标签:cal code img 虚拟 输入 java_home 下载 mamicode lang
一、前提条件
1、3台虚拟机,java1.8环境配置,hadoop-2.7.7集群搭建(参见https://www.cnblogs.com/yangy1/p/12362565.html,以及https://www.cnblogs.com/yangy1/p/12367462.html中的横向扩容)
2、
https://www.scala-lang.org/download/
3、Spark软件包的下载
http://spark.apache.org/downloads.html
二、安装Scala以及Spark
上传scala-2.13.1.tgz和spark-2.4.4-bin-hadoop2.7.tgz到/opt/install目录
cd /opt/install
rz

在/opt新建两个目录Scala和Spark
cd/opt
mkdir Scala Spark
1、安装Scala
解压安装包到scala目录
cd /opt/install
tar -zxvf scala-2.13.1.tgz -C /opt/Scala
配置环境变量
vim /etc/profile export SCALA_HOME=/opt/scala/scala-2.13.1 export PATH=$PATH:$SCALA_HOME/bin
保存配置
source /etc/profile
验证安装成功

2、安装Spark(master节点为hdp03)
解压安装包到spark目录
cd /opt/install
tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz -C /opt/spark
配置环境变量
vim /etc/profile export SPARK_HOME=/opt/spark/spark-2.4.4-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin
保存配置
source /etc/profile
配置文件
cd /opt/spark/spark-2.4.4-bin-hadoop2.7/conf/
1)spark-env.sh
scp spark-env.sh.template spark-env.sh vim spark-env.sh #添加如下内容(各个软件的路径,hdp03为master的主机名) export JAVA_HOME=/opt/software/jdk1.8 export SCALA_HOME=/opt/scala/scala-2.13.1 export HADOOP_HOME=/opt/software/hadoop-2.7.7 export HADOOP_CONF_DIR=/opt/software/hadoop-2.7.7/etc/hadoop export SPARK_MASTER_HOST=hdp03 export SPARK_WORKER_MEMORY=1g export SPARK_WORKER_CORES=2 export SPARK_HOME=/opt/spark/spark-2.4.4-bin-hadoop2.7 export SPARK_DIST_CLASSPATH=$(/opt/software/hadoop-2.7.7/bin/hadoop classpath)
slaves
scp slaves.template slaves
vim slaves
hdp01
hdp02
hdp03
在master节点上安装配置完成Spark后,将整个spark目录拷贝到其他节点,并在各个节点上更新/etc/profile文件中的环境变量
三、测试Spark集群
在master节点启动spark
cd /opt/spark/spark-2.4.4-bin-hadoop2.7/ sbin/start-all.sh
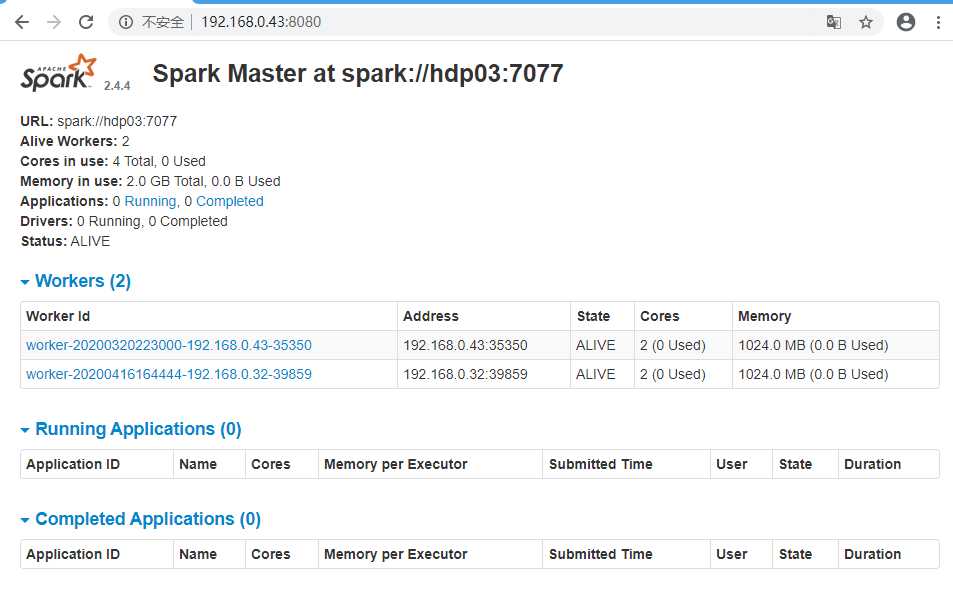
打开浏览器输入192.168.0.43:8080(master主机的ip:8080)看到如下活动的Workers,证明成功
标签:cal code img 虚拟 输入 java_home 下载 mamicode lang
原文地址:https://www.cnblogs.com/yangy1/p/12716854.html