标签:package 删除 存在 下载速度 mamicode ges etc loading minutes
用朴素贝叶斯做一个分类问题,数据就用sklearn新闻数据集。
但是下载巨慢,没耐心等。接下去就是一波操作,上篮成功。
因为版本之间可能存在差异,所以就不发数据集的安装包了。
Downloading 20news dataset. This may take a few minutes.
Downloading dataset from https://ndownloader.figshare.com/files/5975967 (14 MB)cd C:\Users\73107\scikit_learn_data
可以看到20news_home这个文件,里面是20news-bydate.tar.gz这么一个安装包。
请记住它的名字20news-bydate.tar.gz。
可以把这个安装包删除,程序也可以停止了。https://ndownloader.figshare.com/files/5975967
下载安装包,下载完毕之后。
该安装包的名字改成上面说的那个名字(20news-bydate.tar.gz)。
并且把这个安装包放到 C:\Users\73107\scikit_learn_data\20news_home里面。Python环境别搞错了,特别是用虚拟环境的。别乱搞。
cd \site-packages\sklearn\datasets
打开twenty_newsgroups.py文件
把第一个红框注释(其实就是原本用来下载的代码)。
写上第二个红框,也就是下载安装包的路径。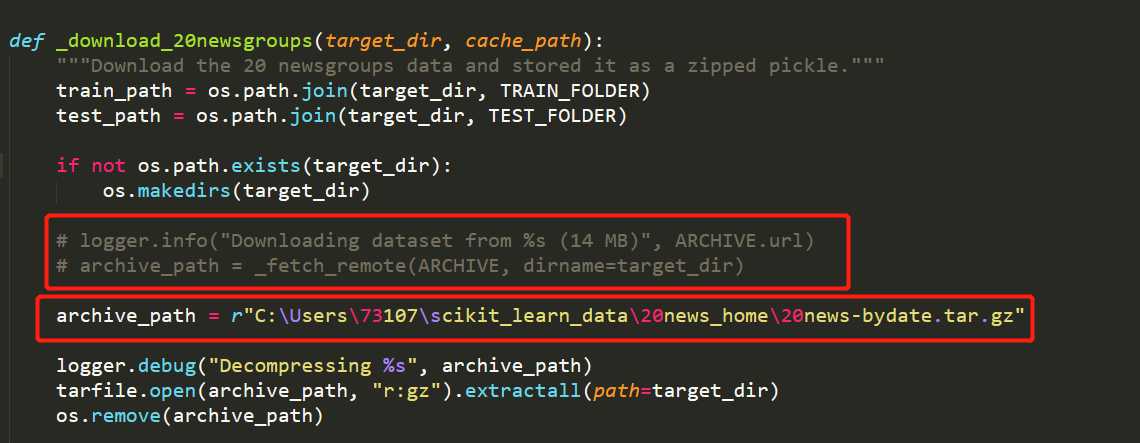
程序会自动解压20news-bydate.tar.gz。
然后删除,最后生成一个缓存文件20news-bydate.pkz。机器学习:如何解决fetch_20newsgroups下载速度巨慢的问题?
标签:package 删除 存在 下载速度 mamicode ges etc loading minutes
原文地址:https://www.cnblogs.com/peijz/p/12711917.html