标签:交互式 分布 struct 跨行 空值 命名 处理 地方 范围
2003年,Google发表了“The Google File System”的论文。这个分布式文件系统简称GFS,它使用商用硬件集群存储海量数据。文件系统将数据在节点之间冗余复制,这样的话,即使一台存储服务器发生故障,也不会影响数据的可用性。它对数据的流式读取也做了优化,可以边处理边读取。
不久,Google又发表了"MapReduce:Simplified Data Processing on Large Clusters"的论文。MapReduce是GFS架构的一个补充,因为它能够充分利用GFS集群中的每个商用服务器提供的大量CPU。MapReduce加上GFS形成了处理海量数据的核心力量,包括构建Google的搜索索引。
不过,两个系统都缺乏实时随机存取数据的能力【这意味着尚不足以处理Web服务】。GFS的另一个缺陷是,它适合存储少许非常大的文件,而不适合存储数量众多的小文件。因为文件的元数据信息最终要存储在主节点的内存中,文件越多主节点的压力越大。
因此,Google尝试去找到一个能够驱动交互式应用的解决方案,例如,Google邮件或Google分析,能够同时利用这种基础结构、依靠GFS存储的数据冗余和数据可用性较强的特点。存储的数据应该拆分成特别小的条目,然后由系统将这些小记录聚合到非常大的存储文件中,并提供一些索引排序,让用户可以查找最少的磁盘就能够获取数据。最终,它应该能够及时存储爬虫的结果,并跟MapReduce协作构建搜索索引。
意识到RDBMS在大规模处理中的缺点,工程师开始考虑问题的其它切入点:摒弃关系型的特点,采用简单的API来进行增删改查操作,再加上一个扫描函数,在较大的键范围或全表范围上迭代扫描。这些努力的成果最终就是2006年的论文"BigTable:A Distributed Storage System for Structured Data"。BigTable是一个管理结构化数据的分布式存储系统,它可以扩展到非常大,如在成千上万的商用服务器上存储PB级的数据。一个稀疏的、分布式的、持久的多维排序映射。
最基本的单位是列,一列或多列形成一行,并由唯一的行键来确定存储。反过来,一个表中有若干行,其中每列可能有多个版本,在每一个单元格中存储了不同的值。除了每个单元格可以保留若干个版本的数据这一点外,整个结构看起来和典型的数据库没什么两样,但很明显,有比这更重要的因素。
所有的行按照行键字典顺序进行排序存储。例如:
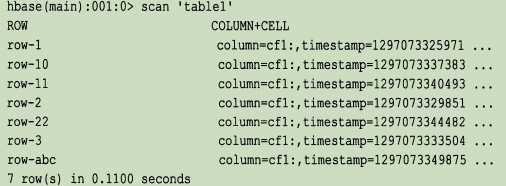
注意,排序的顺序可能和你预期的不一样,可能需要通过补键来获得正确排序。在字典顺序中,是按照二进制逐字节从左到右依次对比每一个行键【字符串顺序】。
按照行键排序可以获得像RDBMS的主键索引一样的特性,也就是说,行键总是唯一的,并且只出现一次,否则就是在更新同一行。虽然BigTable的论文只考虑了行键单一索引,但是HBase增加了对辅助索引的支持。行键可以是任意的字节数组,但它并不一定是人直接可读的。
一行由若干列组成,若干列又构成了一个列族,这不仅有助于构建数据的语义边界或者局部边界,还有助于给它们设置某些特征【如压缩】,或者指示它们存储在内存中。一个列族的所有列存储在同一个底层的存储文件中,这个存储文件叫做HFile。
列族需要在表创建是就定义好,并且不能修改得太频繁,数量也不能太多。在当前的实现中有少量已知的缺陷,这些缺陷使得列族数量只限于几十,实际上可能还小得多【3~5个】。列族名必须由可打印字符组成,这与其他名称或值的命名规范有显著不同。
常见的引用列的格式为列族:列,列是任意的字节数组。与列族的数量有限制相反,列的数量没有限制:一个列族里可以有数百万列。列值也没有类型和长度的限定。用可视化的方式展示普通数据库与列式HBase在行设计上的不同,行和列没有像经典的电子表格模型那样排列,而是采用了标签描述,也就是说,信息保存在一个特定的标签下。
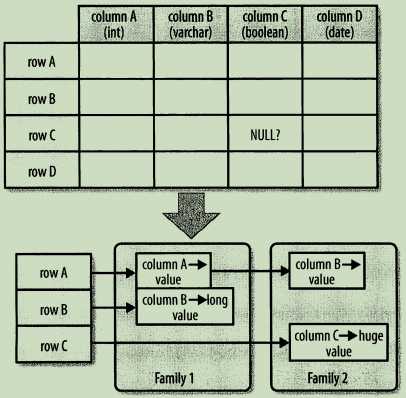
图中NULL?表明了固定模式的数据库在没有值的地方必须存储NULL值,但是在HBase的存储架构中,可以干脆省略整个列,换句话说,空值是没有任何消耗的,它们不占用任何存储空间。
所有列和行的信息都会通过列族在表中定义。
每一列的值或单元格的值都具有时间戳,默认由系统指定,也可以由用户显式设置。时间戳可以被使用,例如通过不同的时间戳来区分不同版本的值。一个单元格的不同版本的值按照降序排列在一起,访问的时候优先读取最新的值。这种优化的目的在于让新值比老值更容易被读取。
用户可以指定每个值所能保存的最大版本数。此外,还支持谓词删除,例如,允许用户只保存过去一周写入的值。这些值也只是未解释的字节数组,客户端需要知道怎样去处理这些值。
HBase是按照BigTable模型实现的,是一个稀疏的、分布式的、持久化的、多维的映射,由行键、列键和时间戳索引。因此有如下的数据存取模式:(Table,RowKey,Family, Column,Timestamp) -> Value或SortedMap<RowKey,List<SortedMap<Column,List<Value,Timestamp>>>>。
这个数据存取模型的一个有趣的特性是单元格可以存在多个版本,不同的列被写入的次数不同。API默认提供了一个所有列的统一视图,API会自动选择单元格的当前值。
基于时间样式的图解:
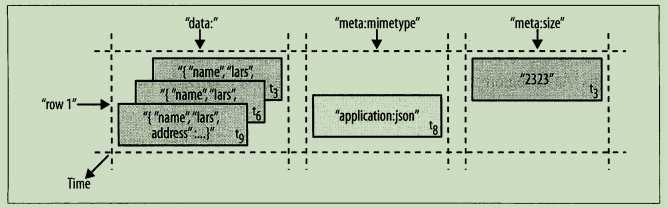
基于数据库表结构的图解:
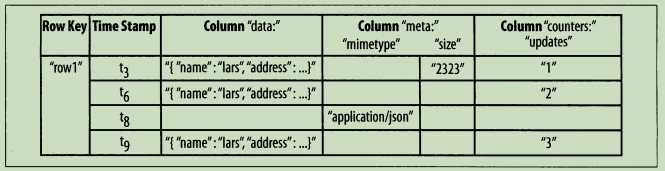
尽管这些值插入的次数不同,并且存在多个版本,但是仍然能将行看作是所有列以及这些列的最新版本【即每一列的最大tn】的组合。行数据的存取操作是原子的,可以读写任意数目的列。目前还不支持垮行事务和跨表事务。原子存取也是促成系统架构具有强一致性的一个因素,因为并发的读写可以对行的状态做出安全的假设。使用多版本和时间戳同样能够帮助应用层解决一致性问题。
HBase中扩展和负载均衡的基本单位称为region,region本质上是以行键排序的连续存储的区间。如果region太大,系统就会把它们动态拆分,相反地,就把多个region合并,以减少存储文件数量。
HBase中的region等同于数据库分区中用的范围划分。它们可以被分配到若干台物理服务器上以均摊负载,因此提供了较强的扩展性。
一张表初始的时候只有一个region,用户开始向表中插入数据时,系统会检查这个region的大小,确保其不超过配置的最大值。如果超过了限制,系统会在中间键【region中间的那个行键】处将这个region拆分成两个大致相等的子region。
每一个region只能由一台region服务器加载,每一台region服务器可以同时加载多个region。如图:
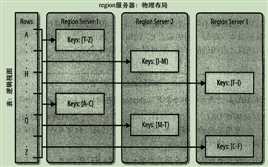
虽然HBase不支持在线的region合并,但是有离线处理合并的工具。
BigTable的论文中指出,每台服务器中region的最佳加载数量是10~1000,每个region的最佳大小是100MB~200MB。这个标准是以2006年以及更早以前的硬件配置为基准参数建议的。按照HBase和现在的硬件能力,每台服务器的最佳加载数量差不多还是10~1000,但每个region的最佳大小是1GB~2GB甚至更多。虽然数量增加了,但是基本原理还是一样的:每台服务器能加载的region数量和每个region的最佳存储大小取决于单台服务器的有效处理能力。
region拆分和服务相当于其他系统提供的自动分区。当一个服务器出现故障后,该服务器上的region可以 快速恢复,并获得细粒度的负载均衡,因为当服务于某个region的服务器当前负载过大、发生错误或者被停止使用导致不可用时,系统会将该region移到其他服务器上。
region拆分的操作也非常快,接近瞬间,因为拆分之后的region读取的仍然是原存储文件,直到合并把存储文件异步地写成独立的文件。
BigTable并不支持完整的关系数据模型,相反,它提供了具有简单数据模型的客户端,这个简单的数据模型支持动态控制数据的布局格式。
API提供了建表、删表、增加列族和删除列族操作,同时还提供了修改表和列族元数据的功能,如压缩和设置块大小。此外,它还提供了客户端对给定的行键值进行增加、删除和查找操作的功能。
scan API提供了高效遍历某个范围的行的功能,同时可以限定返回那些列或者返回的版本数。通过设置过滤器可以匹配返回的列,通过设置起始和终止的时间范围可以选择查询的版本。
在这些基本功能的基础上,还有一些更高级的特性。系统支持单行事务,基于这个特性,系统实现了对单个行键存储的数据的原子读-修改-写序列。虽然还不支持跨行和垮表的事务,但客户端已经能够支持批量操作以获得更好的性能。
单元格的值可以当作计数器使用,并且能够支持原子更新。这个计数器能够在一个操作中完成读和修改,因此尽管是分布式的系统架构,客户端依然可以利用此特性实现全局的、强一致性的、连续的计数器。
还可以在服务器的地址空间中执行来自客户端的代码,支持这种功能的服务端框架叫做协处理器【HBase在0.91.0版本中加入了协处理器】。这个代码能直接访问服务器本地的数据,可以用于实现轻量级批处理作业,或者使用表达式并基于各种操作来分析或汇总数据。
最后,系统通过提供包装器集成了MapReduce框架,该包装器能够将表转换成MapReduce作业的输入源和输出目标。
与RDBMS不同,HBase系统没有提供查询数据的特定域语言,例如SQL。数据存取不是以声明的方式完成的,而是通过客户端API以纯粹的命令完成的。HBase的API主要是Java代码,但是也可以用其它编程语言来存取数据。
BigTable允许客户端推断在底层存储中表示的数据的位置属性。数据存储在存储文件中,称为HFile,HFile中存储的是经过排序的键值对映射结构。文件内部由连续的块组成,块的索引信息存储在文件的末尾。当把HFile打开并加载到内存中时,索引信息会优先加载到内存中,每个块的默认大小是64KB,可以根据需要配置不同的块大小。存储文件提供了一个设定起始和终止行键范围的API用于扫描特定的值。
每一个HFile都有一个块索引,通过一个磁盘查找就可以实现查询。首先,在内存的块索引中进行二分查找,确定可能包含给定键的块,然后读取磁盘块找到实际要找的键。存储文件通常保存在Hadoop分布式文件系统中,HDFS提供了一个可扩展的、持久的、冗余的HBase存储层。存储文件通过将更改写入到可配置数目的物理服务器中,以保障不丢失数据。
每次更新数据时,都会先将数据记录在提交日志中,在HBase中这叫做预写日志【write-ahead log,WAL】,然后才会将这些数据数据写入内存中的memstore中。一旦内存保存的写入数据的累计大小超过了一个给定的最大值,系统就会将这些数据移出内存作为HFile文件刷写到磁盘中。数据移出内存之后,系统会丢弃对应的提交日志,只保留未持久化到磁盘中的提交日志。在系统将数据移出memstore写入磁盘的过程中,可以不必阻塞系统的读写,通过滚动内存中的memstore就能达到这个目的,即用空的新memstore获取更新数据,将满的旧memstore转换成一个文件。请注意,memstore中的数据已经按照行键排序,持久化到磁盘中的HFile也是按照这个顺序排列的,所以不必执行排序或其他特殊处理。
标签:交互式 分布 struct 跨行 空值 命名 处理 地方 范围
原文地址:https://www.cnblogs.com/yszd/p/12632995.html