标签:自动 文本处理 去掉 base64编码 png 参数 mic safe 二进制
用64个字符来表示任意二进制数据
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。
然后,对二进制数据进行处理,每3个字节一组,一共是3x8=24bit,划为4组,每组正好6个bit
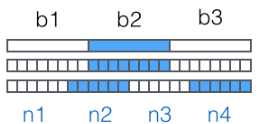
这样我们得到4个数字作为索引,然后查表,获得相应的4个字符,就是编码后的字符串。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
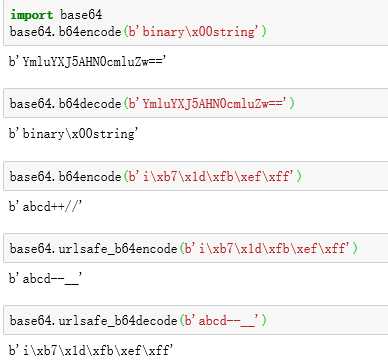
base64.b64encode()
base64.b64decode()
base64.urlsafe_b64encode()
base64.urlsafe_b64decode()
 标准的Base64编码后可能出现字符
标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符+和/分别变成-和_
=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉:Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
def safe_base64_decode(s):
while len(s)%4 !=0:
s=s+b‘=‘
return base64.b64decode(s)
assert b‘abcd‘ == safe_base64_decode(b‘YWJjZA==‘), safe_base64_decode(‘YWJjZA==‘)
assert b‘abcd‘ == safe_base64_decode(b‘YWJjZA‘), safe_base64_decode(‘YWJjZA‘)
print(‘ok‘)
标签:自动 文本处理 去掉 base64编码 png 参数 mic safe 二进制
原文地址:https://www.cnblogs.com/soberkkk/p/12655377.html