标签:persist commons 设置 继承 编辑 一个 ted 消费 cts
maxwell通过实时收集mysql 的binlog变化,可以作为数据同步工具。但有时,应用部署在异地环境,mysql数据库的变化通过maxwell无法直接发送到数据中心进行解析和数据同步,本次使用ngix方式作为代理服务器,收集maxwell发送的json数据后,发送到后端的kafka集群。
架构如下: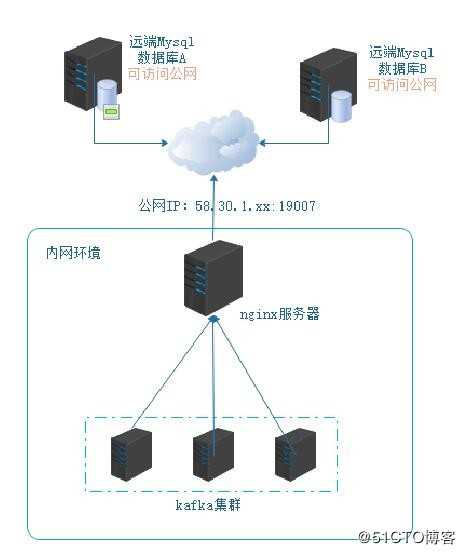
1,多个应用平台分布在不同地域内,远端mysql数据库,可以访问互联网。
2,在本地数据中心,使用nginx服务代理多台kafka集群。
3,把nginx服务器ip通过公网IP+端口映射,可以通过公网ip进行访问nginx。
在通过以上架构设计后,但是maxwell是不支持发送到http服务,只支持kafka、redis等。
在查阅maxwell官网后,发现有自定义producer方式,本次即使用自定义方式解决maxwell通过post发送json到nginx。
(文中代码中颜色是系统自带,不需要过度注意。)
1,使用idea,建立maven工程,添加pom依赖,主要设计http相关
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpasyncclient</artifactId>
<version>4.1.2</version>
</dependency>2,手动添加maxwell-1.22.3.jar文件到项目中。
3,创建HttpUtil类,用于调用发送post请求
package com.test.utils;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
public class HttpUtil {
public void doPost(String url, String json){
CloseableHttpClient httpclient = HttpClientBuilder.create().build();
HttpPost post = new HttpPost(url);
try {
StringEntity s = new StringEntity(json.toString());
s.setContentEncoding("UTF-8");
s.setContentType("application/json");//发送json数据需要设置contentType
post.setEntity(s);
HttpResponse res = httpclient.execute(post);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}4,创建CustomProducer自定义类,继承AbstractProducer
package com.test.producerfactory;
import com.test.utils.HttpUtil;
import com.zendesk.maxwell.MaxwellContext;
import com.zendesk.maxwell.producer.AbstractProducer;
import com.zendesk.maxwell.producer.EncryptionMode;
import com.zendesk.maxwell.producer.MaxwellOutputConfig;
import com.zendesk.maxwell.row.RowMap;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
public class CustomProducer extends AbstractProducer {
private final String headerFormat;
private final Collection<RowMap> txRows = new ArrayList<>();
private final HttpUtil httpUtil=new HttpUtil();
private static MaxwellOutputConfig config=new MaxwellOutputConfig();
private String url="";
private String server_id="0";
private String encrypt=null;
private String secretKey=null;
public CustomProducer(MaxwellContext context) {
super(context);
// this property would be ‘custom_producer.header_format‘ in config.properties
headerFormat = context.getConfig().customProducerProperties.getProperty("header_format", "Transaction: %xid% >>>\n");
//从maxwell的配置文件中获取配置信息
server_id=context.getConfig().customProducerProperties.getProperty("server_id");
url=context.getConfig().customProducerProperties.getProperty("url");
encrypt=context.getConfig().customProducerProperties.getProperty("encrypt");
secretKey=context.getConfig().customProducerProperties.getProperty("secretKey");
// 配置输出json字段包含serverID
config.includesServerId=true;
//配置是否加密数据
if (encrypt.equals("data")){
config.encryptionMode= EncryptionMode.ENCRYPT_DATA;
config.secretKey=secretKey;
}else if (encrypt.equals("all")){
config.encryptionMode= EncryptionMode.ENCRYPT_ALL;
config.secretKey=secretKey;
}
}
@Override
public void push(RowMap r) throws Exception
{
// filtering out DDL and heartbeat rows
if(!r.shouldOutput(outputConfig)) {
// though not strictly necessary (as skipping has no side effects), we store our position,
// so maxwell won‘t have to "re-skip" this position if crashing and restarting.
context.setPosition(r.getPosition());
return;
}
//设置serverID
r.setServerId(Long.parseLong(server_id));
// store uncommitted row in buffer
txRows.add(r);
if(r.isTXCommit()) {
// This row is the final and closing row of a transaction. Stream all rows of buffered
// transaction to stdout
// System.out.print(headerFormat.replace("%xid%", r.getXid().toString()));
txRows.stream().map(CustomProducer::toJSON).forEach(string -> httpUtil.doPost(url,string));
txRows.clear();
// rows ++;
// Only now, after finally having "persisted" all buffered rows to stdout is it safe to
// store the producers position.
context.setPosition(r.getPosition());
//
}
}
private static String toJSON(RowMap row) {
try {
return row.toJSON(config);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}5,创建CustomProducerFactory类
package com.test.producerfactory;
import com.zendesk.maxwell.MaxwellContext;
import com.zendesk.maxwell.producer.AbstractProducer;
import com.zendesk.maxwell.producer.ProducerFactory;
public class CustomProducerFactory implements ProducerFactory{
@Override
public AbstractProducer createProducer(MaxwellContext context) {
return new CustomProducer(context);
}
}6,使用idea工具打包data_sync.jar文件传到远端的maxwell的lib目录下。
配置工作主要分nginx和maxwell配置,下面分别介绍配置项。
1,nginx配置
Nginx在下载后,进行源码编译,需要添加kafka支持的插件
[root@host1 nginx]#
./configure --add-module=/usr/local/src/ngx_kafka_module --add-module=/usr/logcal/nginx_tcp_proxy_module
nginx的安装方式不做介绍,在安装完nginx后,在/usr/local/nginx/conf目录下,编辑nginx.conf文件
#user nobody;
worker_processes 1;
error_log logs/error.log;
error_log logs/error.log notice;
error_log logs/error.log info;
pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
kafka;
kafka_broker_list host2:9092 host3:9092 host4:9092;
server {
listen 19090;
server_name localhost;
location / {
root html;
kafka_topic test1;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}其中kafka_topic是接收数据后发送到指定的topic。
kafka_broker_list:即是kafka的broker节点和端口,此处因为配置了host解析,所以用了主机名。
在nginx配置完成后,reload配置,可以使用与kafka、nginx不同网段的服务器,使用以下命令测试nginx是否配通:
[root@master ~]# curl http://58.30.1.xxx:19007/ -d "aaaaaa"
在内网kafka集群中,使用以下命令查看kafka是否能接受到数据:
[root@host3 ~]#kafka-console-consumer --bootstrap-server kafkahost:9092 --topic test1
当kafka集群中接收到数据后,表示http发送的数据经过nginx 转发到kafka集群。
2,maxwell配置,可以通过官网下载maxwell软件,解压到/opt/maxwell下
(具体maxwell的安装和启动方式我在上一篇中已经有详细介绍)
使用自定义生产消费者,在解压后的maxwell上传依赖的data_sync.jar报到/opt/maxwell/lib目录下。
在/opt/maxwell目录下创建一个config.properties文件,写入指定配置:
vim config.properties
#[mysql]
user=maxwell
password=123456
host=hadoop1
port=3306
#[producer]
output_server_id=true
custom_producer.factory=com.test.producerfactory.CustomProducerFactory
custom_producer.server_id=23
custom_producer.url=http://58.30.1.XX:19007/
custom_producer.encrypt=data
custom_producer.secretKey=0f1b122303xx44123 output_server_id: #输出server_id,用于标识哪个区域平台的数据
custom_producer.factory: #自定义生产消费类
custom_producer.server_id: #定义的server_id,与my.cnf中的server_id一致
custom_producer.url: #数据中心对外开放的url
custom_producer.encrypt: #加密方式,data、all、none
custom_producer.secretKey: #秘钥值,通过数据中心点分配的秘钥值,与server_id一一对应
如果配置了数据加密,在接收到数据后,还需要进一步的解密后,才能获取binlog数据,解密的方式后续会写方法。
以上配置完成后,即可以启动maxwell,开启同步数据到本地数据中心,当数据同步到本地kafka集群后,可以使用flink、spark streaming接收做进一步处理。
maxwell收集binlog,不同网络环境通过nginx发送数据到kafka集群
标签:persist commons 设置 继承 编辑 一个 ted 消费 cts
原文地址:https://blog.51cto.com/jxplpp/2486116