标签:实时 完成 限制 process rop 穷举 复杂 接受 特征

1997年电脑深蓝首次战胜国象棋王卡斯帕罗夫
1997年,美国IBM公司的“深蓝”(Deep Blue)超级计算机以2胜1负3平战胜了当时世界排名第一的国际象棋大师卡斯帕罗夫。
深蓝能算出12手棋之后的最优解,而身为人类的卡斯帕罗夫只能算出10手棋。
深蓝的核心是通过穷举方法,生成所有可能的下法,然后执行尽可能深的搜索,并不断对局面进行评估,尝试找出最佳的一手。
简单地说,深蓝是以暴力穷举为基础,并且是专注国际象棋的专用人工智能

AlphaGo 核心是基于深度神经网络,从数据中预测人类棋手在做任意的棋盘状态下走子的概率,模拟人类棋手的思维方式。在整个算法中,除了“获胜”概念,AlphaGo对于围棋规则一无所知。
简单地说,AlphaGo是基于机器学习,不限定领域的人工智能。
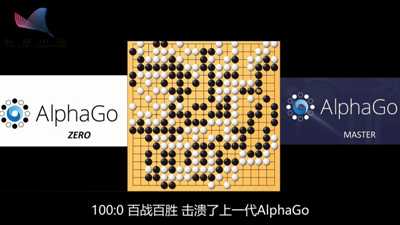
仅仅通过3天的自我训练的AlphaGo Zero,AlphaGo Zero就打败了战胜李世石的AlphaGo,战绩100:0。
和AlhaGo不同,AlphaGo Zero完全抛弃了来自棋谱数据的人类经验,而是通过周伯通的“左右手互搏”,迅速提升功力。
AlphaGo Zero依赖神经网络来评估落子位置,成功证明了在没有人类指导和经验的前提下,深度强化学习方法在围棋领域里仍然能够出色的完成指定的任务。
AlphaGo和AlphaGo Zero的核心都是深度学习,那深度学习究竟是什么呢?

深度学习是利用包含多个隐藏层的人工神经网络实现的学习。
深度学习思想来源于人类处理视觉信息方式,人类视觉系统是这个世界上最为神奇的一个系统。
1981年的诺贝尔医学奖得主David H.Hubel 和Torsten Wiesel的研究表明:即人脑视觉机理,是指视觉系统的信息处理在可视皮层是分级的,大脑的工作过程是一个不断迭代、不断抽象的过程。视网膜在得到原始信息后,首先经由区域V1初步处理得到边缘和方向特征信息,其次经由区域V2的进一步抽象得到轮廓和形状特征信息,如此迭代地经由更多更高层的抽象最后得到更为精细的分类。
人眼处理来自外界的视觉信息时,首先提取出目标物的边缘,再从边缘特性中提取出目标物的特征,最后将不同特征组合成相应的整体,进而准确地区分不同的物体,在这个过程中,高层特征是低层特征的组合,从低导到高层,特征变得越来越抽象,对目标物的识别也越来越精确 。
在深度学习中,每个层可以对数据进行不同水平的抽象,层间的交互使较高层在较低层得到的特征基础上实现更加复杂的特征提取。
深度学习是建立在大数据量和超强的计算能力之上,因为多个隐藏层使用了大量的隐藏神经元,庞大的数据处理需要有非常强的计算能力做支撑
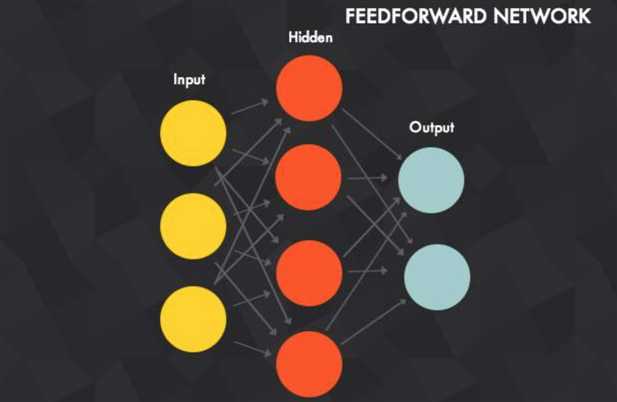
具有深度结构的前馈神经网络,可以看成是进化版的多层感知器。
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。是目前应用最广泛、发展最迅速的人工神经网络之一。
在层与层之间,深度架构采用的最常见的方式是全连接,意味着相邻层次中的任意神经元都是两两相连。
任何机器学习算法都可以看成是对某个预设函数的最优化方法,深度前馈网络也一样。深度前馈神经网络也是利用梯度信息进行学习,处理误差采用反向传播方法,利用反向传播求出梯度后再使用随机梯度下降法寻找损失函数的最小值。
深度前馈网络的损失函数通常是交叉熵或最小均方差,回归问题的损失函数通常是最小均方误差,而分类问题的损失函数通常是交叉熵。

正则化是抑制过拟合的手段,是一类通过显式设计降低泛化误差,提升通用性的策略的统称。
通常来说,泛化误差的下降是以训练误差的上升为代价的。
从概率论角度,许多正则化技术对应的是在模型参数上施加一定的先验分布,作用是改变泛化误差的结构。机器学习的任务是拟合出一个从输入x到输出y的分布,拟合过程是使期望风险函数最小化的过程。

正则化处理可以看成是奥卡姆剃刀原则在学习算法上的应用。
奥卡姆剃刀原则 :如无必要,勿增实体
简单地说,就是当两个假说具有完全相同的解释力和预测力时时,以那个较为简单的假说作为讨论依据。
机器学习中,正则化得到的是更加简单的模型、

深度神经网络中隐藏层比较多,将整个网络作为一个整体进行优化是非常困难的事,出于效率和精确性的考虑,需要采取一些优化的手段。

随机梯度下降法是在机器学习的经典算法,是对原始梯度下降法的一种改良。为了节省每次迭代的计算成本,随机梯度下降在每一次迭代中都使用训练数据集的一个较小子集来求解梯度的均值,随机梯度下降法让每几个样本的风险函数最小化,虽然不是每次迭代的结果都是指向全局的最优方向,但是大方向没有错,最终的结果也在全局最优解附近。
在随机梯度下降法的基础上改进,常见方法有:
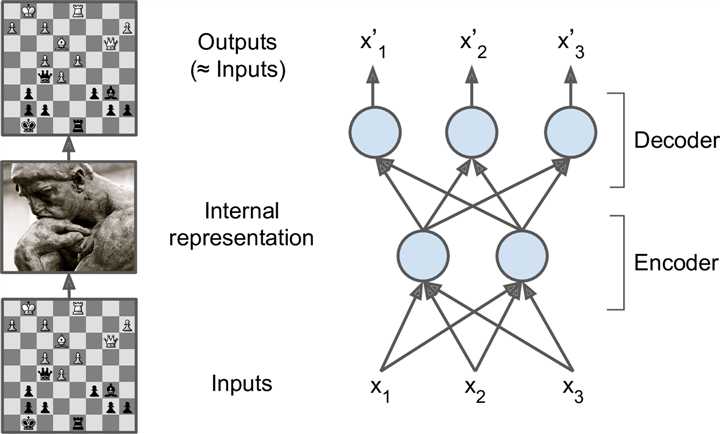
自编码器(autoencoder, AE)是一类在半监督学习和非监督学习中使用的人工神经网络,其功能是通过将输入信息作为学习目标,对输入信息进行表征学习.
自编码器包含编码器和解码器两部分。
一个自编码器接收输入,将其转换成高效的内部表示,然后再输出输入数据的类似物。
自编码器通常包括两部分:encoder(也称为识别网络)将输入转换成内部表示,decoder(也称为生成网络)将内部表示转换成输出。
从信息论的角度看,编码器可以看成是对输入信源的有损压缩。
深度神经网络既可以用于分类,也可以用于特征提取,而自编码器具有提取特征的作用。
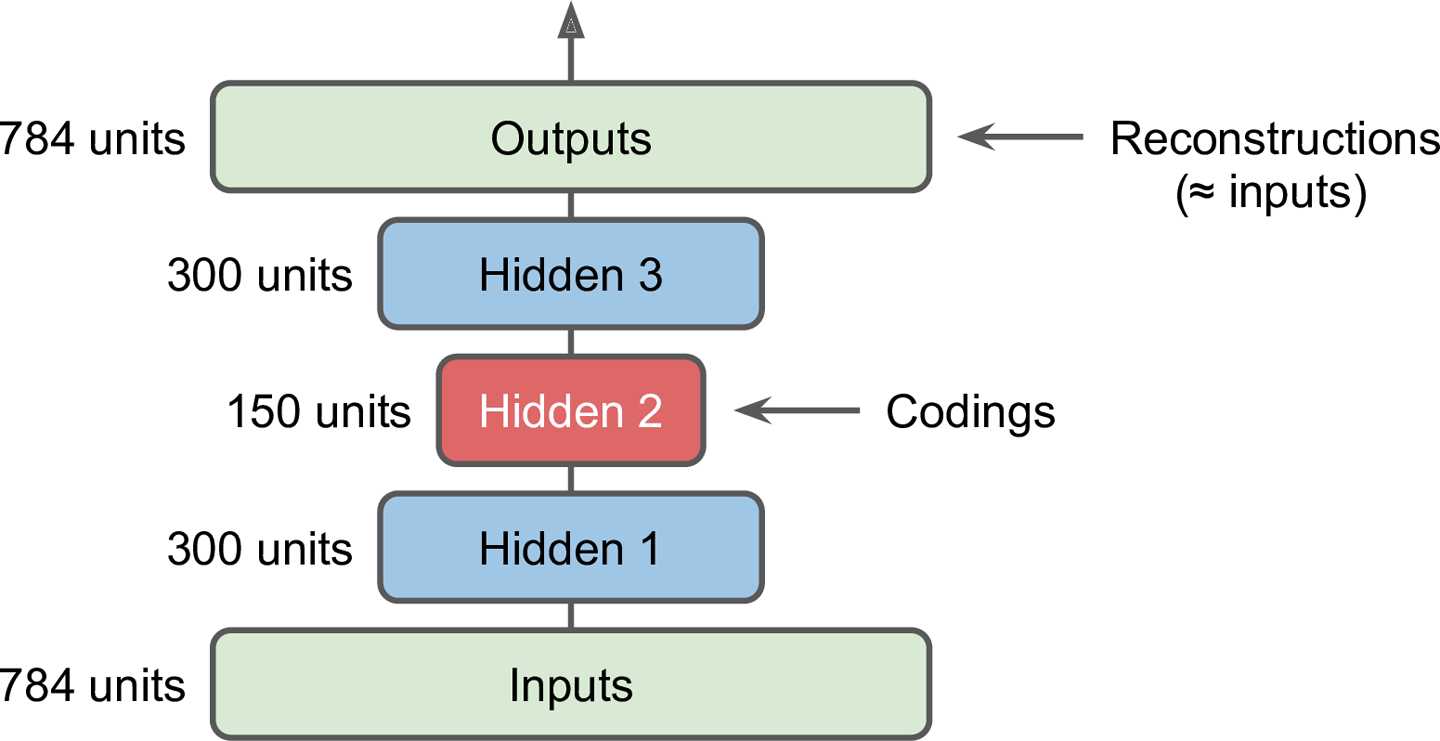
自编码器可以有多个隐层,这被称作栈式自编码器(或者深度自编码器)
增加隐层可以学到更复杂的编码,但也不能过于强大。
栈式自编码器的架构一般是关于中间隐层对称的。如果一个自编码器的层次是严格轴对称的,一个常用的技术是将decoder层的权重捆绑到encoder层。这使得模型参数减半,加快了训练速度并降低了过拟合风险。
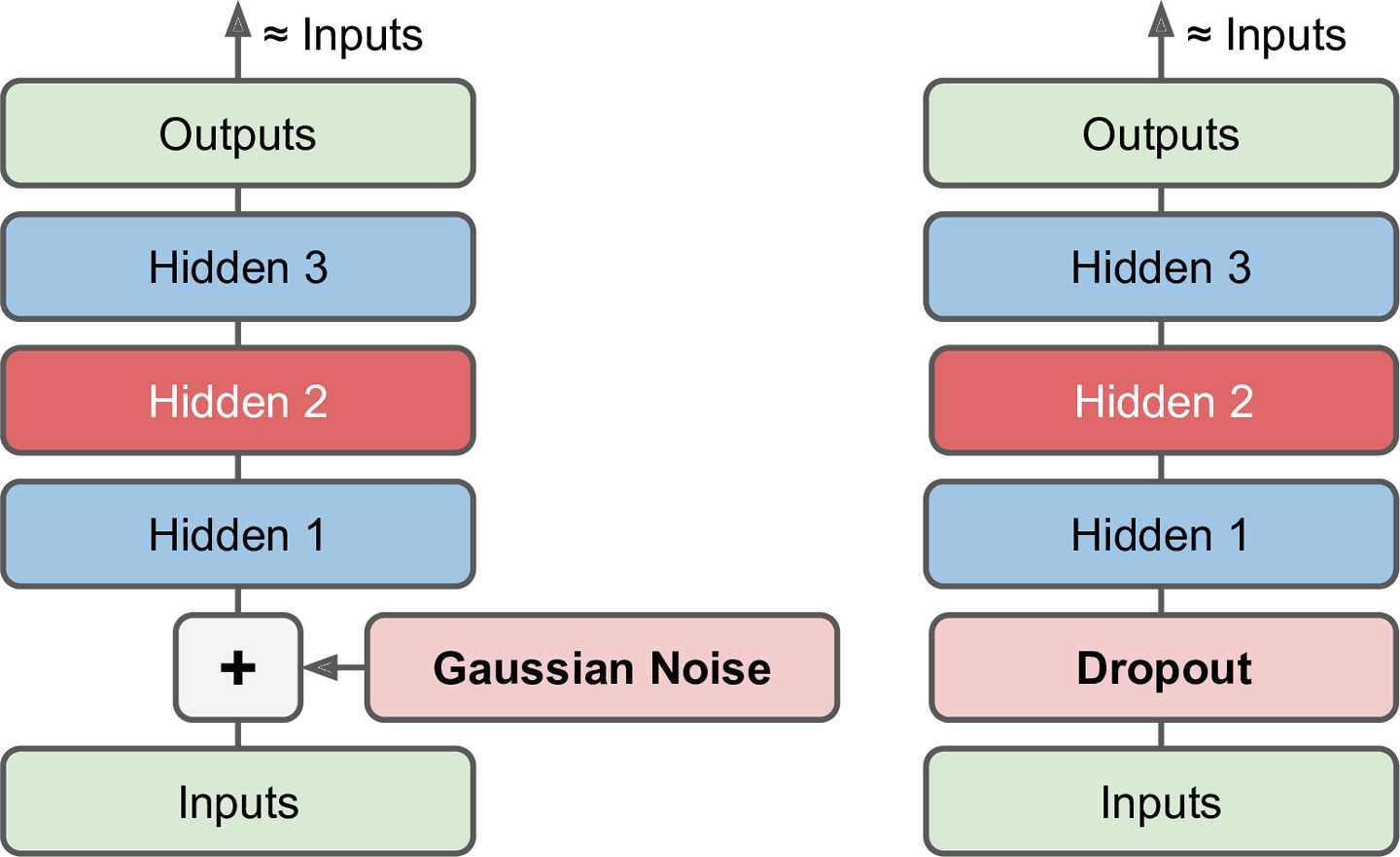
接受损坏数据作为输入,通过训练之后得到无噪声的输出的自编码器。
去噪自编码器要求对非理想数据的处理结果尽可能逼近原始数据,这防止了自编码器简单的将输入复制到输出,从而提取出数据中有用的模式。噪声可以是添加到输入的纯高斯噪声,也可以是随机丢弃输入层的某个特征,类似于dropout。

强化学习是智能系统从环境到行为的学习过程,智能体通过与环境的互动来发送自身的行为,改善准则是使某个累积奖励函数最大化。
强化学习是基于环境反馈实现决策制定的能用框架,根据不断试错得到来自环境的奖励或者惩罚,从而实现对趋我晚上信念的不断增强。强调在与环境的交互过程中实现学习,产生能获得最大利益的习惯性行为。
最常用的模式是马尔可夫决策过程。

马尔可夫决策过程(Markov Decision Processes,MDPs),简单说是一个智能体(Agent)采取行动从而改变自己的状态(State)获得奖励(Reward)与环境(Enviroment)发生交互的过程。
可以简单表示为\(M=<S,A,P_{s,a},R>\),基本概念如下:

是深度学习和强化学习的结合,将深度学习的感知能力和强化学习的决策能力融为一体,用深度学习的运行机制达到强化学习的优化目标,是一种更接近人类思维方式的人工智能方法。
深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,对感知问题束手无策。因此,将两者结合起来,优势互补,为复杂系统的感知决策问题提供了解决思路。按实施方式,分为以下三类
以上由chenqionghe整理,如有雷同,纯属巧合,light weight baby!
标签:实时 完成 限制 process rop 穷举 复杂 接受 特征
原文地址:https://www.cnblogs.com/chenqionghe/p/12641472.html