标签:sla 参数 routing boot 初始化 path network 作用 conf
集群
一个集群cluster由一个或者多个节点组成,具有相同的cluster.name,协同工作,分项数据和负载。当有新的节点加入或者删除了一个节点时,集群回感知到并能够平衡数据。ElasticSearch中可以监控很多信息,有一个最重要的就是集群健康。集群健康有三个状态:green(所有主要分片和复制分片都可用),yellow(所有主要分片可用,但不是所有复制分片都可用),red(不是所有的主要分片都可用)。
节点
一个节点node就是一个ElasticSearch的实例。 集群中的一个节点会被选举为主节点master,它将临时管理集群级别的一些变更,譬如新建或者删除索引、增加或者移除节点等等。主节点不参与文档级别的变更或者搜索,所以不会成为集群的瓶颈。任何节点都可以成为主节点。 用户能够与集群中的任何节点通信,包括主节点。每一个节点都知道文档存在于哪个节点上,可以转发请求到相应的节点上。
分片
一个分片shard是一个最小级别的工作单元,es把一个完整的索引分成多个分片。仅保存了索引中所有数据的一部分。 分片就是一个Lucene实例,并且它本身就是一个完整的搜索引擎。 文档存储在分片中,并且在分片中被索引,但是程序不会直接与分片通信,而是与索引通信。
Replicas分片:代表索引副本。es可以设置多个索引的副本,副本的作用是提高了系统的容错性。当某个节点的分片损坏或者丢失的时候可以从副本中恢复。还可以提高查询搜索效率,es会自动对搜索请求进行负载均衡。
| 参数 | 说明 |
|---|---|
| cluster.name: ES | ES集群名称,同一个集群内的所有节点集群名称必须保持一致 |
| node.name: slave2 | ES集群内的节点名称,同一个集群内的节点名称要具备唯一性 |
| node.master: true | 允许节点是否可以成为一个master节点,ES是默认集群中的第一台机器成为master,如果这台机器停止就会重新选举 |
| node.data: false | 允许该节点存储索引数据(默认开启) |
| path.data: | ES是搜索引擎,会创建文档,建立索引,此路径是索引的存放目录.可以指定多个存储位置 |
| path.logs: | elasticsearch专门的日志存储位置 |
| bootstrap.memory_lock: true | 在ES运行起来后锁定ES所能使用的堆内存大小,锁定内存大小一般为可用内存的一半左右;锁定内存后就不会使用交换分区。如果不打开此项,当系统物理内存空间不足,ES将使用交换分区,ES如果使用交换分区,那么ES的性能将会变得很差 |
| network.host: 0.0.0.0 | es的HTTP端口和集群通信端口就会监听在此地址上 |
| network.tcp.no_delay: true | 是否启用tcp无延迟,true为启用tcp不延迟,默认为false启用tcp延迟 |
| truenetwork.tcp.keep_alive: true | 是否启用TCP保持活动状态,默认为true |
| network.tcp.reuse_address: true | 是否应该重复使用地址。默认true,在Windows机器上默认为false |
| network.tcp.send_buffer_size: 128mb | tcp发送缓冲区大小,默认不设置 |
| network.tcp.receive_buffer_size: 128mb | tcp接收缓冲区大小,默认不设置 |
| transport.tcp.port: 9301 | 设置集群节点通信的TCP端口,默认就是9300 |
| transport.tcp.compress: true | 设置是否压缩TCP传输时的数据,默认为false |
| http.max_content_length: 200mb | 设置http请求内容的最大容量,默认是100mb |
| http.cors.enabled: true | 是否开启跨域访问 |
| http.cors.allow-origin: "*" | 开启跨域访问后的地址限制,*表示无限制 |
| http.port: 9201 | 定义ES对外调用的http端口,默认是9200 |
| discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"] | 在Elasticsearch7.0版本已被移除,配置错误。写入候选主节点的设备地址,来开启服务时就可以被选为主节点。默认主机列表只有127.0.0.1和IPV6的本机回环地址。上面是书写格式,discover意思为发现,zen是判定集群成员的协议,unicast是单播的意思,ES5.0版本之后只支持单播的方式来进行集群间的通信,hosts为主机 |
| discovery.zen.minimum_master_nodes: 2 | 在Elasticsearch7.0版本已被移除,配置无效,为了避免脑裂,集群的最少节点数量为,集群的总节点数量除以2加一 |
| discovery.zen.fd.ping_timeout: 120s | 在Elasticsearch7.0版本已被移除,配置无效。探测超时时间,默认是3秒,我们这里填120秒是为了防止网络不好的时候ES集群发生脑裂现象 |
| discovery.zen.fd.ping_retries: 6 | 在Elasticsearch7.0版本已被移除,配置无效。探测次数,如果每次探测90秒,连续探测超过六次,则认为节点该节点已脱离集群,默认为3次 |
| discovery.zen.fd.ping_interval: 15s | 在Elasticsearch7.0版本已被移除,配置无效。节点每隔15秒向master发送一次心跳,证明自己和master还存活,默认为1秒太频繁 |
| discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"] | Elasticsearch7新增参数,写入候选主节点的设备地址,来开启服务时就可以被选为主节点,由discovery.zen.ping.unicast.hosts:参数改变而来 |
| cluster.initial_master_nodes: ["127.0.0.1:9301","127.0.0.1:9302"] | Elasticsearch7新增参数,写入候选主节点的设备地址,来开启服务时就可以被选为主节点 |
| cluster.fault_detection.leader_check.interval: 15s | Elasticsearch7新增参数,设置每个节点在选中的主节点的检查之间等待的时间。默认为1秒 |
| discovery.cluster_formation_warning_timeout: 30s | Elasticsearch7新增参数,启动后30秒内,如果集群未形成,那么将会记录一条警告信息,警告信息未master not fount开始,默认为10秒 |
| cluster.join.timeout: 30s | Elasticsearch7新增参数,节点发送请求加入集群后,在认为请求失败后,再次发送请求的等待时间,默认为60秒 |
| cluster.publish.timeout: 90s | Elasticsearch7新增参数,设置主节点等待每个集群状态完全更新后发布到所有节点的时间,默认为30秒 |
| cluster.routing.allocation.cluster_concurrent_rebalance: 32 | 集群内同时启动的数据任务个数,默认是2个 |
| cluster.routing.allocation.node_concurrent_recoveries: 32 | 添加或删除节点及负载均衡时并发恢复的线程个数,默认4个 |
| cluster.routing.allocation.node_initial_primaries_recoveries: 32 | 初始化数据恢复时,并发恢复线程的个数,默认4个 |
CentOS7.3 Elasticsearch7.1
解压 Elasticsearch,并在复制两份
分别在elasticsearch/config下找到elasticsearch.yml增加如下配置
主节点配置
cluster.name: "es"
node.name: master
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9201
transport.tcp.port: 9301
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
cluster.initial_master_nodes: ["127.0.0.1:9301"]
http.cors.enabled: true
http.cors.allow-origin: "*"
从节点1
cluster.name: "es"
node.name: slave1
node.master: false
node.data: true
network.host: 0.0.0.0
http.port: 9202
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
cluster.initial_master_nodes: ["127.0.0.1:9301"]
http.cors.enabled: true
http.cors.allow-origin: "*"
从节点2
cluster.name: "es"
node.name: slave2
node.master: false
node.data: true
network.host: 0.0.0.0
http.port: 9203
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
cluster.initial_master_nodes: ["127.0.0.1:9301"]
http.cors.enabled: true
http.cors.allow-origin: "*"
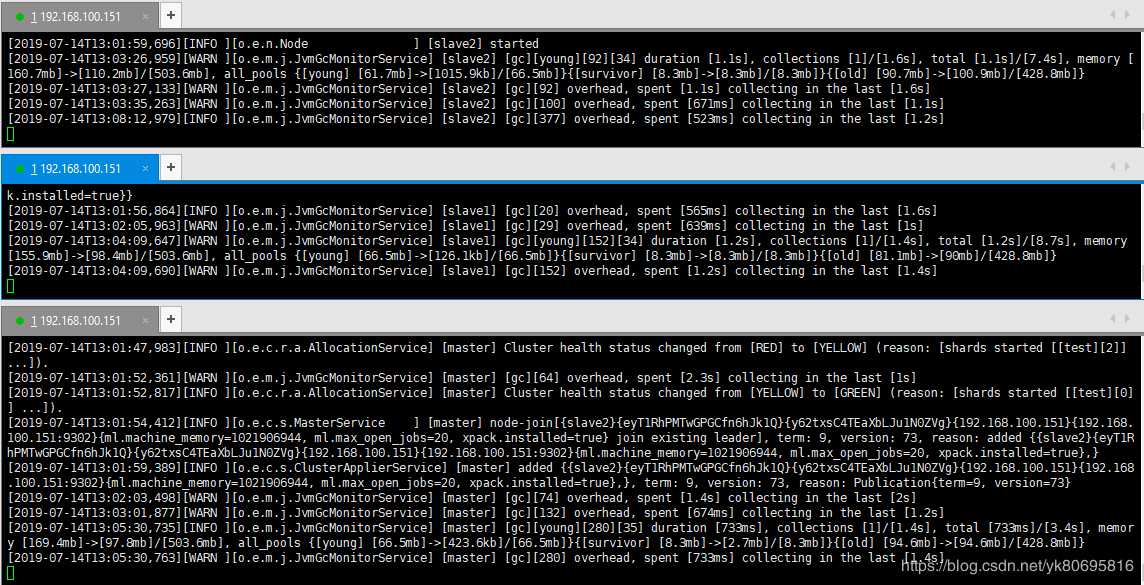

粗框是主节点,细框是从节点
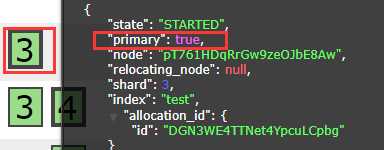
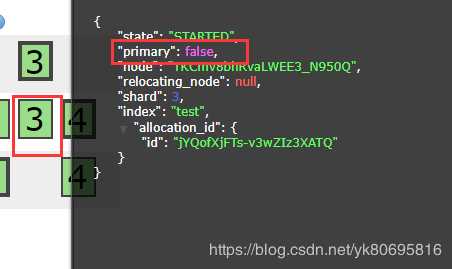
在搭建集群的过程中,每次第一个节点开始完成,在开启第二个节点的时候。第一个节点进程会被杀死。看了ES日志也没有发现报错。后来找到原因:需要修改ES中config目录下的jvm.options文件。
vi jvm.options
-Xms 1g
-Xmx 1g
修改为
-Xms 512m
-Xmx 512m
标签:sla 参数 routing boot 初始化 path network 作用 conf
原文地址:https://www.cnblogs.com/yangk1996/p/12657691.html