标签:例子 创建 import 其它 names pre 因此 gre 系统
通用唯一识别码(Universally Unique Identifier,缩写:UUID)是用于让分布式系统中的所有元素都能有唯一的识别信息。如此一来,每个人都可以创建不与其它人冲突的 UUID,就不需考虑数据库创建时的名称重复问题还有相关的术语:全局唯一标识符(GUID)。
version 1, date-time & MAC address(时间戳和MAC地址)
version 2, date-time & group/user id (时间戳和组或用户ID)
version 3, MD5 hash & namespace (散列(hashing)命名空间和名称)
version 4, pseudo-random number ((伪)随机数)
version 5, SHA-1 hash & namespace (散列(hashing)命名空间和名称)
版本3使用 MD5 作为散列算法,版本5使用 SHA1。推荐版本5(SHA1)而不是版本3(MD5),建议不要使用任一版本的 UUID 作为安全凭证。这5个版本使用不同算法,利用不同的信息来产生UUID,各版本有各自优势,适用于不同情景。
UUID是由一组32位数的16进制数字所构成,故UUID理论上的总数为1632=2128,约等于3.4 x 1038。也就是说若每纳秒(ns)产生1兆个UUID,要花100亿年才会将所有UUID用完。
UUID的标准型式包含32个16进制数字,以连字号分为五段,形式为 8-4-4-4-12 的32个字符。示例:
550e8400-e29b-41d4-a716-446655440000
UUID "8-4-4-4-12" 形式中总共 36 个字符(32 个字母数字字符和 4 个连字符)。例如:
123e4567-e89b-12d3-a456-426655440000
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
M表示 UUID 版本,N的一至三个最高有效位表示 UUID 变体。在例子中,M 是 1 而且 N 是 a(10xx),这意味着此 UUID 是“版本1”、“变体1”UUID;即基于时间的 DCE/RFC 4122 UUID。
在 103 万亿 个 版本4 UUID 中找到重复的概率是 1/1000000000 十亿分之一。
产生重复 UUID 并造成错误的情况非常低,大可不必考虑此问题。
UUID 通常用作数据库表的主键。
MySQL 提供了一个 UUID() 函数,它生成标准 版本1 UUID。
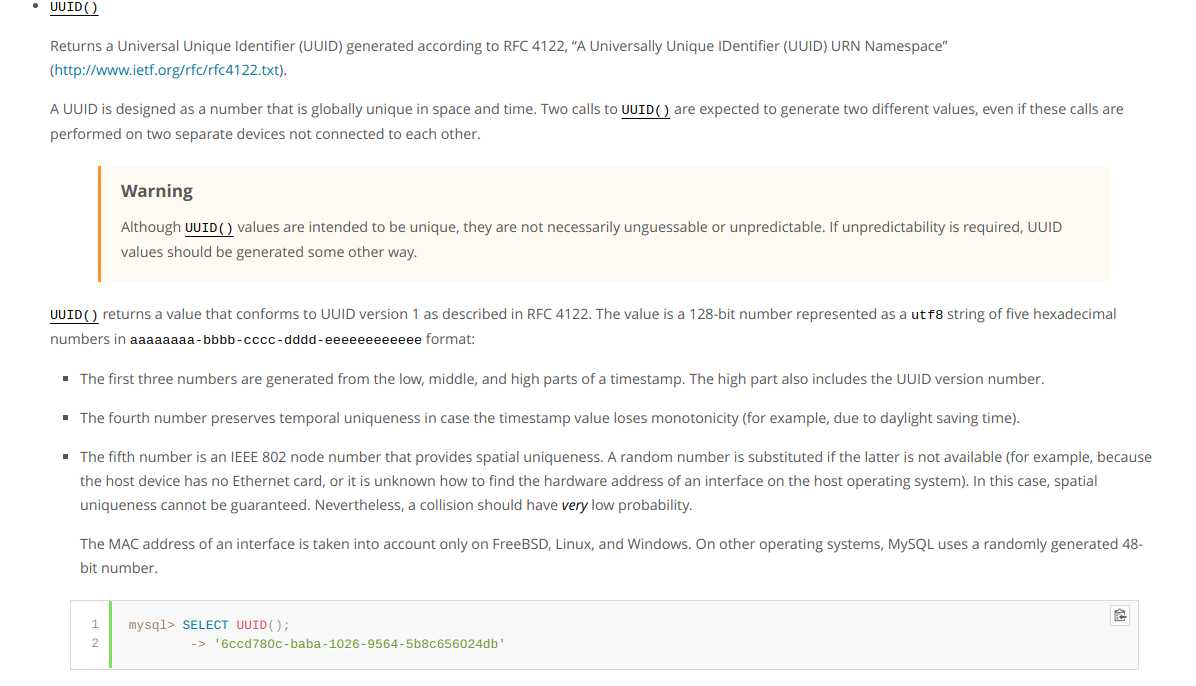
PostgreSQL 包含一个 UUID 数据类型,并且可以通过使用模块中的函数生成大多数版本的UUID。
import uuid
print(uuid.uuid1()) # 版本一:时间戳和MAC地址
# 51927c2a-7974-11ea-953f-54e1adeabc32 54e1adeabc32是MAC地址
print(uuid.uuid3(uuid.NAMESPACE_OID, ‘timeashore‘)) # 版本三:散列(MD5)命名空间和名称
# b92ac374-c149-35ba-9ed4-f8b4d9cd8e85
print(uuid.uuid4()) # 版本四:随机数
# 4d9c6aa2-95fa-4ac4-b30d-a520bf5684f2
print(uuid.uuid5(uuid.NAMESPACE_OID, ‘timeashore‘)) # 版本五:散列(SHA1)命名空间和名称
# 6e107881-f2ef-5a1e-a458-1c8047070e08
RFC 4122 保留了“DCE security” UUID 的“版本2”;但它没有提供任何细节。因此,许多 UUID 实现省略了“版本2”。
使用较多的是版本1和版本4,因为时间戳和随机数的唯一性,版本1和版本4总是生成唯一的标识符。若希望对给定的一个字符串总是能生成相同的 UUID,使用版本3或版本5。(soc用的随机数)
标签:例子 创建 import 其它 names pre 因此 gre 系统
原文地址:https://www.cnblogs.com/ldy-miss/p/12661305.html