标签:快速 之间 手动 工作 社会 公司 defining 收集 遇到
正如大家所知,大数据建设的目标是为了融合组织数据,增加组织的洞察力和竞争力,实现业务创新和产业升级。而提高数据质量是为了巩固大数据建设成果,解决大数据建设成果不能满足业务要求的问题。并且,数据质量问题不仅仅是一个技术问题,它也可能出现在业务和管理的过程中。所以,要想提高数据质量,就必须懂行业、懂组织、懂业务。当然,正如“数据博士”Jim barker 所说,我们可以简单地通过引入一些工具和规则就可以解决 80% 的问题,也可以引入一个复杂的系统工程来解决 100% 的质量问题,取决于我们希望达到什么样的质量标准。
借此机会,我也很期待各位朋友能够与我们分享你遇到的数据质量问题、故事和解决方法,这将对我们的研究和研发工作带来莫大的帮助。
为了尽量说清楚数据质量问题的来龙去脉和解决方法,篇幅较长,我将它分为以下几个部分:
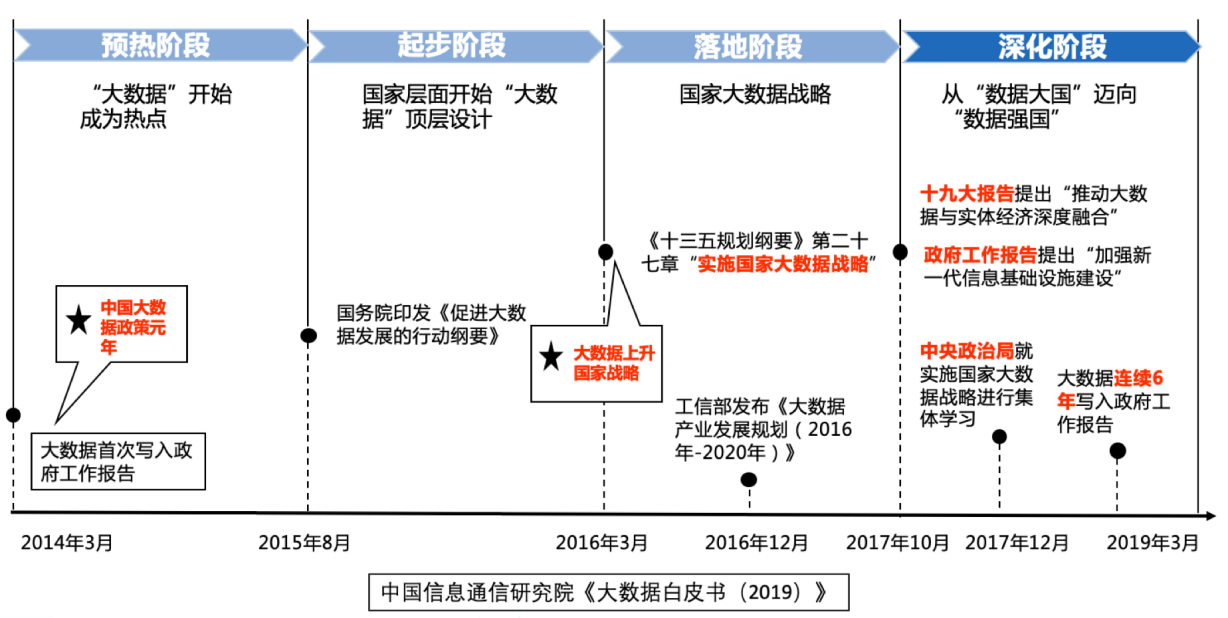
2014 年大数据被写入政府工作报告,成为大数据政策元年,大数据开始成为热点;2015 年国务院印发《促进大数据发展的行动纲要》,国家层面开始“大数据”顶层设计;2016 年工信部发布《大数据产业发展规划(2016 年 -2020 年)》,大数据上升为国家战略;2019 年政府工作报告提出加强新一代信息基础设施建设(新基建),我们也逐步从“数据大国”迈向“数据强国”。
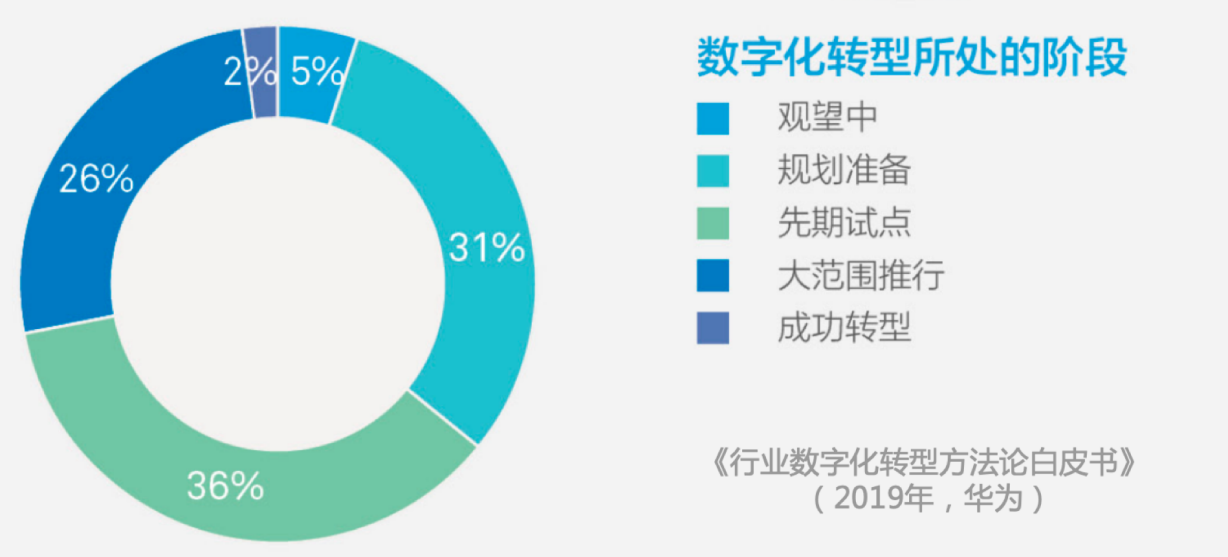
根据华为公司在 2019 年对其自身客户关于数字化转型的一项调查,只有 5% 的企业处于观望,31% 的企业在规划准备,36% 的企业已经开始先期试点,26% 的企业已经大规模推行,数据字化转型已经进入深水期。这意味着 95% 的企业已经开始数字化转弄的工作。
大数据经过 6 年的快速发展期,已经比较明显地分为两个阶段,第一阶段是大数据归集、治理和价值探索,第二阶段是大数据价值体现。当下,部分政府和企业已经在第一阶段中完成了数据的归集和治理,大步迈入数据价值体现的第二阶段,努力实现组织的业务创新和产业升级。
然而,大数据发展过程中仍然存在不少困难和问题,缺少整体规划和实施路径,缺少高层支持,部门壁垒难以打破,业务价值体现不足,技术能力不足,等等。就我个人来看,这里最核心的一个问题就是业务价值体现不足,没有业务价值的支撑,就不会有各部门领导的支持,更不会有高层的支持和资金的支持。所以,数字化转型一定要以价值为导向,在一个“点”上做出实际效果以后再进行“面”上的拓展。
要体现数据价值,前提就是数据质量的保障,质量没有得到 100% 保证的数据是很难体现出业务价值的,如果基于这些有问题的数据做决策支持,或做业务办理,将会得到灾难性的结果,让领导层和数据使用方对大数据失去信心。
根据哈工大王志宏先生在科技导报发表的研究表明,如果没有良好的数据质量,大数据将会对决策产生误导,甚至产生有害的结果。
被誉为“数据博士”的 Jim barker,用一个简单的医学概念来定义两种类型的数据质量问题。
它们之间的区别简而言之可归纳为如下几点:
第一类数据质量问题首先需要“know what”才能来检测数据的完整性、一致性、唯一性和有效性。这些属性靠数据质量软件甚至手动很好地找到。你不需要有很多的背景知识,或者数据分析经验。只要按照 4 个属性验证它的存在,就可以判定它错误的。例如,如果我们在性别领域插入一个 3,我们就可以判定它到底是不是一个有效值。
第二类数据质量问题需要“know why”来检测时效性、一致性和准确性属性。需要研究能力、洞察力和经验,而不是简简单单就可以找得出来的。这些数据集经常从表面上看起来没有问题。但是问题往往存在于细节中,需要时间去发现。Jim 举的例子就是一份退休人员的雇佣记录,如果我们不知道他们早已退休的话,是看不出来这个数据是错的。
所以,解决这些数据质量问题的关键就是需要一个复杂的、策略化的方法,而非孤立的、片面的来看问题。一旦数据质量不好,我们就需要寻求自动化与人工的双重方式才能解决这个问题了。
根据 Jim barker 的经验:
第一类基本涵盖了 80% 的数据质量问题,但只消耗了我们 20% 的经费成本。
第二类数据问题往往需要多方的输入,以便发现、标记和根除。虽然我们客户关系管理系统中的每个人都有购买日期,但购买日期可能不正确,或者与发票或发货清单不符。只有专家才能通过仔细核查其内容来解决问题并手动改进客户关系管理系统。
第一类数据质量的挑战可以快速解决,但第二类问题提出了一个挑战,必须依靠人类的专业知识才可以解决。后面会介绍龙石数据的做法,我们可以简单地通过引入一些工具和规则就可以解决 80% 的问题,也可以引入一个复杂的系统工程来解决 100% 的质量问题,取决于我们希望达到什么样的质量标准。
目前为止,最权威的标准是由全国信息技术标准化技术委员会提出的数据质量评价指标(GB/T36344-2018 ICS 35.24.01),它包含以下几个方面:
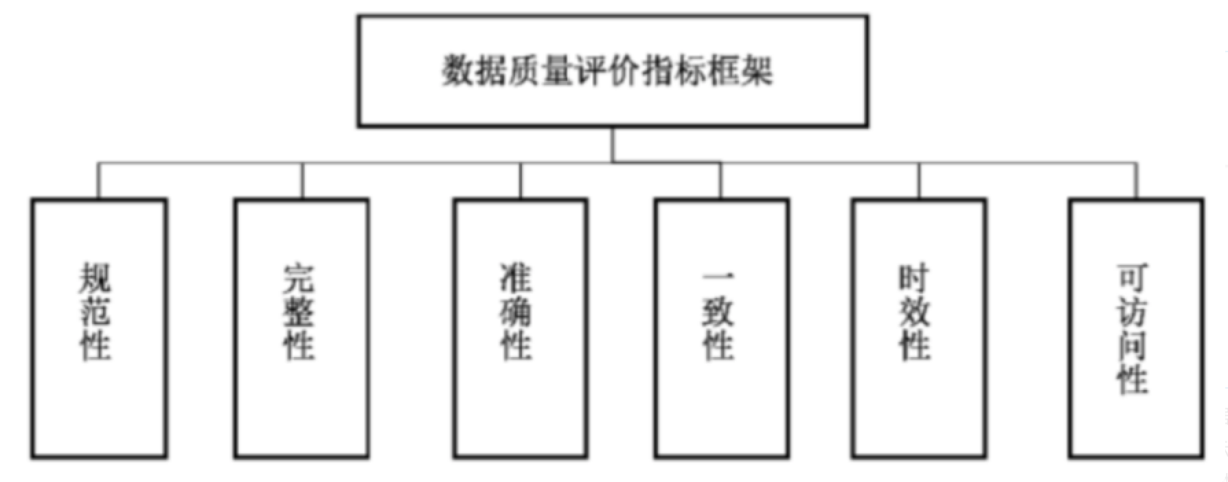
规范性:指的是数据符合数据标准、数据模型、业务规则、元数据或权威参考数据的程度。例如 GB/T 2261.1-2003 中定义的性别代码标准是 0 表示未知性别,1 表示男,2 表示女,9 表示未说明。GB 11643-1999 中定义的居民身份证编码规则是 6 位数字地址码,8 位数字出生日期码,三位数字顺序码,一位数字校验码。
完整性:指的是按照数据规则要求,数据元素被赋予数值的程度。例如互联网 + 监管主题库中,监管对象为特种设备时,监管对象标识必须包含企业统一社会信用代码 + 产品品牌 + 设备编码,监管对象为药品时,监管对象标识必须包含药品名称 + 批准文号 + 生产批号。
准确性:指的是数据准确表示其所描述的真实实体(实际对象)真实值的程度。例如互联网 + 监管行政检查行为中的行政相对人为公民时,证件类型和证件号码只能是身份证号码。
一致性:指的是数据与其它特定上下文中使用的数据无矛盾的程度。例如许可证信息与法人基础信息是否一致,检查计划与检查记录是否匹配。
时效性:指的是数据在时间变化中的正确程度。例如企业住址搬迁后,企业法人库中的住址是否及时更新了。营业执照已经办理,许可照办理时是否可以及时获取到营业执照信息。
可访问性:指的是数据能被访问的程度。
除此之外,还有一些业内认可的补充指标,并且在质量工作的实际开展中,可以根据数据的实际情况和业务要求进行扩展,例如:
唯一性:描述数据是否存在重复记录(国标归在准确性中)。
稳定性:描述数据的波动是否是稳定的,是否在其有效范围内。
可信性:描述数据来源的权威性、数据的真实性、数据产生的时间近、鲜活度高。
大数据的建设和管理是一个专业且复杂的工程,涵盖了业务梳理、标准制定、元数据管理、数据模型管理、数据汇聚、清洗加工、中心存储、资源目录编制、共享交换、数据维护、数据失效等等过程。在任何一个环节中出错,都将导致数据的错误。甚至,源头数据本身就是错误的。所以,数据质量问题不仅仅是一个技术问题,它也可能出现在业务和管理的过程中。

数据质量的技术因素:
数据质量的业务因素:
数据质量的管理因素:
如前所述,大数据的建设和管理是一个专业且复杂的工程,涵盖了业务梳理、标准制定、元数据管理、数据模型管理、数据汇聚、清洗加工、中心存储、资源目录编制、共享交换、数据维护、数据失效等等过程。中间任何一个环节出问题,都将导致数据质量问题。
大部分大型组织经过大数据建设,已经获得比较好的数据建设成果,也有了比较可观的数据量的积累,但将这些数据直接拿来支撑业务的办理却是一个很大的风险,原因就是只要一笔数据不正确,都可能带来很大的业务风险,导致客户的报怨,这也正是业务部门对大数据建设成果报有怀疑态度的重要原因。龙石数据根据多年数据治理和数据质量实践经验,根据大数据建设项目的执行过程,将它分为事前预防、事中监控、事后改善三个阶段。
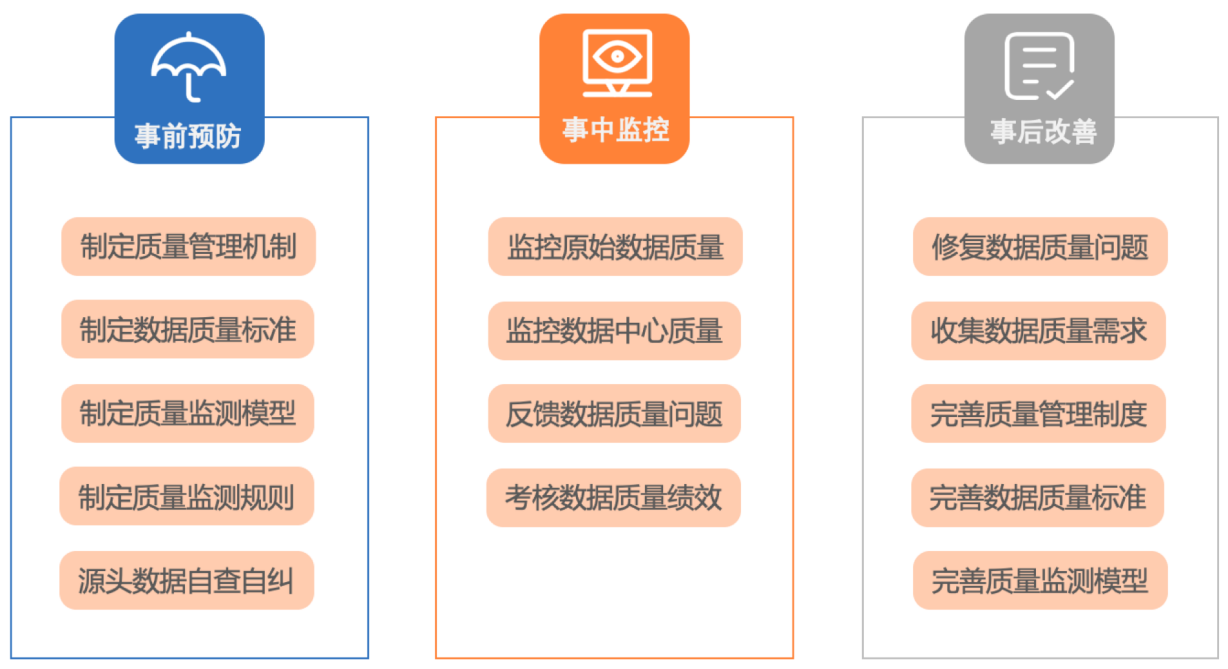
事前预防
事中监控
事后改善
最后,我们要想把大数据建设做好,就要把数据质量做好。要把数据质量做好,就要充分理解业务,要了解大数据建设的全部过程,要从更高的视角来发现和解决大数据建设过程当中的各种问题。
苏槐,微信号 Sulaohuai,现服务于龙石数据,曾就职于神州数码、Oracle、新加坡电信等企业。擅长数据治理、容器技术、微服务架构及技术管理。
标签:快速 之间 手动 工作 社会 公司 defining 收集 遇到
原文地址:https://www.cnblogs.com/zourui4271/p/12700366.html