标签:xcache dia 公众号 down 使用方法 申请 value cep lse
情景项目上线了一个接口,先灰度一台机器观察调用情况;
接口不断的调用,过了一段时间,发现机器上的接口调用开始报OOM异常 !
当天就是上线deadline了,刺激。。
jps命令获取出问题jvm进程的进程ID使用jps -l -m获取到当前jvm进程的pid,通过上述命令获取到了服务的进程号:427726 (此处假设为这个)
jps命令
jps(JVM Process Status Tool):显示指定系统内所有的HotSpot虚拟机进程jps -l -m: 参数-l列出机器上所有jvm进程,-m显示出JVM启动时传递给main()的参数
jstat观察jvm状态,发现问题因为是OOM异常,所以我们首先重启机器观察了JVM的运行情况;
我们使用jstat -gc pid time命令观察GC,发现GC在YGC后,GC掉的内存并不多,每次YGC后都有一部分内存未回收,导致在多次YGC后回收不掉的内存被挪到堆的old区,old满了之后FGC发现也是回收不掉;
这里基本可以确定是内存泄漏的问题了,下面我们有简单看了下机器的cpu、内存、磁盘状态
jstat命令:
jstat(JVM statistics Monitoring)是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。jstat -gc pid time: -gc 监控jvm的gc信息,pid 监控的jvm进程id,time每个多少毫秒刷新一次jstat -gccause pid time: -gccause 监控gc信息并显示上次gc原因,pid 监控的jvm进程id,time每个多少毫秒刷新一次jstat -class pid time: -class 监控jvm的类加载信息,pid 监控的jvm进程id,time每个多少毫秒刷新一次
在这里先简单说一下,堆的GC:
在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。
年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。不管怎样,都会保证名为To的Survivor区域是空的,minor GC会一直重复这样的过程。
使用top -p pid获取进程的cpu和内存使用率;查看RES 和 %CPU %MEM三个指标: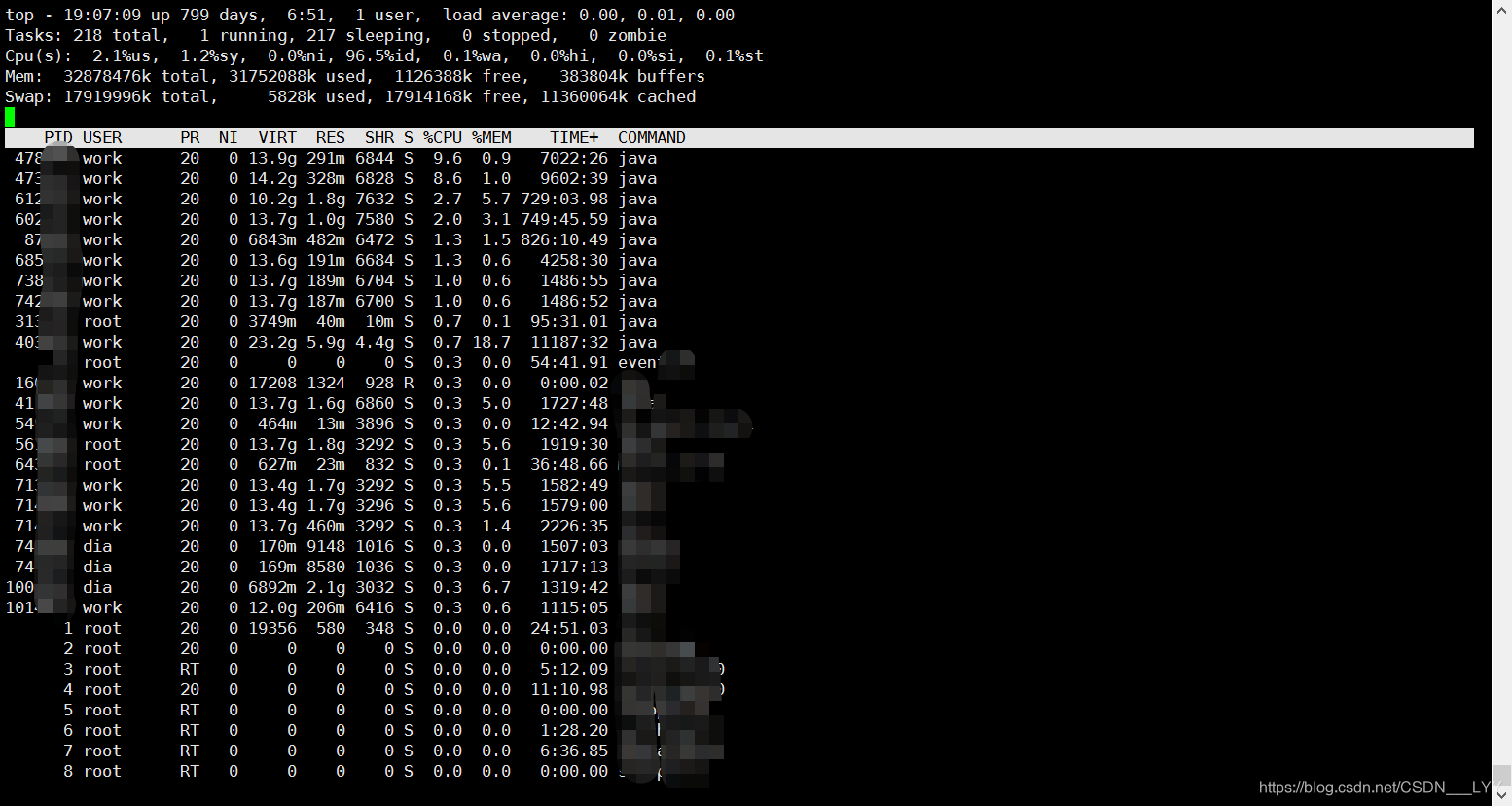
在这里先简单说一下,top命令展示的内容:
VIRT:virtual memory usage 虚拟内存
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量RES:resident memory usage 常驻内存
1、进程当前使用的内存大小,但不包括swap out
2、包含其他进程的共享
3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4、关于库占用内存的情况,它只统计加载的库文件所占内存大小SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
4、swap out后,它将会降下来DATA
1、数据占用的内存。如果top没有显示,按f键可以显示出来。
2、真正的该程序要求的数据空间,是真正在运行中要使用的。ps : 如果程序占用实存比较多,说明程序申请内存多,实际使用的空间也多。
如果程序占用虚存比较多,说明程序申请来很多空间,但是没有使用。
发现机器的自身状态不存在问题, so毋庸置疑,发现问题了,典型的内存泄漏。。
我们使用jmap -dump:format=b,file=dump_file_name pid 命令,将当前机器的jvm的状态dump下来或缺的一份dump文件,用做下面的分析
jmap命令:
jmap(JVM Memory Map)命令用于生成heap dump文件,还可以查询finalize执行队列、Java堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。jmap -dump:format=b,file=dump_file_name pid: file=指定输出数据文件名, pid jvm进程号
接下来,回滚灰度的机器,开始解决问题=.=
在这里,我们分析dump文件,使用的Jprofiler软件,就是下面这个东东:
具体的使用方法,在这就不再赘述了,下面将dump文件导入到Jprofiler中:
选择Heap Walker 中的Current Object Set,这里面显示的是当前的类的占用资源,从占用空间从大到小排序;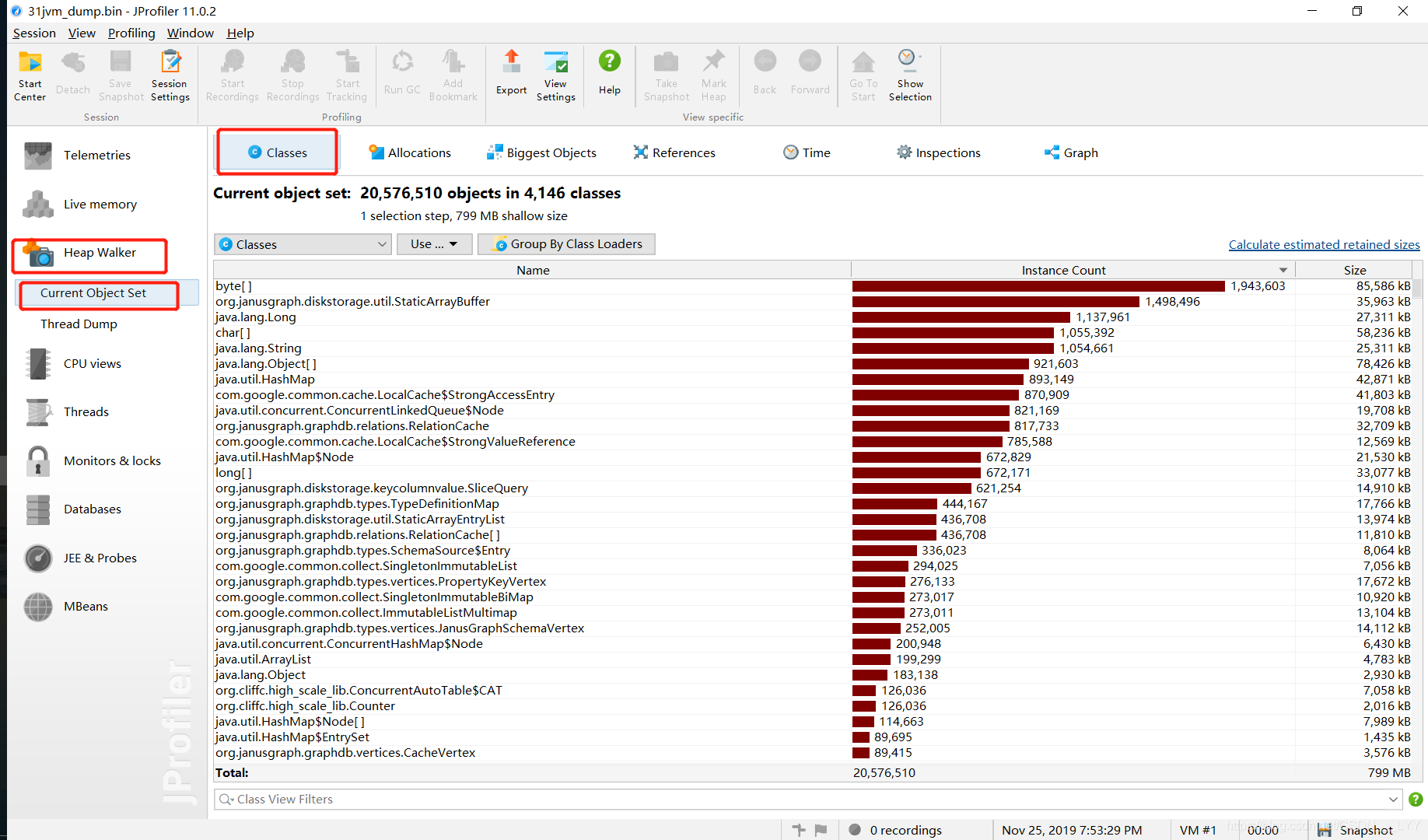
从上图中,没有观察出什么问题,我们点击Biggest Objects,查看哪个对象的占用的内存高: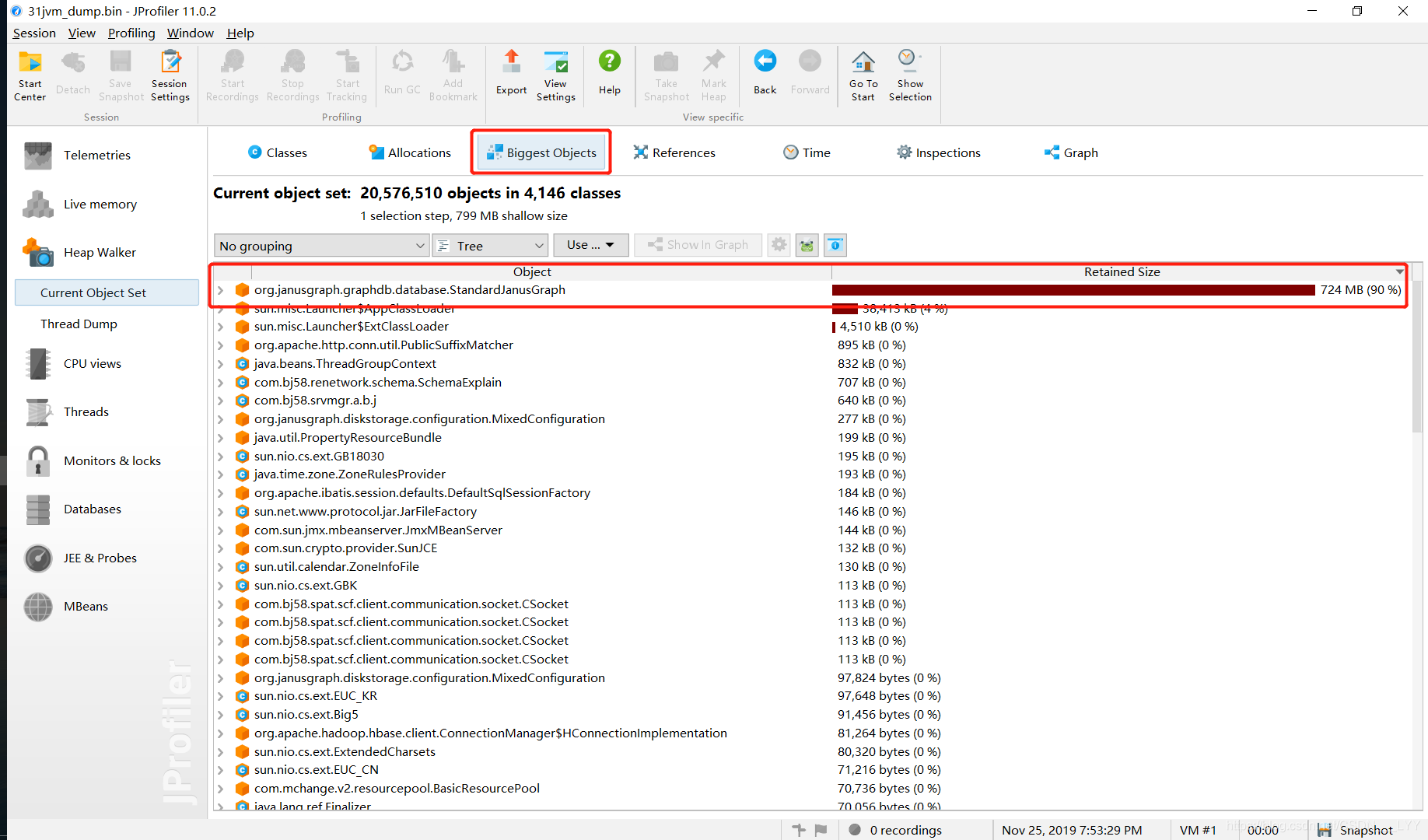
从上图中,我们发现org.janusgraph.graphdb.database.StandardJanusGraph这个对象居然占用了高达724M的内存! 看来内存泄漏八九不离十就是这个对象的问题了!
再点开看看 ,如下图,可以发现是一个openTransactions的类型为ConcurrentHashMap的数据结构:
这到底是什么对象呢,去项目中查找一下,打开idea-打开项目-双击shift键-打开全局类查找-输入StandardJanusGraph,如下图:
发现是我们项目使用的图数据库janusgraph的一个类,找到对应的数据结构:
类型定义:
private Set<StandardJanusGraphTx> openTransactions;初始化为一个ConcurrentHashMap:
openTransactions = Collections.newSetFromMap(new
ConcurrentHashMap<StandardJanusGraphTx, Boolean>(100,
0.75f, 1));观察上述代码,我们可以看到,里面的存储的StandardJanusGraphTx从字面意义上理解是janusgraph框架中的事务对象,下面往上追一下代码,看看什么时候会往这个Map中赋值:
// 找到执行openTransactions.add()的方法
public StandardJanusGraphTx newTransaction(final TransactionConfiguration configuration) {
if (!isOpen) ExceptionFactory.graphShutdown();
try {
StandardJanusGraphTx tx = new StandardJanusGraphTx(this, configuration);
tx.setBackendTransaction(openBackendTransaction(tx));
openTransactions.add(tx); // 注意! 此处对上述的map对象进行了add
return tx;
} catch (BackendException e) {
throw new JanusGraphException("Could not start new transaction", e);
}
}
// 上述发现,是一个newTransaction,创建事务的一个方法,为确保起见,再往上跟找到调用上述方法的类:
public JanusGraphTransaction start() {
TransactionConfiguration immutable = new ImmutableTxCfg(isReadOnly, hasEnabledBatchLoading,
assignIDsImmediately, preloadedData, forceIndexUsage, verifyExternalVertexExistence,
verifyInternalVertexExistence, acquireLocks, verifyUniqueness,
propertyPrefetching, singleThreaded, threadBound, getTimestampProvider(), userCommitTime,
indexCacheWeight, getVertexCacheSize(), getDirtyVertexSize(),
logIdentifier, restrictedPartitions, groupName,
defaultSchemaMaker, customOptions);
return graph.newTransaction(immutable); // 注意!此处调用了上述的newTransaction方法
}
// 接着找上层调用,发现了最上层的方法
public JanusGraphTransaction newTransaction() {
return buildTransaction().start(); // 此处调用了上述的start方法
} 在我们对图数据库中图数据操作的过程中,采用的是手动创建事务的方式,在每次查询图数据库之前,我们都会调用类似于dataDao.begin()代码,
其中就是调用的public JanusGraphTransaction newTransaction()这个方法;
最后,我们简单的看下源码可以发现,从上述内存泄漏的map中去除数据的逻辑就是commit事务的接口,调用链如下:
public void closeTransaction(StandardJanusGraphTx tx) {
openTransactions.remove(tx); // 从map中删除StandardJanusGraphTx对象
}
private void releaseTransaction() {
isOpen = false;
graph.closeTransaction(this); // 调用上述closeTransaction方法
vertexCache.close();
}
public synchronized void commit() {
Preconditions.checkArgument(isOpen(), "The transaction has already been closed");
boolean success = false;
if (null != config.getGroupName()) {
MetricManager.INSTANCE.getCounter(config.getGroupName(), "tx", "commit").inc();
}
try {
if (hasModifications()) {
graph.commit(addedRelations.getAll(), deletedRelations.values(), this);
} else {
txHandle.commit(); // 这个commit方法中释放事务也是调用releaseTransaction
}
success = true;
} catch (Exception e) {
try {
txHandle.rollback();
} catch (BackendException e1) {
throw new JanusGraphException("Could not rollback after a failed commit", e);
}
throw new JanusGraphException("Could not commit transaction due to exception during persistence", e);
} finally {
releaseTransaction(); // // 调用releaseTransaction
if (null != config.getGroupName() && !success) {
MetricManager.INSTANCE.getCounter(config.getGroupName(), "tx", "commit.exceptions").inc();
}
}
}
终于,我们找到了内存泄漏的根源所在:项目代码中存在调用了事务begin但是没有commit的代码!
解决问题: 找到内存泄漏接口的代码,并发现了没有commit()的位置,try-catch-finally中添加上了commit()代码;
提交-部署-发布-灰度一台机器后观察内存泄漏的现象消失,GC回收正常;
内存泄漏问题解决,项目如期上线~
大家,有没有遇到过内存泄漏的情况,欢迎在评论区说出你的故事=.=
写这篇文章耗费的时间超出了我的预料,预计2个小时写完,结果花了一下午的时间...
原创不易,如果大家有所收获,希望大家可以点赞评论支持一下~
也欢迎大家关注我的cto博客和微信搜索公众号[匠心Java]支持一下作者,作者定期分享工作中的所见所得~*
事务处理不当,线上接口又双叒内存泄漏了!(附图解问题全过程)
标签:xcache dia 公众号 down 使用方法 申请 value cep lse
原文地址:https://blog.51cto.com/14786935/2488000