标签:cut count span for documents 图片 ima get 技术
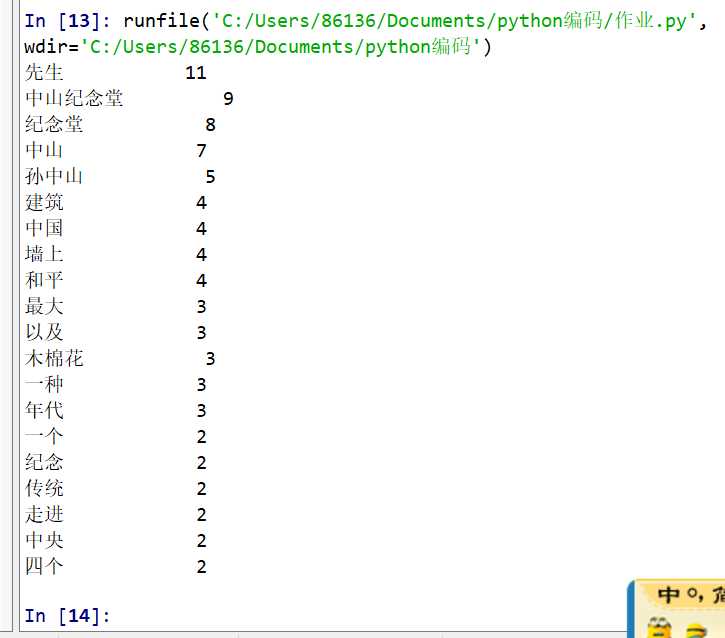
1 #jieba文本分析 2 import jieba 3 txt = open("C:/Users/86136/Documents/python文件测试/test.txt","rt",encoding="utf-8") 4 words=jieba.lcut(txt.read()) 5 counts={} 6 for word in words: 7 if len(word)==1: 8 continue 9 else: 10 counts[word]=counts.get(word,0)+1 11 items=list(counts.items()) 12 items.sort(key=lambda x:x[1],reverse=True) 13 for i in range(20): 14 word,count = items[i] 15 print("{0:<10}{1:>5}".format(word,count)) 16 txt.close()
标签:cut count span for documents 图片 ima get 技术
原文地址:https://www.cnblogs.com/1234f/p/12669214.html