标签:概念 create 并集 伪代码 常数时间 one 误差 数据收集 出现
在说明 HyperLogLog 之前,我们需要先了解一个概念:基数统计。维基百科中的解释是:
cardinality of a set is a measure of the “number of elements“ of the set
它的意思是:一个集合(注意:这里集合的含义是 Object 的聚合,可以包含重复元素)中不重复元素的个数。例如集合 {1,2,3,1,2},它有5个元素,但它的基数/Distinct 数为3。
下面通过一个实例说明基数在电商数据分析中的应用。
假设一个淘宝网店在其店铺首页放置了10个宝贝链接,分别从Item01到Item10为这十个链接编号。店主希望可以在一天中随时查看从今天零点开始到目前这十个宝贝链接分别被多少个独立访客点击过。所谓独立访客(Unique Visitor,简称UV)是指有多少个自然人,例如,即使我今天点了五次Item01,我对Item01的UV贡献也是1,而不是5。
用术语说这实际是一个实时数据流统计分析问题。
要实现这个统计需求。需要做到如下三点:
1、对独立访客做标识
2、在访客点击链接时记录下链接编号及访客标记
3、对每一个要统计的链接维护一个数据结构和一个当前UV值,当某个链接发生一次点击时,能迅速定位此用户在今天是否已经点过此链接,如果没有则此链接的UV增加1
下面分别介绍三个步骤的实现方案
客观来说,目前还没有能在互联网上准确对一个自然人进行标识的方法,通常采用的是近似方案。例如通过登录用户+cookie跟踪的方式:当某个用户已经登录,则采用会员ID标识;对于未登录用户,则采用跟踪cookie的方式进行标识。为了简单起见,我们假设完全采用跟踪cookie的方式对独立访客进行标识。
这一步可以通过JavaScript埋点及记录accesslog完成,具体原理和实现方案可以参考我之前的一篇文章:网站统计中的数据收集原理及实现。
可以看到,如果将每个链接被点击的日志中访客标识字段看成一个集合,那么此链接当前的UV也就是这个集合的基数,因此UV计算本质上就是一个基数计数问题。
在实时计算流中,我们可以认为任何一次链接点击均触发如下逻辑(伪代码描述):
cand_counting(item_no, user_id) { if (user_id is not in the item_no visitor set) { add user_id to item_no visitor set; cand[item_no]++; } }
逻辑非常简单,每当有一个点击事件发生,就去相应的链接被访集合中寻找此访客是否已经在里面,如果没有则将此用户标识加入集合,并将此链接的UV加1。
虽然逻辑非常简单,但是在实际实现中尤其面临大数据场景时还是会遇到诸多困难,下面一节我会介绍两种目前被业界普遍使用的精确算法实现方案,并通过分析说明当数据量增大时它们面临的问题。
接着上面的例子,我们看一下目前常用的基数计数的实现方法。
对上面的伪代码做一个简单分析,会发现关键操作有两个:查找-迅速定位当前访客是否已经在集合中,插入-将新的访客标识插入到访客集合中。因此,需要为每一个需要统计UV的点(此处就是十个宝贝链接)维护一个查找效率较高的数据结构,又因为实时数据流的关系,这个数据结构需要尽量在内存中维护,因此这个数据结构在空间复杂度上也要比较适中。综合考虑一种传统的做法是在实时计算引擎采用了B树来组织这个集合。下图是一个示意图:
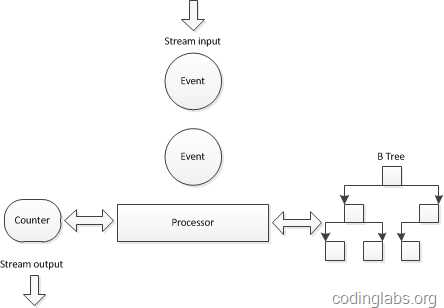
之所以选用B树是因为B树的查找和插入相关高效,同时空间复杂度也可以接受。
这种实现方案为一个基数计数器维护一棵B树,由于B树在查找效率、插入效率和内存使用之间非常平衡,所以算是一种可以接受的解决方案。但是当数据量特别巨大时,例如要同时统计几万个链接的UV,如果要将几万个链接一天的访问记录全部维护在内存中,这个内存使用量也是相当可观的(假设每个B树占用1M内存,10万个B树就是100G!)。一种方案是在某个时间点将内存数据结构写入磁盘(双十一和双十二大促时一淘数据部的效果平台是每分钟将数据写入HBase)然后将内存中的计数器和数据结构清零,但是B树并不能高效的进行合并,这就使得内存数据落地成了非常大的难题。
另一个需要数据结构合并的场景是查看并集的基数,例如在上面的例子中,如果我想查看Item1和Item2的总UV,是没有办法通过这种B树的结构快速得到的。当然可以为每一种可能的组合维护一棵B树。不过通过简单的分析就可以知道这个方案基本不可行。N个元素集合的非空幂集数量为2N−1,因此要为10个链接维护1023棵B树,而随着链接的增加这个数量会以幂指级别增长。
为了克服B树不能高效合并的问题,一种替代方案是使用bitmap表示集合。也就是使用一个很长的bit数组表示集合,将bit位顺序编号,bit为1表示此编号在集合中,为0表示不在集合中。例如“00100110”表示集合 {2,5,6}。bitmap中1的数量就是这个集合的基数。
显然,与B树不同bitmap可以高效的进行合并,只需进行按位或(or)运算就可以,而位运算在计算机中的运算效率是很高的。但是bitmap方式也有自己的问题,就是内存使用问题。
很容易发现,bitmap的长度与集合中元素个数无关,而是与基数的上限有关。例如在上面的例子中,假如要计算上限为1亿的基数,则需要12.5M字节的bitmap,十个链接就需要125M。关键在于,这个内存使用与集合元素数量无关,即使一个链接仅仅有一个1UV,也要为其分配12.5M字节。
由此可见,虽然bitmap方式易于合并,却由于内存使用问题而无法广泛用于大数据场景。
Redis 最常用的数据结构有字符串、列表、字典、集合和有序集合。后来,由于 Redis 的广泛应用,Redis 自身也做了很多补充,其中就有 HyperLogLog(2.8.9 版本添加)结构。HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常大时,计算基数所需的空间总是固定的、并且是很小的。
有关 HyperLogLog 算法的介绍可以参考这篇文章:神奇的HyperLogLog算法
在 Redis 中每个键占用的内容都是 12K,理论存储近似接近 2^64 个值,不管存储的内容是什么。这是一个基于基数估计的算法,只能比较准确的估算出基数,可以使用少量固定的内存去存储并识别集合中的唯一元素。但是这个估算的基数并不一定准确,是一个带有 0.81% 标准错误(standard error)的近似值。
但是,也正是因为只有 12K 的存储空间,所以,它并不实际存储数据的内容。
Redis 为 HyperLogLog提供了三个命令:PFADD、PFCOUNT、PFMERGE。我们依次来看看这三个命令的解释和作用。
命令行示例
# 命令格式:PFADD key element [element …] # 如果给定的键不存在,那么命令会创建一个空的 HyperLogLog,并向客户端返回 1 127.0.0.1:6379> PFADD ip_20190301 "192.168.0.1" "192.168.0.2" "192.168.0.3" (integer) 1 # 元素估计数量没有变化,返回 0(因为 192.168.0.1 已经存在) 127.0.0.1:6379> PFADD ip_20190301 "192.168.0.1" (integer) 0 # 添加一个不存在的元素,返回 1。注意,此时 HyperLogLog 内部存储会被更新,因为要记录新元素 127.0.0.1:6379> PFADD ip_20190301 "192.168.0.4" (integer) 1
命令行示例
# 返回 ip_20190301 包含的唯一元素的近似数量 127.0.0.1:6379> PFCOUNT ip_20190301 (integer) 4 127.0.0.1:6379> PFADD ip_20190301 "192.168.0.5" (integer) 1 127.0.0.1:6379> PFCOUNT ip_20190301 (integer) 5 127.0.0.1:6379> PFADD ip_20190302 "192.168.0.1" "192.168.0.6" "192.168.0.7" (integer) 1 # 返回 ip_20190301 和 ip_20190302 包含的唯一元素的近似数量 127.0.0.1:6379> PFCOUNT ip_20190301 ip_20190302 (integer) 7
命令行示例
# ip_2019030102 是 ip_20190301 与 ip_20190302 并集 127.0.0.1:6379> PFMERGE ip_2019030102 ip_20190301 ip_20190302 OK 127.0.0.1:6379> PFCOUNT ip_2019030102 (integer) 7
鉴于 HyperLogLog 不保存数据内容的特性,所以,它只适用于一些特定的场景。我这里给出一个最常遇到的场景需要:计算日活、7日活、月活数据。
分析:如果我们通过解析日志,把 ip 信息(或用户 id)放到集合中,例如:HashSet。如果数量不多则还好,但是假如每天访问的用户有几百万。无疑会占用大量的存储空间。且计算月活时,还需要将一个整月的数据放到一个 Set 中,这随时可能导致我们的程序 OOM。
有了 HyperLogLog,这件事就变得很简单了。因为存储日活数据所需要的内存只有 12K,例如:
ip_20190301
ip_20190302
ip_20190303
...
ip_20190331
那么,计算某一天的日活,只需要执行 PFCOUNT ip_201903XX 就可以了。每个月的第一天,执行 PFMERGE 将上一个月的所有数据合并成一个 HyperLogLog,例如:ip_201903。再去执行 PFCOUNT ip_201903,就得到了 3 月的月活。
由于 Redis HyperLogLog 只有三个命令,思想和操作也非常简单,这里直接给出代码示例。
import com.imooc.ad.Application; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.redis.core.HyperLogLogOperations; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.test.context.junit4.SpringRunner; /** * <h1>Redis HyperLogLog 测试用例</h1> * Created by Qinyi. */ @RunWith(SpringRunner.class) @SpringBootTest(classes = {Application.class}, webEnvironment = SpringBootTest.WebEnvironment.NONE) public class RedisHyperLogLogTest { /** 注入 StringRedisTemplate, 使用默认配置 */ @Autowired private StringRedisTemplate stringRedisTemplate; @Test @SuppressWarnings("all") public void testHyperLogLog() { HyperLogLogOperations operations = stringRedisTemplate.opsForHyperLogLog(); // add 方法对应 PFADD 命令 operations.add("ip_20190301", "192.168.0.1", "192.168.0.2", "192.168.0.3"); // size 方法对应 PFCOUNT 命令 System.out.println(operations.size("ip_20190301")); // 3 operations.add("ip_20190301", "192.168.0.1", "192.168.0.4"); System.out.println(operations.size("ip_20190301")); // 4 operations.add("ip_20190302", "192.168.0.1", "192.168.0.5"); System.out.println(operations.size("ip_20190302")); // 2 // union 方法对应 PFMERGE 命令 operations.union("ip_201903", "ip_20190301", "ip_20190302"); System.out.println(operations.size("ip_201903")); // 5 } }
网站经常有这样的需求:统计日活用户数,有哪些实现方式呢?
第一种做法:用redis的set集合。
用户登录以后,把用户id添加到redis的set中,set会自动进行去重,类似于这样:
127.0.0.1:6379> sadd users_2019_06_17 user1 (integer) 1 127.0.0.1:6379> sadd users_2019_06_17 user2 (integer) 1 127.0.0.1:6379> sadd users_2019_06_17 user3 (integer) 1
很显然,只需要一条scard命令:
127.0.0.1:6379> scard users_2019_06_17 (integer) 3
可以看出来,2019年6月17号的用户数是3个。
很简单,但是集合只适用于用户数比较少的场合,假如用户有100万,set存储100万个id号,如果一个id号占32个字节,总共就是差不多32M,一个月就是960M 差不多一个G了!
第二种做法:用Bitmap。
我们存放100万个id号需要100万个bit位,也就是100万/8 = 125K字节,直接用以id号和100万取余,余数作为bit的索引:
127.0.0.1:6379> setbit login_2019_06_17 10000 1 (integer) 0 127.0.0.1:6379> setbit login_2019_06_17 1024 1 (integer) 0 127.0.0.1:6379> setbit login_2019_06_17 238 1 (integer) 0 127.0.0.1:6379> setbit login_2019_06_17 3434 1 (integer) 0
这时候同样,只要一条bitcount就能查出来用户数:
127.0.0.1:6379> bitcount login_2019_06_17 (integer) 4
此时存储100万个用户,只需要125K个字节,一个月才4M。
还有没有占存储空间更少的办法?
第三种办法:用redis的HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
原理很复杂就不说了,只说下用法:
127.0.0.1:6379> pfadd login.2019_06_17 user1 (integer) 1 127.0.0.1:6379> pfadd login.2019_06_17 user2 (integer) 1 127.0.0.1:6379> pfadd login.2019_06_17 user3 (integer) 1 127.0.0.1:6379> pfadd login.2019_06_17 user4 (integer) 1 127.0.0.1:6379> pfcount login.2019_06_17 (integer) 4
此时存储100万个独立用户只需要15K左右,一个月才480K左右!
需要注意的是HyperLogLog的统计结果并不是一个精确的值,误差在0.81%左右,但是对于统计用户数这种场景来说足够了。
标签:概念 create 并集 伪代码 常数时间 one 误差 数据收集 出现
原文地址:https://www.cnblogs.com/myseries/p/12677050.html