标签:tsp and master 注意 link lua 虚拟 安装包 hadoop安装
一、前提条件
1.1创建3台虚拟机,且配置好网络,建立好互信。
1.2 Java1.8环境已经配置好
1.3 Hadoop2.7.7集群已经完成搭建,具体参见我的博客https://www.cnblogs.com/theyang/p/12363276.html
1.4 Scala软件包和Spark软件包的下载:
https://www.scala-lang.org/download/
http://spark.apache.org/downloads.html
二、安装Scala
2.3配置环境变量
vi /etc/profile
SCALA_HOME=/opt/soft/scala-2.13.0
PATH=$PATH:$SCALA_HOME/bin
[root@master data]# scala
Welcome to Scala 2.13.1 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161).
Type in expressions for evaluation. Or try :help.
scala>
4.3配置环境变量
vi /etc/profile SPARK_HOME=/opt/soft/spark-2.4.4-bin-hadoop2.7
PATH=$PATH:$SPARK_HOME/bin

source /etc/profile
4.5在spark-env.sh文件加入以下内容(没有这个文件的话复制一个spark-env.sh.template修改成spark-env.sh)
export JAVA_HOME=/opt/soft/jdk1.8 #jdk的安装目录
export SCALA_HOME=/opt/soft/scala-2.13.1 #scala的安装目录
export HADOOP_HOME=/opt/soft/hadoop2.7 #hadoop安装目录
export HADOOP_CONF_DIR=/opt/soft/hadoop2.7/etc/hadoop #hadoop安装目录下对应的文件
export SPARK_MASTER_HOST=hadop51 #本机的名字 可在/etc/hostname里修改 注意:集群的各个机器对应各自的主机名
export SPARK_WORKER_MEMORY=1g #Spark应用程序Application所占的内存大小
export SPARK_WORKER_CORES=2 #每个Worker所占用的CPU核的数目
export SPARK_HOME=/opt/soft/spark-2.4.4-bin-hadoop2.7 #spark安装目录
export SPARK_DIST_CLASSPATH=$(/opt/soft/hadoop2.7/bin/hadoop classpath) #hadoop安装目录对应的文件
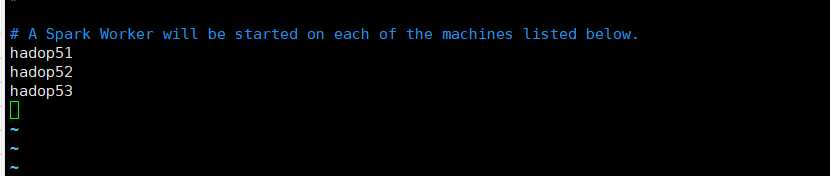
4.6slaves配置(没有这个文件的话复制一个slaves.template修改成slaves)
加入以下配置(三台主机名)
五、复制到其他节点
5.1在第一台机器节点上安装配置完成Spark后,将整个spark目录拷贝到其他节点,并在各个节点上更新/etc/profile文件中的环境变量
scp -r /opt/soft/spark-2.4.4-bin-hadoop2.7/ root@hadop52:/opt/soft/
scp -r /opt/soft/spark-2.4.4-bin-hadoop2.7/ root@hadop53:/opt/soft/
把profile文件也复制过去,省得再去配置环境变量:
scp /etc/profile root@hadop52:/etc/
scp /etc/profile root@hadop53:/etc/
5.2复制完后记得在其它节点
source /etc/profile
六、测试Spark
6.1在主节点启动Hadoop集群
start-all.sh
6.2在主节点启动spark集群
cd /opt/soft/spark-2.4.4-bin-hadoop2.7/sbin/
./start-all.sh
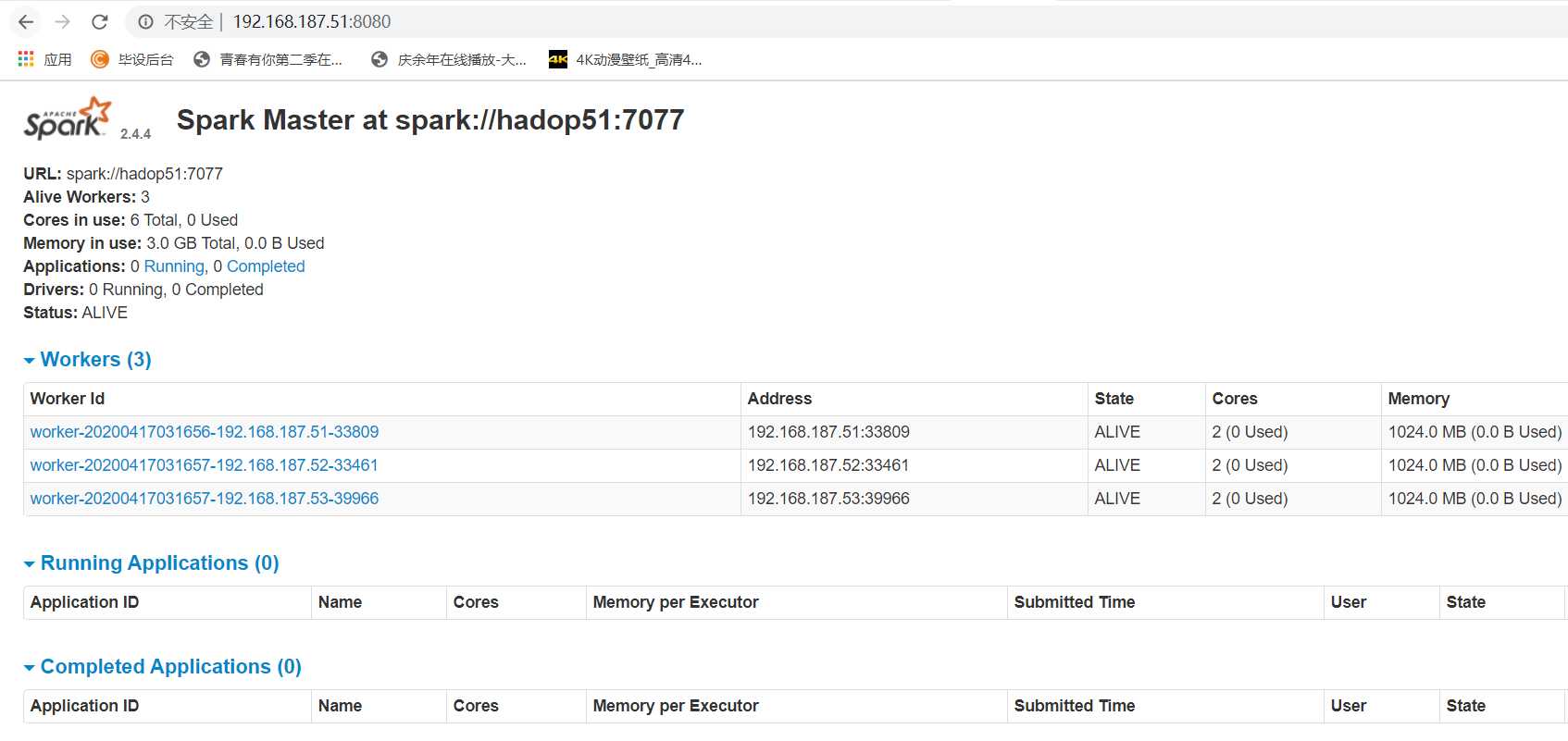
6.3打开浏览器输入http://ip:8080,看到如下活动的Workers,证明安装配置并启动成功
标签:tsp and master 注意 link lua 虚拟 安装包 hadoop安装
原文地址:https://www.cnblogs.com/theyang/p/12716688.html