标签:副本 技术 先进先出 更新 主服务器 不同的 数据丢失 拓扑 width
高并发;高性能;高可用
单机Redis的风险与问题
问题1.机器故障 现象:硬盘故障,系统崩溃 本质:数据丢失,很可能对业务造成灾难性打击
问题2.容量瓶颈 现象:内存不足
为了避免单点服务器故障,准备多台服务器,互相连通。将数据复制多个副本保存在不同的服务器上,连接在一起,并保证数据是同步的。即使有其中一台服务器宕机,其他服务器依然可以继续提供服务,实现Redis的高可用,即数据的冗余备份
主从复制:将master中的数据即时有效的复制到slave中 特征:一个master可以拥有多个slave,一个slave只对应一个master
(主从复制,主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主)
master:写数据; 执行写操作时,将出现变化的数据自动同步到slave; 读数据(可忽略) slave:读数据;写数据(禁止)
作用:读写分离,提高服务器的读写负载能力 负载均衡 故障恢复 数据冗余 高可用 容灾恢复
怎么用:配从不配主:
从库配置:命令-->slaveof 主库IP 主库端口 --> 每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件;Info replication
修改配置文件细节操作:拷贝多个redis.conf文件;开启daemonize yes;Pid文件名字;指定端口;Loq文件名字;Dump.rdb名字
常用3招:一主二仆 薪火相传 反客为主
一主二备:(三角形)
读写分离,只有主机可写,从机只能读
主机宕掉,从机不动,主机恢复后,再更新数据,从机可以继续备份
从机宕掉,需重连
薪火相传:(链式)
反客为主:slaveof no one 使当前数据库停止与其他数据库的同步,转成主数据库
复制原理:Slave启动成功连接到master后会发送一个sync命令
Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
主从复制三阶段:建立连接阶段-->数据同步阶段-->命令传播阶段
建立连接阶段:建立slave到master的连接,使master能够识别slave,并保存slave端口号
流程:
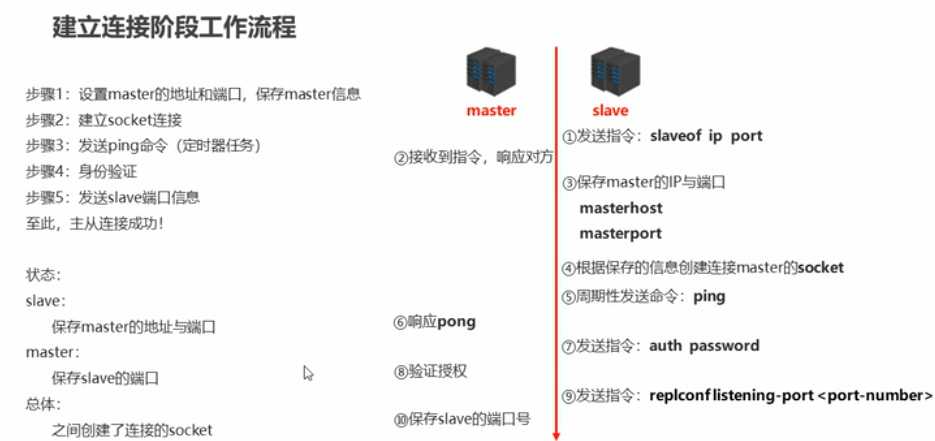
方式:
1.slaveof ip port
2.redis-server --slaveof masterip masterport
3.修改配置文件, slaveof masterip masterport
主从断开连接:slaveof no one
授权访问:
master配置文件设置密码:requirepass password
master客户端发送命令设置密码:config set requirepass password config get requirepass
slave客户端发送命令设置密码:auth password
slave配置文件设置密码:masterauth password
启动客户端设置密码:redis-cli -a password
数据同步阶段工作流程:在slave初次连接master后,复制master中的所有数据到slave
将slave的数据库状态更新成master当前的数据库状态
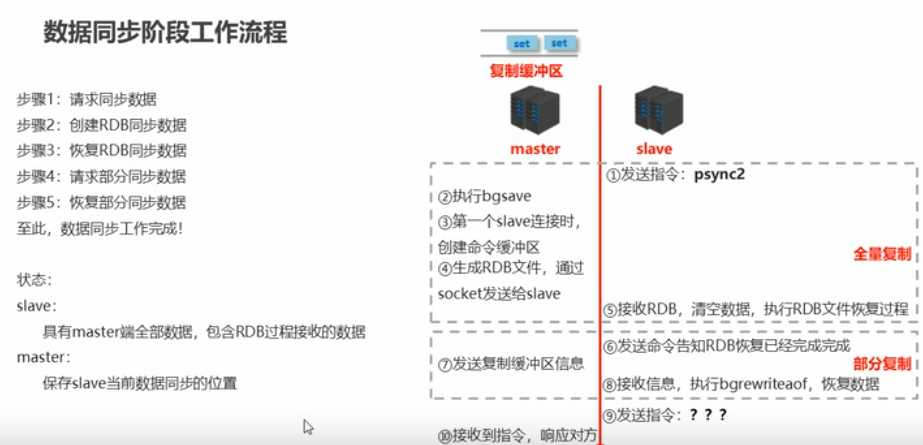
小结:
1.如果master数据量巨大,数据同步阶段应避开流量高峰期,避免造成master阻塞,影响业务正常执行
2.复制缓冲区大小设定不合理,会导致数据溢出。如果进行全量复制周期太长,进行部分复制时发现数据已经存在丢失的情况,必须进行第二次全量复制,导致slave陷入死循环状态 repl-backlog-size 1mb
3.master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,留下30%-50%的内存用于执行bgsave命令和创建复制缓冲区
slave
1.为避免slave进行全量复制、部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
slave-serve-stale-data yes|no
2.数据同步阶段,master发送给slave信息可以理解master是slave的一个客户端,主动向slave发送命令
3.多个slave同时对master请求数据同步,master发送的RDB文件增多,会对带宽造成巨大冲击,如果master带宽不足,因此数据同步需要根据业务需求,适量错峰
4.slave过多时,建议调整拓扑结构,由一主多从结构变为树状结构,中间的节点既是master,也是slave。注意使用树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟较大,数据一致性变差,应谨慎选择。
命令传播阶段
当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作称为命令传播
master将接收到的数据变更命令发送给slave,slave接受命令后执行命令
命令传播阶段的部分复制:
命令传播阶段出现了断网现象-->网络闪断闪连 忽略; 短时间网络中断 部分复制;长时间网络中断 全量复制
部分复制的三个核心要素:服务器的运行id(run id);主服务器的复制积压缓冲区;主从服务器的复制偏移量
服务器运行ID:

复制缓冲区:是一个先进先出的队列,用于存储服务器执行过的命令,每次传播命令,master都会将传播的命令记录下来,并存储在复制缓冲区
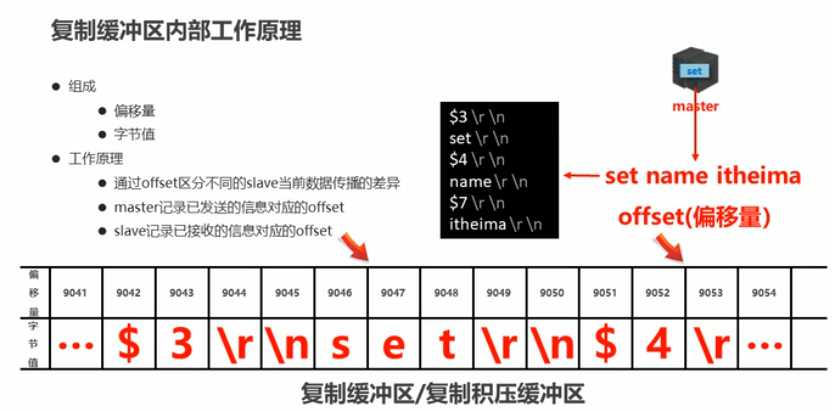

主从服务器复制偏移量offset
概念:一个数字,描述复制缓冲区中的指令字节位置
分类:master复制偏移量-->记录发送给所有slave的指令字节对应的位置(多个)
slave复制偏移量-->记录slave接收master发送过来的指令字节对应的位置(一个)
数据来源:master端-->发送一次记录一次
slave端-->接受一次记录一次
作用:同步信息,比对master与slave的差异,当slave断线后,恢复数据使用
数据同步+命令传播阶段工作流程

心跳机制
进入命令传播阶段后,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线
master心跳:指令-->Ping
周期-->由repl-ping-slave-period决定,默认10秒
作用-->判断slave是否在线
查询-->info replication 获取slave最后一次连接时间间隔,lag项维持在0或1视为正常
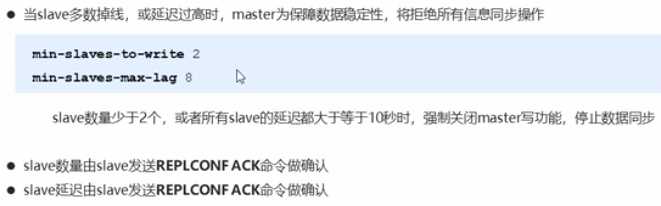
slave心跳任务:指令-->REPLCONF ACK{offset}
周期-->1秒
作用1:汇报slave自己的复制偏移量,获取最新的数据变更指令
作用2:判断master是否在线

主从复制常见问题:
频繁的全量复制:记录从机的id和offset;复制缓冲区过小
哨兵模式:sentinel.conf
是什么-->反客为主的自动版,能够从后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
怎么用-->自定义的/myredis目录下新建sentinel.conf文件
配置哨兵,填写内容:sentinel monitor被监控数据库名字(自己起名字)127.0.0.1 6379 1 最后一个数字1,表示主机挂掉后slave投票看让谁接替成为主机,得票数多少后成为主机
启动哨兵:Redis-sentinel /usr/common/sentinel.conf 上述目录按照各自的实际情况配置,可能目录不同
主机宕掉之后,会投票选一个从机当作主机,主机重启后会成为新主机的从机
正常主从演示
原有的master挂了
投票新选
重新主从继续开工,info replication查查看
问题:如果之前的master重启回来,会不会双master冲突?
一组sentinel能同时监控多个Master
复制的缺点:由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重
标签:副本 技术 先进先出 更新 主服务器 不同的 数据丢失 拓扑 width
原文地址:https://www.cnblogs.com/liushoudong/p/12677202.html