k_Up };
}
if (Input.GetKey(KeyCode.A))
{
return new float[] { k_Left };
}
if (Input.GetKey(KeyCode.S))
{
return new float[] { k_Down };
}
return new float[] { k_NoAction };
}
这里代码比较好理解,但是如果要是调到手动操作模式,会发现在场景中你的操作并不能得到反馈,这是由于Agent上没有添加Decision Requester组件,添加后,然后将Behavior Type改为Heuristic Only,即可手动操作。虽然操作起来没那么舒爽= =。
在场景中还能发现在Main Camera上有GridSetting.cs脚本,如下:
using UnityEngine;
using MLAgents;
public class GridSettings : MonoBehaviour
{
public Camera MainCamera;
public void Awake()
{
Academy.Instance.FloatProperties.RegisterCallback("gridSize", f =>
{
MainCamera.transform.position = new Vector3(-(f - 1) / 2f, f * 1.25f, -(f - 1) / 2f);
MainCamera.orthographicSize = (f + 5f) / 2f;
});
//测试
//MainCamera.transform.position = new Vector3(-(10 - 1) / 2f, 10 * 1.25f, -(10 - 1) / 2f);
//MainCamera.orthographicSize = (10 + 5f) / 2f;
}
}
其实这里用处就是根据gridSize来初始化主相机的位置,不知道为啥源码中对于这里的回调调用有问题,于是我直接使的gridSize变为10(这里同时需要修改GridArea和GridAgent中相关的gridSize数值为10),然后利用上述代码测试注释部分来调整相机位置,得出如下效果:
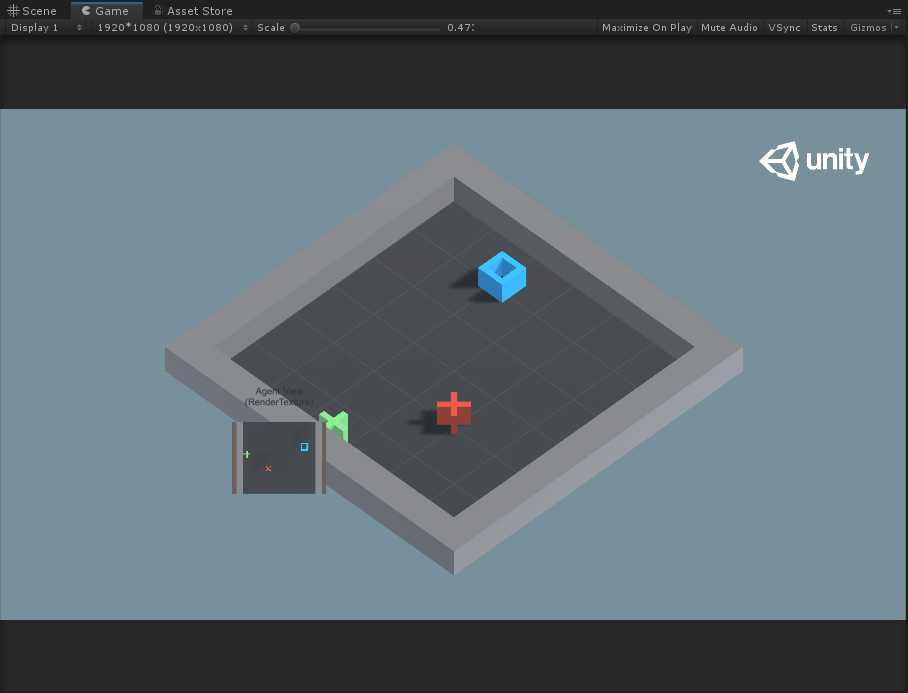
可以发现相机会根据gridSize动态调整合适的位置。
工程看到一半,发现该示例中其实两个类型的Visual Observation Sensor都用到了:
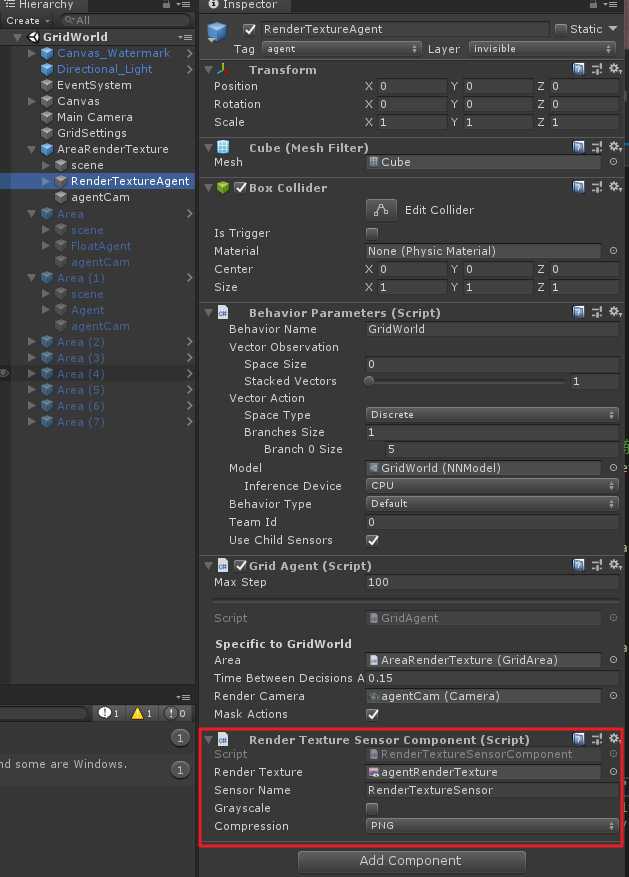
另一个
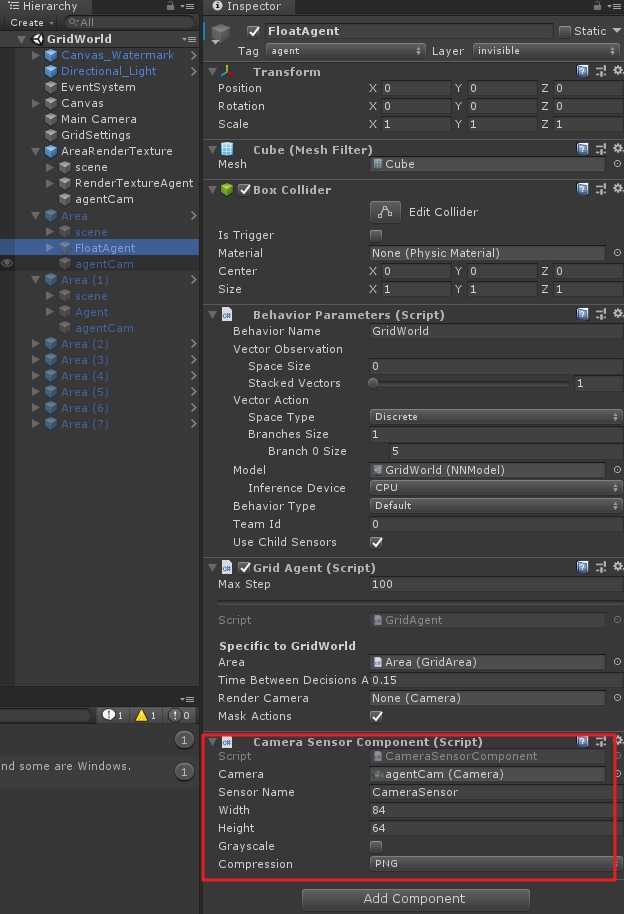
在工程中AreaRenderTexture训练单元使用了Render Texture Sensor Component,而其他Agent单元却使用的是Camera Sensor Component。这里你会发现在AreaRenderTexture训练单元中,如果将agentCam去掉,也对输出没啥影响,因为它使用RenderTextureSensor来训练的。不知道这是是我理解错了,还是说官方就是想用两个Sensor来在这里教(迷惑?)大家使用。。。。
OK,以上就是示例代码部分的分析,下面我们来实操试试训练该工程。首先试验一下将障碍物和目标物的数量改为3和2试一下原先工程的训练模型有没有训练泛化参数。
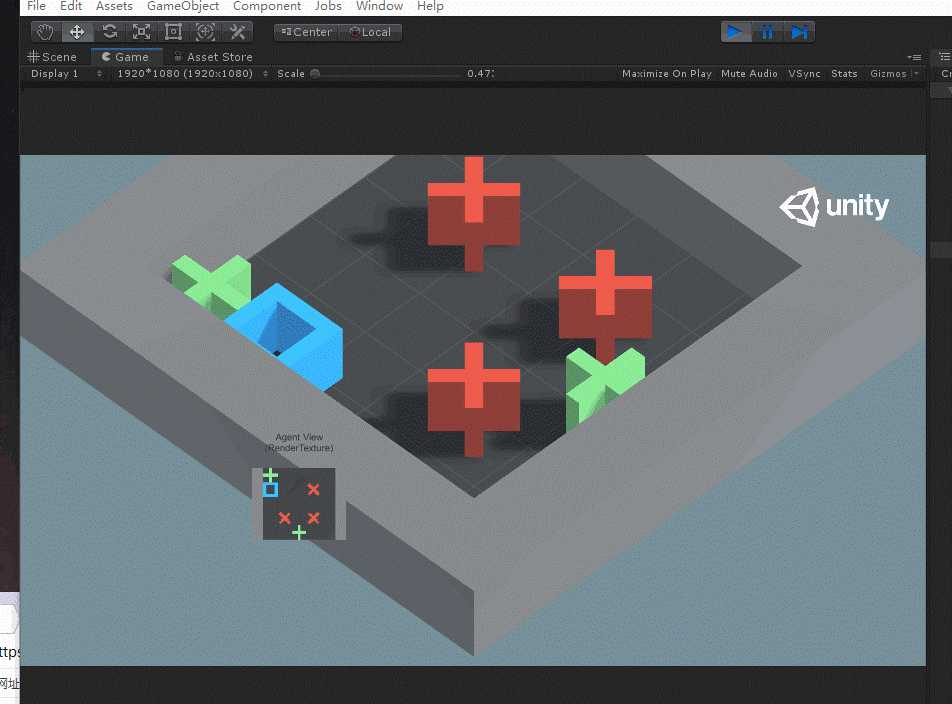
根据以上画面可以发现,代理有点笨,不能立马找到目标物,说明原先的训练模型可能没有引入泛化参数,因此我们训练的时候引入泛化参数来对其进行训练。
根据本示例中的泛化参数,我们在ml-agent\config新建gridworld_generalize.yaml配置文件:
resampling-interval: 5000
gridSize:
sampler-type: "uniform"
min_value: 5
max_value: 15
numObstacles:
sampler-type: "uniform"
min_value: 1
max_value: 5
numGoals:
sampler-type: "uniform"
min_value: 1
max_value: 3
这里配置文件的含义是,gridSize最小为5格,最大为15格;障碍物最少有1个,最多有5个;目标物最少有1个,最多有3个。
当然这里的配置我也是试一下,对于这里参数的配置我也还没有多少经验,不过可以以此来看一下能不能使得训练模型在一定可变范围内具有通用性。
基于之前的文章,这里就不详细写训练过程了,只将关键步骤做以说明,cd到ml-agent的d目录,然后输入以下训练命令:
mlagents-learn config/trainer_config.yaml --sampler=config/gridworld_generalize.yaml --run-id=GridWolrd_Gen --train
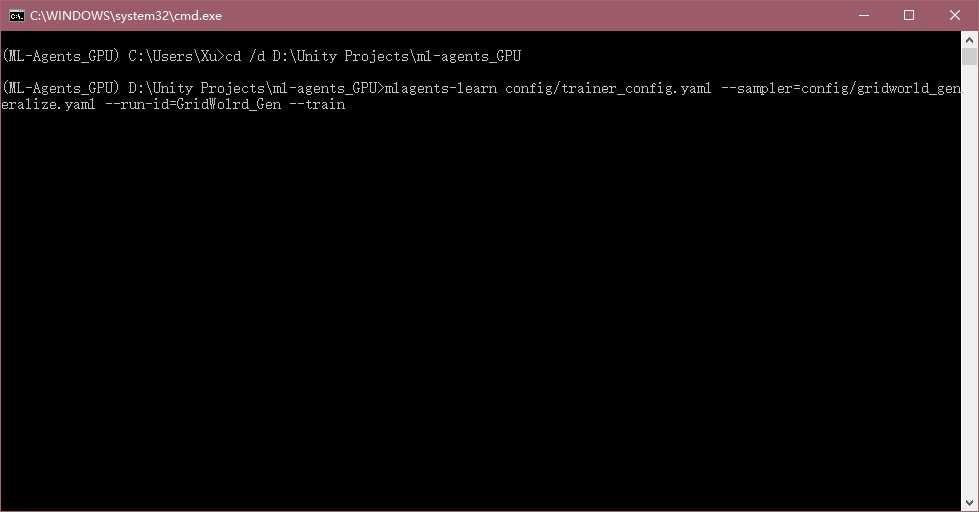
这一次的训练过程相比3D Ball来说就比较卡了,等一段时间,在cmd里应该会有相应训练步骤输出,等待它训练完成即可。我这里训练大概花了35分钟。坑爹的是。。。这里对于三个参数的泛化训练,训练的结果并不好,甚至连最基本的要求都没达到。
试着只泛化一个参数,选择障碍物可以有1-4个,然后进行训练再看看,又是30分钟等待= =,发现就算有一个障碍物参数随机变化,训练效果也不好。
下面附上三次训练的tenserboard(三个泛化参数,一个泛化参数和无泛化参数)。
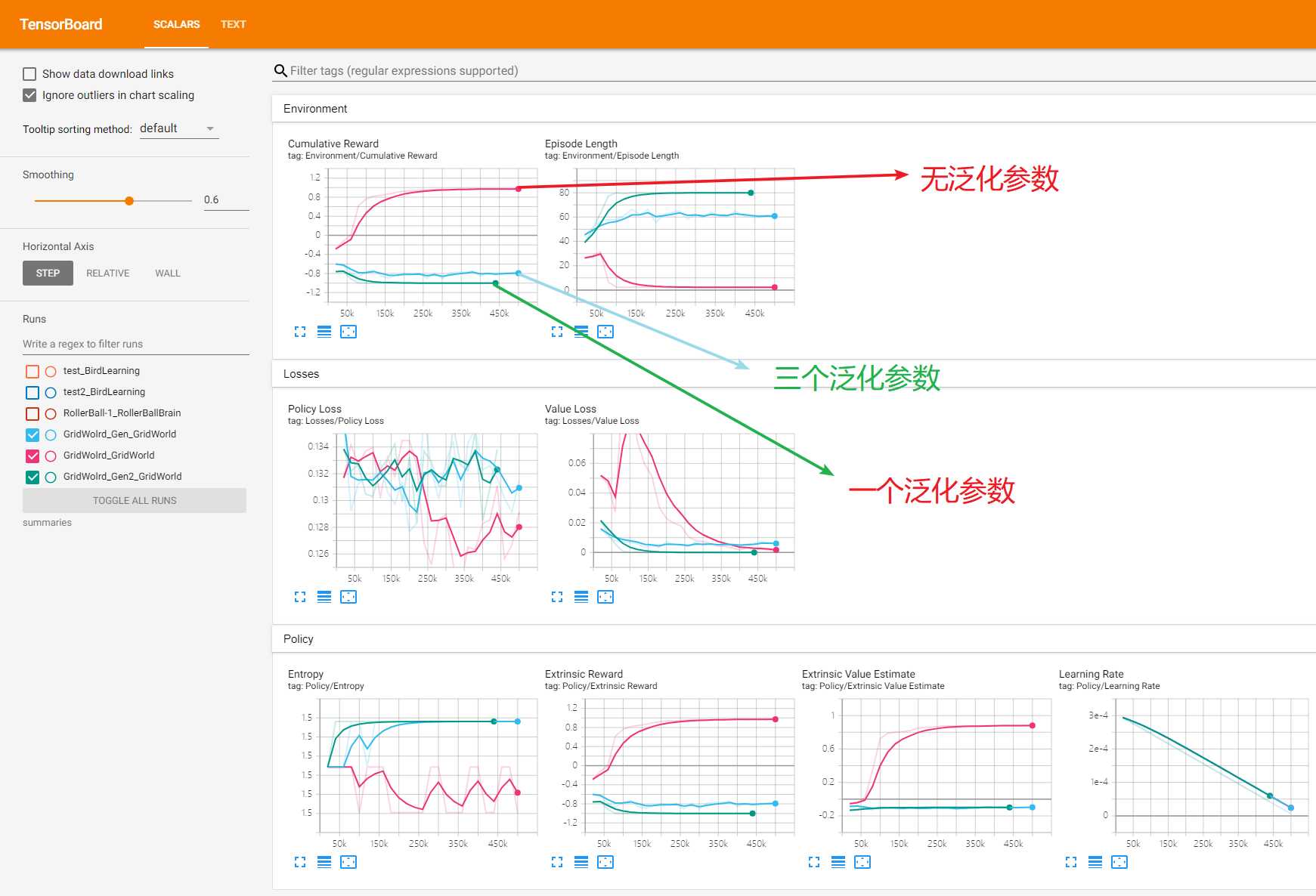
根据图表就可以看出来,两个加入泛化参数的训练是失败的,具体为什么可能之后了解更多ml-agent才能知道。实际上把加入泛化参数的两个模型放到Unity中去跑,也会发现训练结果并不理想。
Grid World这个示例还是比较有趣的,主要它利用了Visual Observations视觉观察值来输出图像进行训练,更加像人类用眼睛去学习的过程。当然不足的地方就是没有把训练的模型进行泛化,这点之后再研究吧。
写文不易~因此做以下申明:
1.博客中标注原创的文章,版权归原作者 煦阳(本博博主) 所有;
2.未经原作者允许不得转载本文内容,否则将视为侵权;
3.转载或者引用本文内容请注明来源及原作者;
4.对于不遵守此声明或者其他违法使用本文内容者,本人依法保留追究权等。
标签:scale 蓝色 排序 分支 sam hash 分布 因此 通过
原文地址:https://www.cnblogs.com/gentlesunshine/p/12639136.html