标签:loss 应用 建模 解决 ace 来源 分类 残差网络 learning
身处大数据时代,对模型和风控工作者来说无异于福音。但与此同时,数据呈现长尾分布,不均衡分布导致训练困难,效果不佳。具体到风控场景中,负样本的占比要远远小于正样本的占比。考虑一个简单的例子,假设有10万个样本,其中逾期客户500个,坏样本占比0.5%。如果我们直接将数据输入模型进行训练,将导致即便全部判断为正,准确率也能达到99.5%,在梯度下降过程中,正样本压倒性的影响,模型难以收敛到最优点。??本文将对这一问题进行探讨,并试图跳出智能风控领域,从更宏观的角度,引入、借鉴和探讨非均衡样本的处理策略。
??常见的非均衡样本处理策略有:
??1.重新采样:
??(1)过采样:将样本较少的一类sample补齐
??(2)欠采样:将样本较多的一类sample压缩
??(3)组合采样:或者上下两个方向同时采样。
??使用重新采样的方法,也许会引入大量的重复样本,这将降低训练速度,并导致模型有过拟合的风险或者丢弃有价值的数据。
??2.使用代价敏感权重:
??我们对更小的样本分配更高的权重。在分类函数,比如逻辑回归中,我们可以通过class-weight来调整正负样本的权重。我们让小类的权重更大,以此来抵消不均衡的影响。考虑将样本分配不同的权重,这是符合直观感受的。一方面我们可以在做训练的时候,将小类型样本给与更高权重,强制干预梯度下降步长,另一方面工作中,不同的样本带来的代价也是不一样的,比如智能风控中,坏样本带来的损失是比好样本更高。
??以上两种方法是传统的机器学习中常用的办法,但是在实际工作不难中发现,重新采样和重新赋予权重这两种方法是启发式的,调参带来的结果影响较大,难以达到最佳。
??面对这样的困难,该将如何解决呢?
??为解决这样的问题,微众信科认为在工作中我们可以从两个方面进行有效的尝试:第一,扩展数据。第二,利用新的模型。
??第一,扩展数据:
??直观上,数据越多越好,但是我们不能简单的复制数据,而是生成一些新数据加入到模型中。具体方法如下:
??3.生成对抗网络(GAN):
??在机器学习的理论中,我们有生成模型和判别模型之分。生成模型是指我们对联合概率建模,除了分类之外我们还需要刻画数据是如何产生的。而判别模型是对条件概率进行建模,我们不关心如何刻画样本,我们只需要满足正确的分类比错误的分类概率大即可。生成对抗网络将两者联合了起来。模型分为生成部分和判别部分。
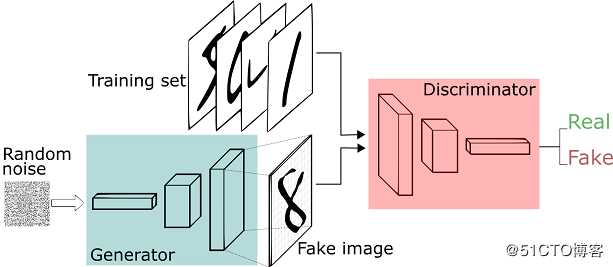
Image credit: Thalles Silva
??简单来说,我们准备好两部分数据:真实数据和随机噪音数据。随机噪音数据通过生成器,变成假数据。其后训练一个判别模型,它能很好的判断输入的数据是真实的还是假的(生成的)。生成器从随机噪音开始不停的生成数据,判别器告诉生成器不对,并告诉生成器哪里不对,生成器获得新的指导后再不停的生成数据,这样不断循环,导致生成的数据越来越靠近真实。
??4.SMOTE采样算法:
??该算法来源于论文《SMOTE: Synthetic Minority Over-sampling Technique》,该论文提出了一种过采样算法SMOTE。概括来说,本算法基于“插值”来为少数类合成新的样本。 并将新样本添加到数据集中进行训练。
??5.Label propagation标签传播算法:
??标签传播算法是一种基于图的半监督学习方式。LP的核心思想是:相似的样本具有相同的标签。因此LP算法首先构造相似矩阵,并利用新入样本和已经标签样本的相似度来给没有标签的样本打标签。
??第二:新的模型
??现在如果将视角放在更宏观的角度,我们会发现导致收敛困难的方法是我们用到(y_true-y_pred)相关的损失函数去做梯度下降。那么我们能不能改变这个损失函数,让收敛更容易?2018年Facebook Kaiming He在《Focal Loss for Dense Object Detection》中提出了focal_loss成为这一方面的代表性模型。
??FL(pt) = ?αt(1 ? pt)γ log(pt).
??Focal loss的核心思想是:比如正样本远比负样本多的话,模型肯定会倾向于数目多的正类(可以想象全部样本都判为正类),这时候,正类的 y,γ 或 σ(Kx) 都很小,而负类的 (1?y? )γ 或 σ(?Kx) 就很大,这时候模型就会开始集中精力关注负样本。
??从focal loss开始后继者们也开始了更多的改进,衍生除了各种进化的focal_loss,其中有代表性的是康纳尔大学和谷歌联合提出的CB Focal。 此外值得一提的是,在CVPR 2020上,旷视提出了BBN模型,比focal loss top1准确率提升了30%左右。并获得了长尾数据集 iNaturalist Challenge 赛道的世界冠军。
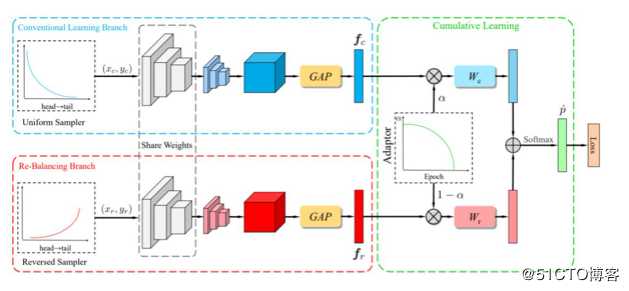
Image credit: 《BBN:Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition》
??BBN 模型包含 3 个主要组件:1)常规学习分支,2)再平衡分支,3)累积学习策略。常规学习分支和再平衡分支分别用于表征学习和分类器学习。这两个分支使用了同样的残差网络结构,除最后一个残差模块,两个分支的网络参数是共享的。
??无论是focal loss 或者后续的BBN,深度学习的优秀做法也同样可以应用到智能风控中。
??结语:可以看出无论是风控,抑或自然语言处理,计算机视觉等等各领域,数据的不均衡分布始终都是我们要面对的问题,智能风控也可以从其他领域借鉴好的做法来提升我们的模型。随着”新基建”的积极推进和5G的蓄势待发,数据将伴随着时代的浪潮不可避免地激增,如何科学地处理数据,快速地计算,精准地处理,稳健地部署将是值得从业者们一直关注的问题,我们也将作为先行者和践行者,去实践,去创造,去分享。
作者 | 何志坚(微众信科资深算法工程师)
标签:loss 应用 建模 解决 ace 来源 分类 残差网络 learning
原文地址:https://blog.51cto.com/14787744/2485983