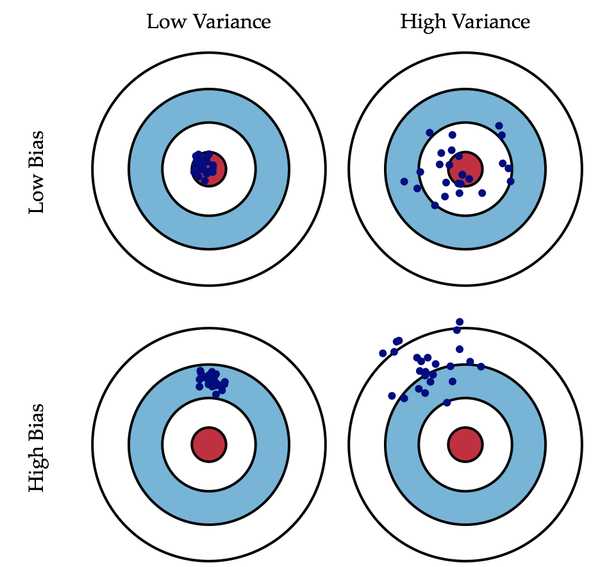
2.1 偏差
模型的偏差是一个相对来说简单的概念:训练出来的模型在训练集上的准确度。偏差度量了学习算法的期望预测与真实结果的偏离程度,刻画了学习算法的本身你和能力。
2.2 方差
我们认为方差越大的模型越容易过拟合:假设有两个训练集A和B,经过A训练的模型Fa与经过B训练的模型Fb差异很大,这意味着Fa在类A的样本集合上有更好的性能,而Fb反之,这便是我们所说的过拟合现象。方差度量了同样大小的训练集的变动导致的学习性能的变化,即刻画了数据扰动所造成的影响。
2.3 泛化性能
根据偏差-方差分解说明(《机器学习(周志华)第44页),泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定的。给定的学习任务,为了取得良好的性能,需要使偏差较小(充分拟合数据),方差较小(数据扰动产生影响小)。
我认为书中第46页一段话能解释什么样的参数是我们所需要能得到最优泛化性能的,摘录如下“一般来讲,偏差与方差是有冲突的,称为偏差-方差窘境(bias-varince dilemma)。 给定学习任务,假定我们能控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强, 训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学习到了,则将发生过拟合。”
对于bagging来说,,整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。
3. Random Forest
Random Forest是Bagging的一个扩展变体。RF在以决策树为基学习器构建Bagging的基础上,进一步在决策树的训练过程中引入了随机属性选择。即在树的内部节点分裂过程中,不再是将所有特征,而是随机抽样一部分特征纳入分裂的候选项。这样一来,基模型之间的相关性降低,从而在方差公式中,继续导致整体方差仍是减少。
在sklearn.ensemble库中,我们可以找到Random Forest分类和回归的实现:RandomForestClassifier和RandomForestRegression。本文主要关注分类。
回顾上文,参数可分为两种,一种是影响模型在训练集上的准确度或影响防止过拟合能力的参数;另一种不影响这两者的其他参数。所以调参的步骤如下:
a:我们的目标是找到第一种参数,确定对目标是正影响还是负影响和影响的大小
b:通过某些策略提高训练效率
c:训练过程的检测
对于a,我们可以把模型的参数分为4类:目标类、性能类、效率类和附加类。下表详细地展示了RF中这4个模型参数的意义:
注:下表是直接从http://www.cnblogs.com/jasonfreak/p/5657196.html 中copy过来的,所以包含其他三种模型,不过真的好赞~~~
| 参数 | 类型 | RandomForestClassifier | RandomForestRegressor | GradientBoostingClassifier | GradientBoostingRegressor |
| loss | 目标 |
损失函数 ● exponential:模型等同AdaBoost ★ deviance:和Logistic Regression的损失函数一致 |
损失函数 ● exponential:模型等同AdaBoost ★ deviance:和Logistic Regression的损失函数一致 |
||
| alpha | 目标 | 损失函数为huber或quantile的时,alpha为损失函数中的参数 | 损失函数为huber或quantile的时,alpha为损失函数中的参数 | ||
| class_weight | 目标 |
类别的权值 |
|||
| n_estimators | 性能 |
子模型的数量 ● int:个数 ★ 10:默认值 |
子模型的数量
● int:个数 ★ 10:默认值 |
子模型的数量
● int:个数 ★ 100:默认值 |
子模型的数量
● int:个数 ★ 100:默认值 |
| learning_rate | 性能 | 学习率(缩减) | 学习率(缩减) | ||
| criterion | 性能 |
判断节点是否继续分裂采用的计算方法 ● entropy ★ gini |
判断节点是否继续分裂采用的计算方法 ★ mse |
||
| max_features | 性能 |
节点分裂时参与判断的最大特征数 ● int:个数 ● float:占所有特征的百分比 ★ auto:所有特征数的开方 ● sqrt:所有特征数的开方 ● log2:所有特征数的log2值 ● None:等于所有特征数 |
节点分裂时参与判断的最大特征数 ● int:个数 ● float:占所有特征的百分比 ★ auto:所有特征数的开方 ● sqrt:所有特征数的开方 ● log2:所有特征数的log2值 ● None:等于所有特征数 |
节点分裂时参与判断的最大特征数 ● int:个数 ● float:占所有特征的百分比 ● auto:所有特征数的开方 ● sqrt:所有特征数的开方 ● log2:所有特征数的log2值 ★ None:等于所有特征数 |
节点分裂时参与判断的最大特征数 ● int:个数 ● float:占所有特征的百分比 ● auto:所有特征数的开方 ● sqrt:所有特征数的开方 ● log2:所有特征数的log2值 ★ None:等于所有特征数 |
| max_depth | 性能 |
最大深度,如果max_leaf_nodes参数指定,则忽略 ● int:深度 ★ None:树会生长到所有叶子都分到一个类,或者某节点所代表的样本数已小于min_samples_split |
最大深度,如果max_leaf_nodes参数指定,则忽略
● int:深度 ★ None:树会生长到所有叶子都分到一个类,或者某节点所代表的样本数已小于min_samples_split |
最大深度,如果max_leaf_nodes参数指定,则忽略 ● int:深度 ★ 3:默认值 |
最大深度,如果max_leaf_nodes参数指定,则忽略 ● int:深度 ★ 3:默认值 |
| min_samples_split | 性能 |
分裂所需的最小样本数 ● int:样本数 ★ 2:默认值 |
分裂所需的最小样本数 ● int:样本数 ★ 2:默认值 |
分裂所需的最小样本数 ● int:样本数 ★ 2:默认值 |
分裂所需的最小样本数 ● int:样本数 ★ 2:默认值 |
| min_samples_leaf | 性能 |
叶节点最小样本数 ● int:样本数 ★ 1:默认值 |
叶节点最小样本数 ● int:样本数 ★ 1:默认值 |
叶节点最小样本数 ● int:样本数 ★ 1:默认值 |
叶节点最小样本数 ● int:样本数 ★ 1:默认值 |
| min_weight_fraction_leaf | 性能 |
叶节点最小样本权重总值 ● float:权重总值 ★ 0:默认值 |
叶节点最小样本权重总值 ● float:权重总值 ★ 0:默认值 |
叶节点最小样本权重总值 ● float:权重总值 ★ 0:默认值 |
叶节点最小样本权重总值 ● float:权重总值 ★ 0:默认值 |
| max_leaf_nodes | 性能 |
最大叶节点数 ● int:个数 ★ None:不限制叶节点数 |
最大叶节点数 ● int:个数 ★ None:不限制叶节点数 |
最大叶节点数 ● int:个数 ★ None:不限制叶节点数 |
最大叶节点数 ● int:个数 ★ None:不限制叶节点数 |
| bootstrap | 性能 |
是否bootstrap对样本抽样 ● False:子模型的样本一致,子模型间强相关 ★ True:默认值 |
是否bootstrap对样本抽样 ● False:子模型的样本一致,子模型间强相关 ★ True:默认值 |
||
| subsample | 性能 |
子采样率 ● float:采样率 ★ 1.0:默认值 |
子采样率 ● float:采样率 ★ 1.0:默认值 |
||
| init | 性能 | 初始子模型 | 初始子模型 | ||
| n_jobs | 效率 |
并行数 ● int:个数 ● -1:跟CPU核数一致 ★ 1:默认值 |
并行数
● int:个数 ● -1:跟CPU核数一致 ★ 1:默认值 |
||
| warm_start | 效率 |
是否热启动,如果是,则下一次训练是以追加树的形式进行 ● bool:热启动 ★ False:默认值 |
是否热启动,如果是,则下一次训练是以追加树的形式进行 ● bool:热启动 ★ False:默认值 |
是否热启动,如果是,则下一次训练是以追加树的形式进行 ● bool:热启动 ★ False:默认值 |
是否热启动,如果是,则下一次训练是以追加树的形式进行 ● bool:热启动 ★ False:默认值 |
| presort | 效率 |
|
是否预排序,预排序可以加速查找最佳分裂点,对于稀疏数据不管用
● Bool ★ auto:非稀疏数据则预排序,若稀疏数据则不预排序 |
是否预排序,预排序可以加速查找最佳分裂点,对于稀疏数据不管用
● Bool ★ auto:非稀疏数据则预排序,若稀疏数据则不预排序 |
|
| oob_score | 附加 |
是否计算袋外得分 ★ False:默认值 |
是否计算袋外得分 ★ False:默认值 |
||
| random_state | 附加 | 随机器对象 | 随机器对象 | 随机器对象 | 随机器对象 |
| verbose | 附加 |
日志冗长度 ● int:冗长度 ★ 0:不输出训练过程 ● 1:偶尔输出 ● >1:对每个子模型都输出 |
日志冗长度 ● int:冗长度 ★ 0:不输出训练过程 ● 1:偶尔输出 ● >1:对每个子模型都输出 |
日志冗长度 ● int:冗长度 ★ 0:不输出训练过程 ● 1:偶尔输出 ● >1:对每个子模型都输出 |
日志冗长度 ● int:冗长度 ★ 0:不输出训练过程 ● 1:偶尔输出 ● >1:对每个子模型都输出 |
上述第一种影响准确度的参数又可分为两类:过程影响类及子模型影响类。在子模型不变的前提下,某些参数可以通过改变训练的过程,从而影响模型的性能,诸如:“子模型数”(n_estimators)、“学习率”(learning_rate)等。还可以通过改变子模型性能来影响整体模型的性能,诸如:“最大树深度”(max_depth)、“分裂条件”(criterion)等。现在可以进一步明确目标了,RF基学习器都拥有较低的偏差,整体模型的训练过程旨在降低方差,故其需要较少的子模型(n_estimators默认值为10)且子模型不为弱模型(max_depth的默认值为None),同时,降低子模型间的相关度可以起到减少整体模型的方差的效果(max_features的默认值为auto)。