标签:两种 估算 生成 enc 时间 表示 http nbsp 假设
Word2Vec是词的一种表示,将词以固定的维数的向量表示出来。其优点:基于词袋模型的独热编码方式在判定同义词和相似句子的时候效果不是很好,而Word2Vec充分利用上下文信息,对上下文进行训练,每个向量不在是只有一个位置为1,其余位置为0 的稀疏向量。而是稠密的固定维度的向量。实现方式主要有一下两种:
1、利用上下文预测中心词continue bag of word (cbow)
2、利用中心词预测上下文skip-gram
Word2Vec是一种无监督学习,虽然从输入输出来看,有点像有监督学习,词向量的本质是单层神经网络,训练过程不是得到预测结果单词,或者对单词进行分类,而是得到hidden layer 的权重,借助了sequence2sequence训练过程得到了hidden layer 的权重。
语言模型的本质:



今天可以看做w1,天气看做w2,很好看做w3.这样计算就可以,但是还是有难度和缺陷的,一个参数空间过大, 可能性太多,无法估算,不可能有用。另一个就是数据稀疏严重,对于非常多词对的组合,在语料库中都没有出现,依据最大似然的估计得到的概率将会为0.因此,我们必须解决这个问题。
可能性太多,无法估算,不可能有用。另一个就是数据稀疏严重,对于非常多词对的组合,在语料库中都没有出现,依据最大似然的估计得到的概率将会为0.因此,我们必须解决这个问题。

如果样本量很大的时候,可以利用大数定理的原理,通过频率代替概率的方式。


一般来说,N元模型就是假设当前词的出现概率只与它前面的N-1个词有关,在时间中二元,三元用的比较多,其他的用的比较少,因为训练它需要庞大的语料库,数据严重稀疏,时间复杂度高,精度就一般般。
skip-gram:利用一个词预测上下文的词。

可以将中国作为中心词计算,在中国的条件下爱,我,这片,土地的概率之积,并且最大化。为了方便求解将乘积的形式变成log的加法形式求解。
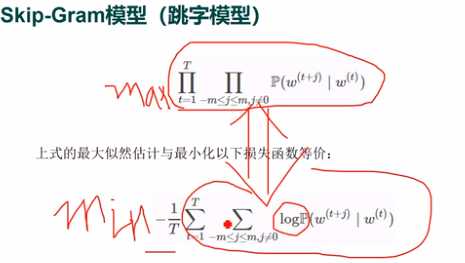
损失函数中给定中心词生成背景词的条件概率可以通过softmax函数。

cbow:利用上下文预测某一个特定的词。和skip-gram的方式相反。
标签:两种 估算 生成 enc 时间 表示 http nbsp 假设
原文地址:https://www.cnblogs.com/limingqi/p/12700304.html