标签:关闭 item 过程 决定 网址 img 引擎 ddl rap
它可以分为如下的几个部分。
两个桥梁
数据流
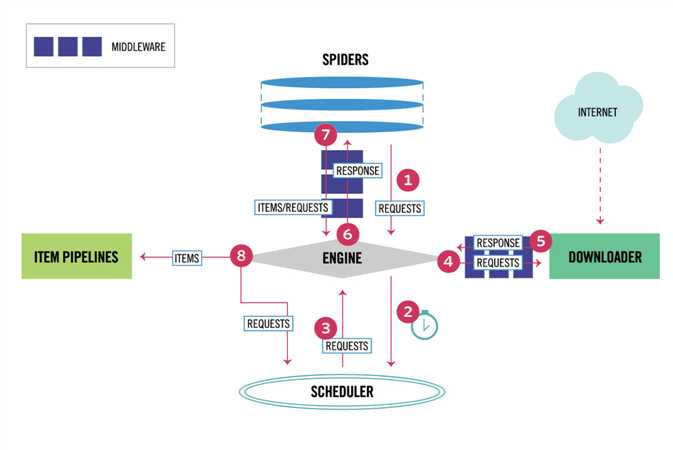
Scrapy 中的数据流由引擎控制,其过程如下:
通过多个组件的相互协作、不同组件完成工作的不同、组件对异步处理的支持,Scrapy 最大限度地利用了网络带宽,大大提高了数据爬取和处理的效率。
Scrapy 架构介绍
原文地址:https://www.cnblogs.com/baohanblog/p/12675490.html