标签:出现 工具 启动 搭建 哪些 环境 python 结构 编辑

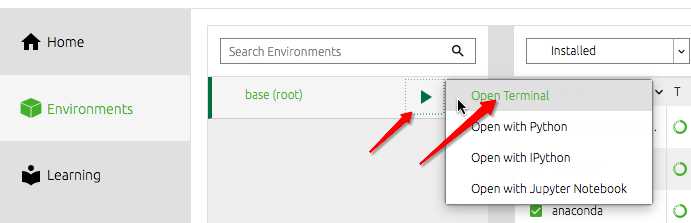
通过点击open terminal打开终端,cd到你想使用的文件夹内(盘符中的)。在该终端中录入jupyter notebook按下回车即可
new新建:
python3:新建一个jupyter的源文件(重点)
folder:新建一个文件夹
text file:新建一个任意后缀的文本文件
terminal:新建一个基于浏览器的终端 (下载包时使用,pip install xxxx)
插入cell:上边新建插入 a, 下边新建插入b
删除cell:x
执行cell:shift+enter
切换cell的模式:m,y
cell执行后,在cell的左侧双击就可以回到cell的可编辑模式
执行结果的收回:在执行结果左侧双击即可
打开帮助文档:shift+tab
tab:自动补全
撤销:z
jupyter的源文件写完后可以导出:
File-》Download as-》HTML
标签:出现 工具 启动 搭建 哪些 环境 python 结构 编辑
原文地址:https://www.cnblogs.com/zzsy/p/12687154.html