标签:封装 info 次数 strlen beef alt blog tip tps
BF算法,即暴风(Brute Force)算法,是普通的模式匹配算法,不是要匹配字符吗?那我一个一个直接匹配不就好啦。BF算法的思想就是将目标串 S 的第一个字符与模式串 T 的第一个字符进行匹配,若相等,则继续比较 S 的第二个字符和 T 的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。
代码实现:
#include <string.h>
int BF(const char* str, const char* sub, int pos)//O(n*m)
{
int i = pos;
int j = 0;
while (i < strlen(str) && j < strlen(sub))
{
if (str[i] == sub[j]) //同时移动 i 和 j
{
i++;
j++;
}
else
{
i = i - j + 1; //i 退回到当前匹配失败的字符串第一个字符的下一个
j = 0; //j 回退到 0,即回溯
}
}
if (j >= strlen(sub)) //匹配
return i - j;
else //失配
return -1;
}
假设我们的目标串是 “abcdefgab……”,模式串是 “abcde&”,那么使用 BF 算法匹配流程如下所示。
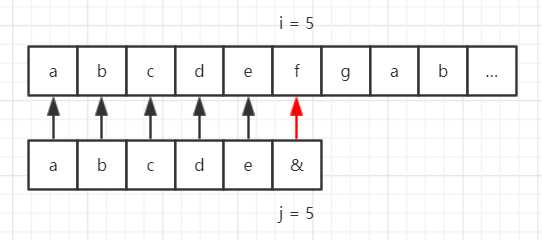
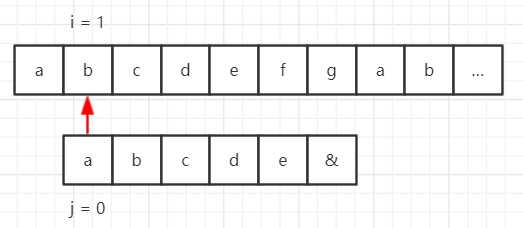
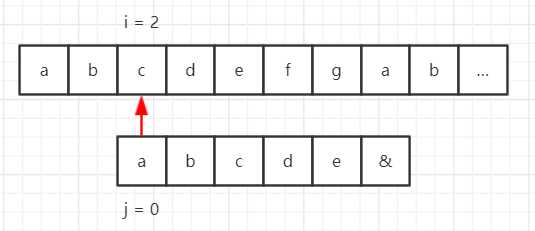
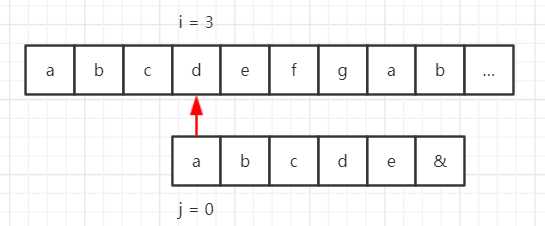
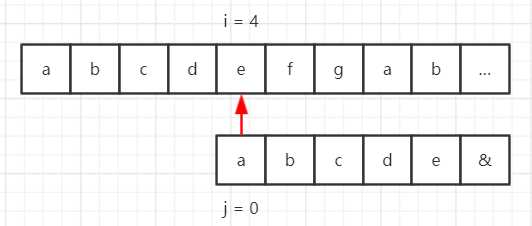
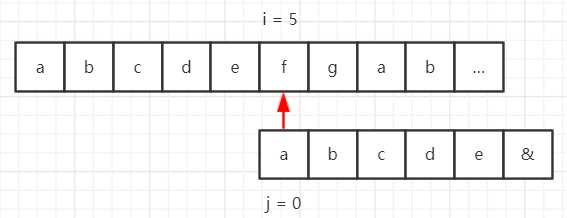
但是在模式串中,第一个字符 “a” 与后面的字符 “bcde&” 都不一样,也就是说对于第一步,前 5 位字符都匹配成功了,那么 “a” 与目标串中的第 2~5 个字符一定不能匹配,那么流程就可以缩减成这样:
再看个例子,假设我们的目标串是 “abcababca……”,模式串是 “abcab&”,那么使用 BF 算法匹配流程如下所示。
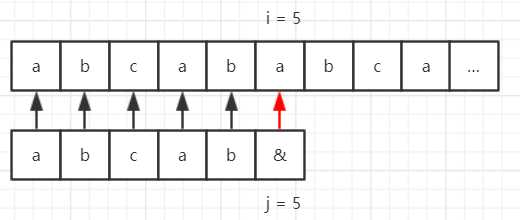
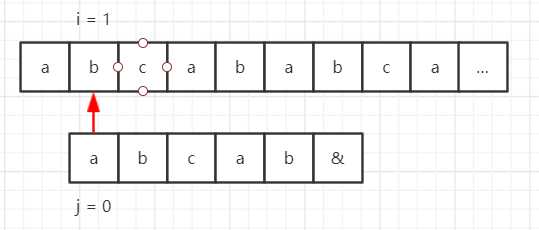
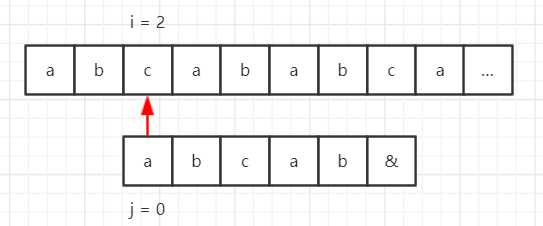
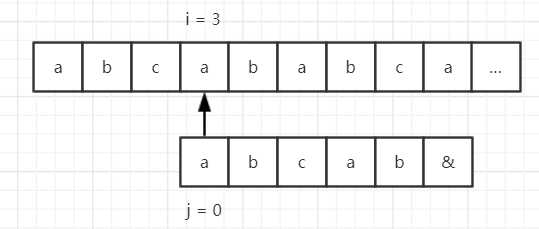
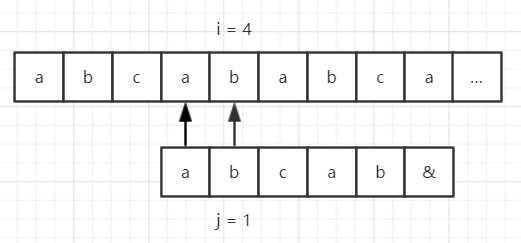
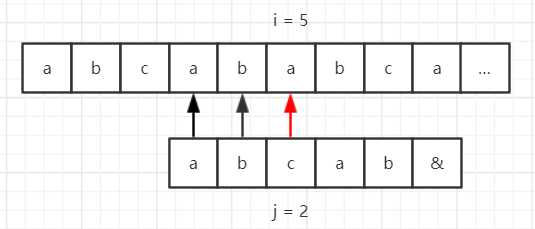
因为模式串中的第一位和第四位的字符都是 “a”,第二位和第五位字符都是 “b”,而第四位和第五位在第一步的时候已经匹配成功了,因此匹配的过程可以简化为:
那么这种思想就是 KMP 算法,这种算法的思想是为了让不必要的回溯不发生。
KMP 算法是一种改进的字符串匹配算法,由 D.E.Knuth,J.H.Morris 和 V.R.Pratt 提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称 KMP 算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个 next() 函数实现,函数本身包含了模式串的局部匹配信息。KMP 算法的时间复杂度 O(m+n)。
int KMP(string str, string t, int pos)
{
int i = pos; //从字符串的 pos 下标开始匹配
int j = 0; //用于描述模式串 t 的下标
int next[t.size()];
getNext(t, next);
while (i <= str.size() && i <= t.size())
{
if (j == -1 || str[i] == t[j]) //两字符相等,继续判断
{
i++;
j++;
}
else //不相等,回溯
{
j = next[j];
}
}
if (j > t.size())
return i - t.size;
else
return -1;
}
void getNext(string t,int next[])
{
int i = 0,j = -1;
next[0] = -1;
while(i < t.size())
{
if(j == -1 || t[i] == t[j]) //匹配前缀和后缀
{
i++;
j++;
next[i] = j;
}
else
j = next[j]; //字符不相同,回溯
}
}
如果你不是很懂 KMP 算法具体是怎么实现的也没关系,先理解算法的思想即可。
左转我的另一篇博客字典树 (Trie)
AC 自动机(Aho-Corasick automaton)算法在 1975 年产生于贝尔实验室,是著名的多模匹配算法,时间复杂度为 O(n),n 为文本串长度。那么啥是多模匹配算法嘞?相信你已经理解了 KMP 算法的思想,KMP 算法是一种单模匹配算法,即一段模式串匹配一段字符串。所谓多模匹配算法就是多段模式串匹配一段字符串,例如给出 n 个单词,再给出一段包含 m 个字符的英文文章,让你利用算法找出有多少个单词在文章里出现过,这就是一个多模匹配的过程。
那么问题来了,我们可以连续使用 KMP 算法 n 次,每次匹配一个模式串,这样也可以实现多模匹配,但是这么做时间复杂度无疑是很大的,特别是当模式串很多,英文文章很长的情况下,那匹配的次数就太多次啦。作为一个懒人,我们总是很喜欢搞点手法,让我们能够在尽可能少的次数中完成多模式匹配啦,最理想的情况是一次匹配就完成任务。

那么问题来了,想要一次匹配成功,也就是说需要一次匹配所有模式串,难道我们需要一个字符分别拿每个模式串上去匹配吗?要不直接开个多线程好了(笑),这显然不是很好的想法。我们的目标是,用一种结构将所有模式串组织起来,然后匹配时就拿组织好的这一个结构进去匹配喽!盲猜一下,我们用什么结构去组织,对于单模匹配,我们使用的是顺序表,字符之间是一对一的关系,既然要组织多个模式串,应该是要用一对多的结构去组织吧(还不需要把图结构祭出来啊)。
你说巧不巧,我们刚学习了字典树,字典树就是一种用于组织多个字符串的树结构啊。例如有 "a","apple","appeal","appear","bee","beef","cat" 7 个模式串,就能够组织成如图所示字典树,就把一个所有模式串都组织到一个结构中啦。
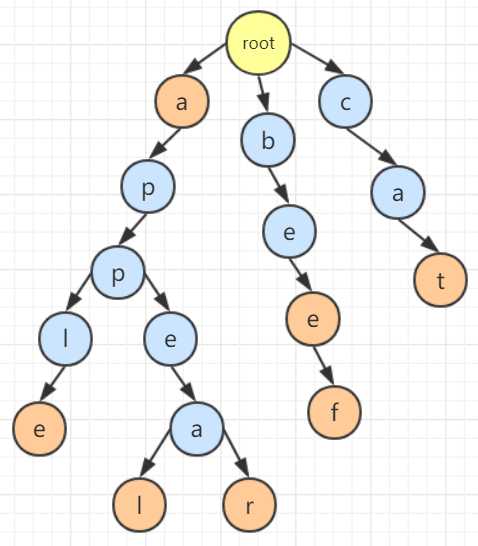
typedef struct Node
{
Node* next[26]; //结点的后继,最多有 26 个
Node* fail; //失配指针
bool flag; //判断单词结尾的 flag
}Node, * Trie;
其实就是字典树的插入算法啦,不过我们还有个还没介绍的失配指针需要初始化,所以要稍微改装一下。这里和我的另一篇博客的不同在于,这里使用了链式存储,不过思想是一样的。

void buildTrie(Trie root, string a_word) //建 Trie
{
Trie pre = root;
Trie ptr;
int order;
for (int i = 0; i < a_word.size(); i++)
{
order = a_word[i] - ‘a‘; //获取字母在字母表中的顺序
if (pre->next[order] == NULL) //字母序对应的后继不存在
{
ptr = new Node; //初始化新结点
for (int j = 0; j < 26; j++)
ptr->next[j] = NULL;
ptr->fail = NULL;
ptr->flag = false;
pre->next[order] = ptr; //插入新结点
}
pre = pre->next[order]; //以新节点作为下一次循环的根结点
}
pre->flag = true; //修改 flag 表示为单词结尾
}
接下来就是解决如何匹配的问题了,还记得我们是怎么在单模匹配中减少不必要的匹配的吗?使用** KMP 算法**,通过 KMP 算法的 next 数组,使得每次失配之后可以直接回溯到不重复的位置继续匹配,就不需要移动被匹配的字符串了。在这种思想的引导下,我们需要解决的是,找到一种算法,能够帮助我们在一个树结构中准确地找到适当的回溯位置,即可避免不必要的匹配了。
我们的目的是,希望在匹配多个模式串时不发生不必要的回溯,实现类似于 KMP 算法的机制,在匹配一个模式串时发生失配,能够从该字符自动跳转到另一段模式串,目标模式串时从根结点开始具有与失配的模式串的某个后缀字符串完全相同的前缀字符串。这种机制在 AC 自动机中被称为失配指针,失配指针是 AC 自动机算法的核心。
失配指针的原理是,如果文本与某一个模式串失配失配,则说明文本自上一个单词到此为止,中间不存在任何单词。此时若模式串中的任何后缀字符串都不为其他模式串的前缀字符串,则失配结点处的失配指针指向 root,表示下一轮匹配回溯至根结点。若当前模式串具有与某一模式串的前缀字符串相同的后缀字符串,就通过失配指针进行模式串的跳跃,使得匹配不需要回溯。我们通过一个例子来理解一下:
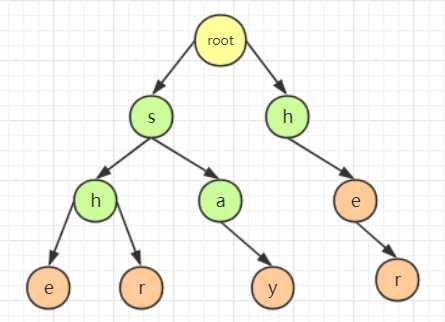
如图是用 5 个模式串:**"she","he","say","shr","her" **所建的字典树,通过分析可知,"she" 具有后缀字符串 "he","her" 具有前缀字符串,因此当 "she" 模式串发生失配的时候,就可以通过失配指针继续匹配 "her" 模式串,那么就需要将 "she" 中的 "h" 结点的失配指针指向 "her" 的 "h" 结点,将 "she" 中的 "e" 结点的失配指针指向 "her" 的 "e" 结点。至于其他的结点,由于不存在共有的前缀字符串和后缀字符串,因此它们的失配指针指向根结点。因此对于如图字典树,失配指针的关系如图所示:
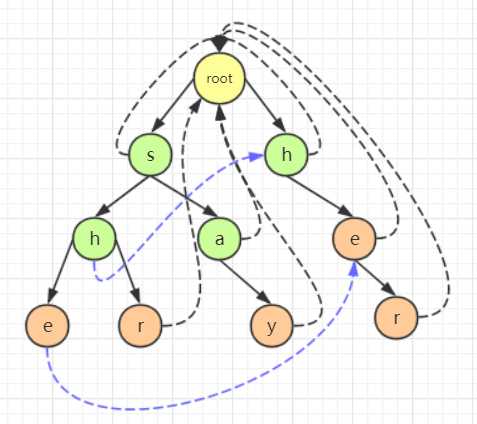
通过分析可以得知,进行跳转的另一个模式串的结点深度一定小于跳转之前的结点的深度,这是因为若跳转后的结点深度小于原结点的深度,就无法保证跳转后模式串的前缀字符串与进行跳转的模式串的后缀字符串相匹配,这样结点数量完全不够。
例如上文的例子中,通过失配指针联系的 "she" 中的 "h" 结点和 "her" 的 "h" 结点(蓝色标出)中前者的层数大于后者, "she" 中的 "e" 结点和 "her" 的 "e" 结点(紫色标出)中前者的层数也大于后者:
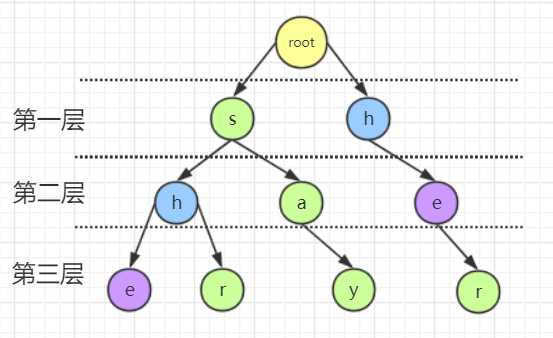
根据这个特点,我们可以通过访问当前结点的双亲结点的方式进行试探,对于某一个字母结点(原字母),通过对其双亲的失配指针的访问,寻找到其他的结点,这个结点满足其孩子结点中存在与原字母相同的结点,此时就把原字母结点的失配指针指向寻找到的结点中与原字母相同的孩子结点。若访问到了根结点,没有发现符合要求的结点,则失配指针指向根结点。

为什么这么做可行?因为我们组织模式串使用了字典树,如果失配指针指向的是同一层的结点,显然指向的结点肯定不是当前模式串的后缀字符串的一部分,也就是说如果是同层的话,这两个结点会重合,即为同一个结点,这也就是字典树构造时会将所有单词中相同前缀的前缀字符串用相同的结点来描述的特点。因此所有失配指针指向的结点不可能是另一个与自己深度相同的节点,通过失配指针访问时只能访问比当前深度小的结点。通过结点的双亲来探测失配指针的指向,就可以保证通过失配指针访问的位置的模式串长度小于当前被匹配的模式串。
例如对于 "she" 中的 "h" 结点,其双亲是 "s" 结点,"s" 结点的失配指针指向根结点,而根节点具有与 "h" 结点相同的孩子结点,因此就可以利用失配指针构成联系:
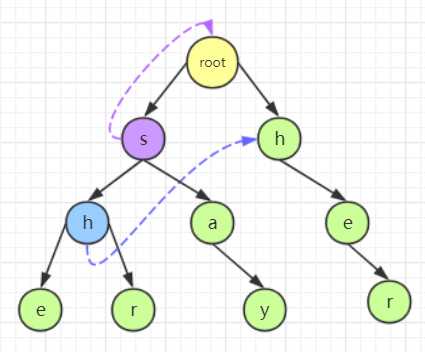
那么我们使用什么样的算法来实现这个过程?因为我们需要访问某个结点的双亲的失配指针,因此就需要保证双亲的失配指针有意义,而对于第一层结点而言,其双亲是根结点无需操作。因此对于失配指针的设置具体要保证层数在上层的结点先构造失配指针,下层的结点后构造失配指针。你有什么想法?你有没有感觉这个过程和我们做队列实现迷宫寻路和二叉树的层序遍历一模一样啊!都是从内层到外层一层一层探测,因此我们就明白了,我们需要使用广度优先搜索的思想来进行构造,因此就需要一个队列,先把根结点加入队列,并设置其的失配指针指向自己或者 NULL,之后每构造一个结点的失配指针,就连带将其子结点入队列。

void disposeFail(Trie root) //配置失配指针
{
queue<Trie> que;
Trie ptr;
Trie pre;
que.push(root); //根结点入队列
while (!que.empty())
{
pre = que.front();
que.pop(); //队列头出队列
ptr = NULL;
for (int i = 0; i < 26; i++)
{
if (pre->next[i] != NULL) //挖掘存在的后继
{
if (pre == root) //pre 和 root 处在同一层,失配指针为 root
{
pre->next[i]->fail = root;
}
else
{
ptr = pre->fail; //ptr 为其的双亲的失配指针
while (ptr != NULL)
{
if (ptr->next[i] != NULL) //将该结点的失配指针指向该 next[i] 结点
{
pre->next[i]->fail = ptr->next[i];
break;
}
ptr = ptr->fail; //回溯该结点的双亲的失配指针,直到该结点的 next[i] 与之相同
}
if (ptr == NULL) //若回溯到 root,则失配指针指向 root
pre->next[i]->fail = root;
}
que.push(pre->next[i]); //该结点的所有子结点入队列
}
}
}
}
其实我们会发现,AC 自动机算法只要你理解了失配指针的构建,接下的匹配过程就比较好理解了。对于文本的一个字符,匹配过程中只会有 2 种情况:

int matchMultiPattern(Trie root, string str)
{
int order;
int count = 0;
Trie pre = root;
Trie ptr;
for (int i = 0; i < str.size(); i++)
{
order = str[i] - ‘a‘;
while (pre->next[order] == NULL && pre != root)
{ //若根结点没有该字母的后继,通过失配指针挖掘,判断 str[i] 是否需要与模式串匹配
pre = pre->fail;
}
pre = pre->next[order]; //找到对应的模式串头,用 pre 指向
if (pre == NULL) //没有找到与之匹配的字符
{
pre = root; //pre 回到根结点
continue; //开启下一轮判断
}
ptr = pre; //匹配该结点后,沿其失败指针回溯,判断其它结点是否匹配
while (ptr != root) //ptr 回到根结点,则匹配结束
{
if (ptr->flag == true) //判断当前单词是否匹配过了
{
count++; //没匹配过,统计
ptr->flag = false; //修改 flag 为 false,表示该单词被匹配过了
}
else //结点已访问,退出循环
{
break;
}
ptr = ptr->fail; //回溯失配指针,挖掘下一个需要匹配的结点
}
}
return count;
}
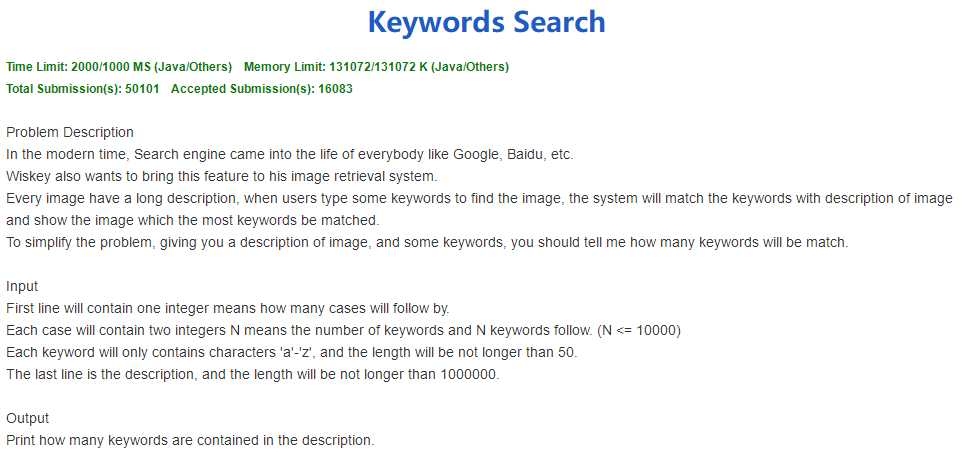
情景需要实现的是输入匹配的次数,然后输入被匹配的单词数 n,然后依次读入 n 个单词,接着输入文本,编程实现对文本中出现过的被匹配单词的数量统计。
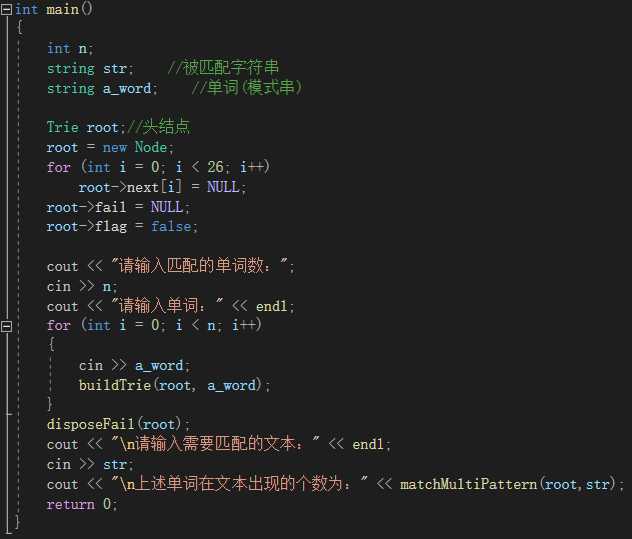
将上述的代码封装好,然后写一个主函数来组织 AC 自动机的运行即可,这里简化一下操作,只进行一次匹配。

BF算法
史上最简(详细)KMP算法讲解,看不懂算我输!
AC自动机
ac自动机最详细的讲解,让你一次学会ac自动机
AC自动机讲解超详细
AC自动机 算法详解(图解)及模板
AC自动机算法详解(转载)
AC自动机算法及模板
hdu 2222 AC自动机(可做模板)
AC自动机详解
标签:封装 info 次数 strlen beef alt blog tip tps
原文地址:https://www.cnblogs.com/linfangnan/p/12651873.html