标签:每日 dex 爬取 excel 定位 解析 获取 有趣 通过
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取B站热门视频排行榜
2.主题式网络爬虫爬取的内容:统计所有投稿视频的数据综合得分,每日更新数据(作品,播放量,弹幕,作者)
3.主题式网络爬虫设计方案概述:找到网站地址,分析网站源代码,找到自己所需要的数据所在的位置,提取数据,进行数据整理,数据可视化等操作
二、主题页面的结构特征分析
主题页面的结构与特征分析:
找到我们需要的数据,进行找查定位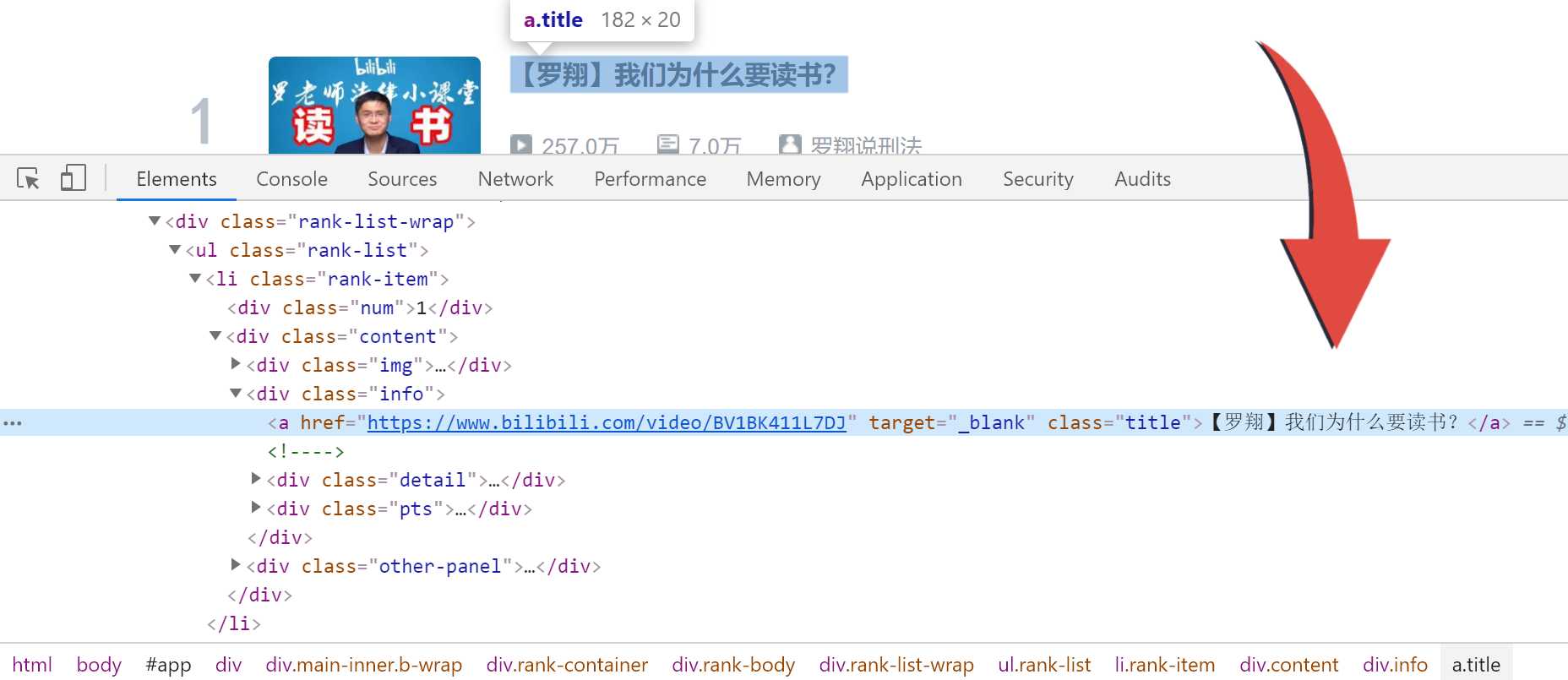
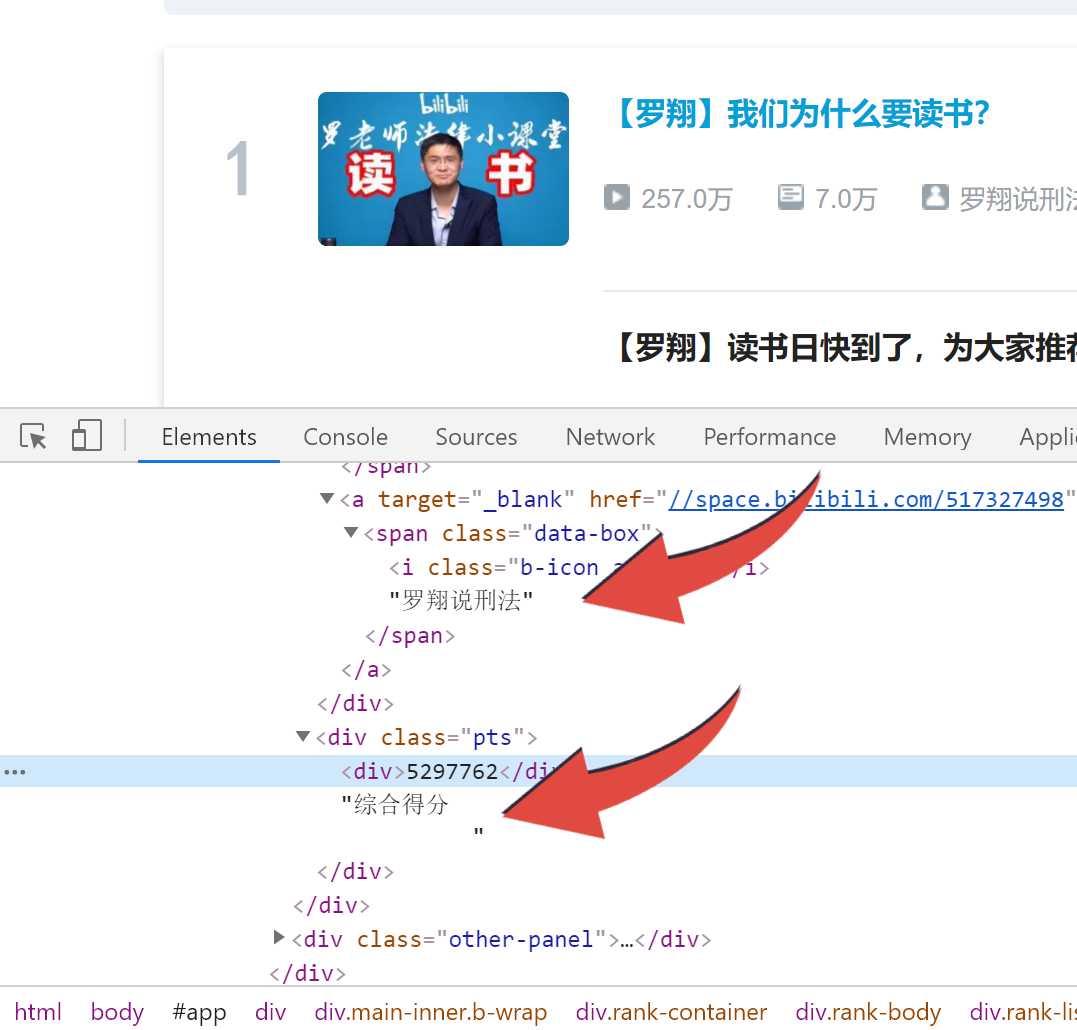
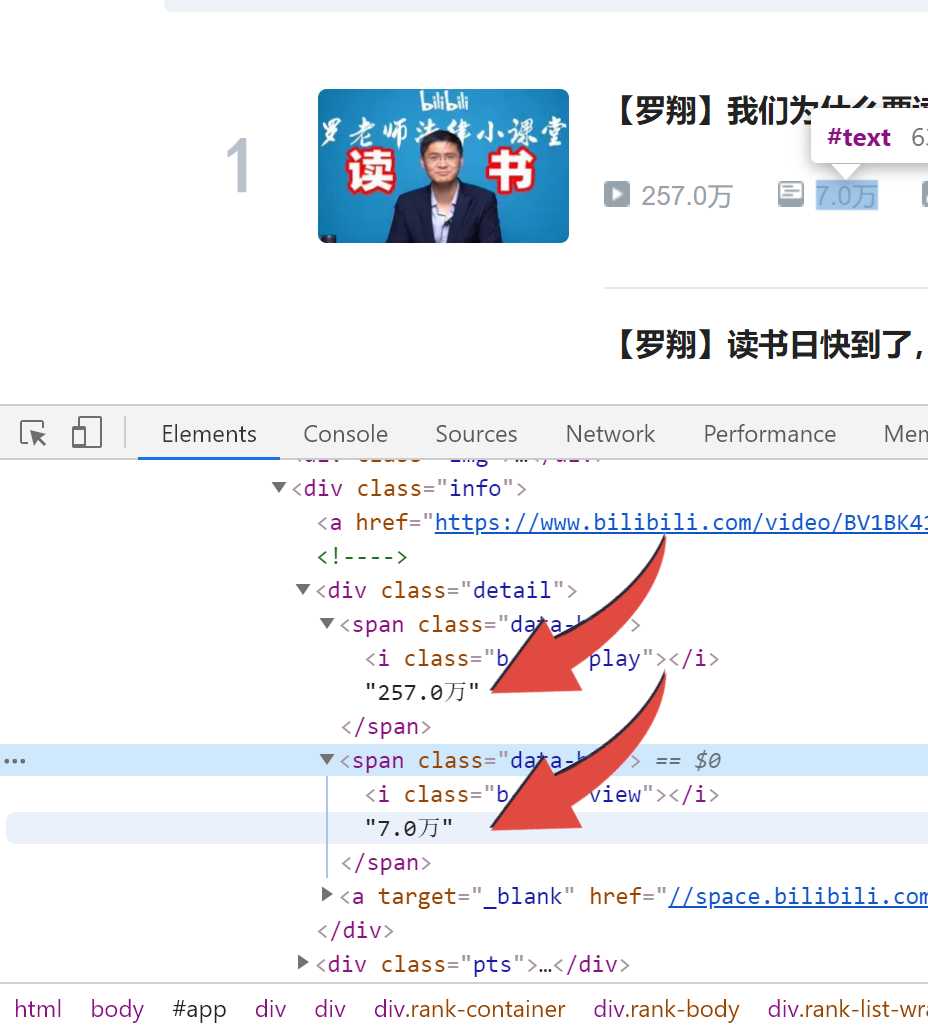
我们需要的内容分别藏在‘a‘,class_="title",‘span‘,class_="data-box",‘div‘,class_="pts"里面
三、网络爬虫程序设计
1.数据爬取与采集
首先爬取网页通用框架
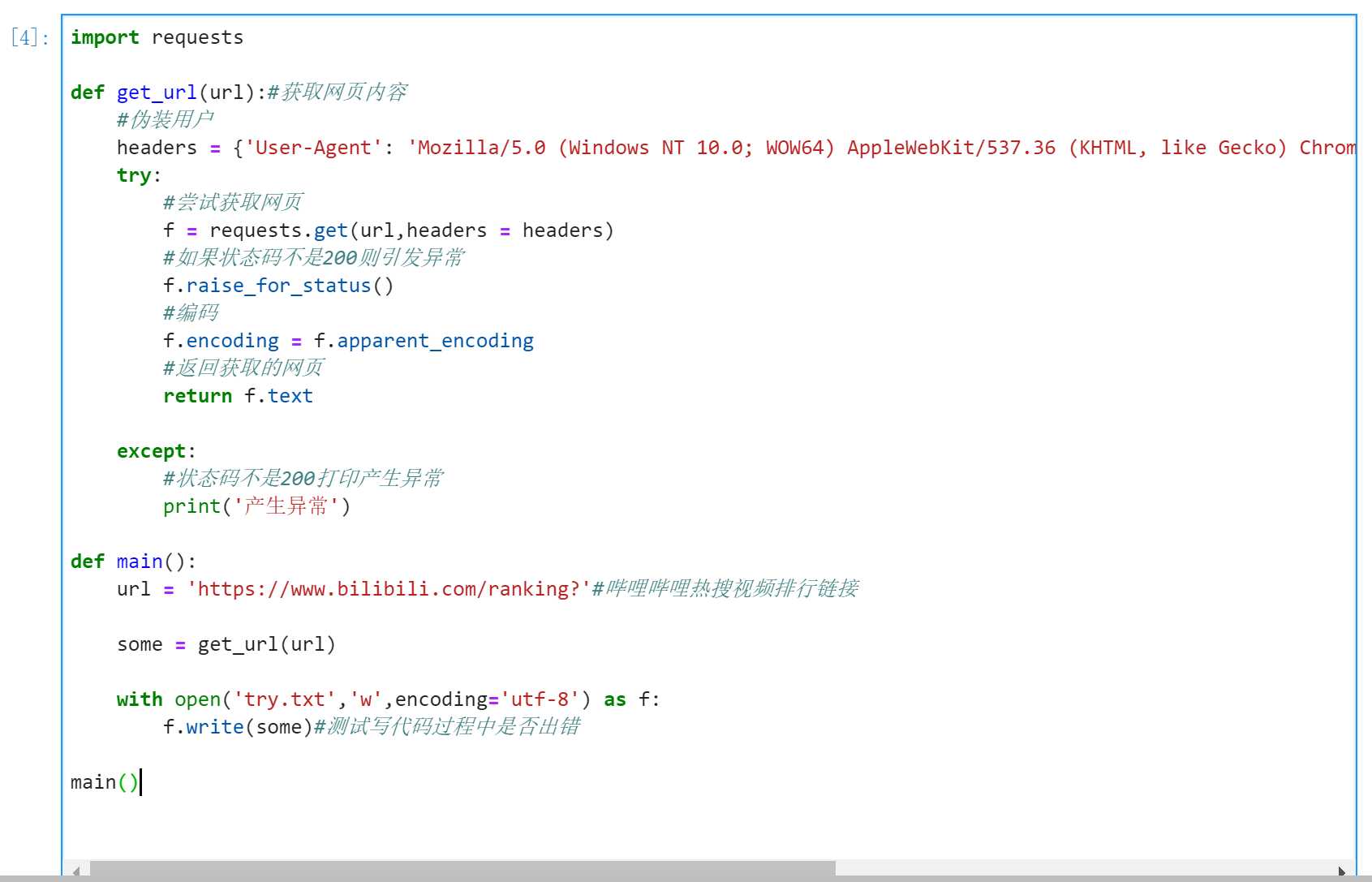
测试爬取的内容
然后再将内容进行解析


测试解析的内容
分析之前的网页源码
尝试把我们需要的内容打印出来
没问题后将刚刚的步骤打包

其他需要爬取的数据同理
大部分整理完后进行细分

整理完全部数据之后导出excel文件方便查看

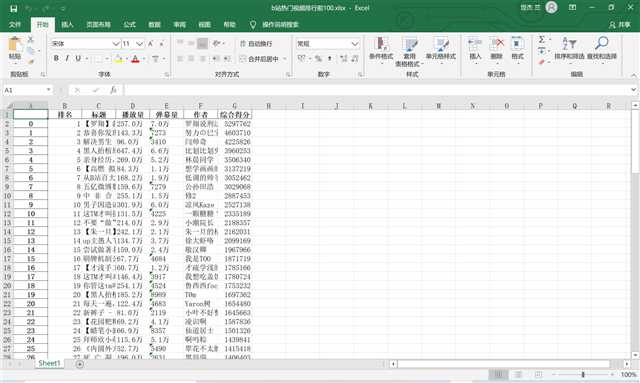
数据整理完毕、开始进行数据可视化
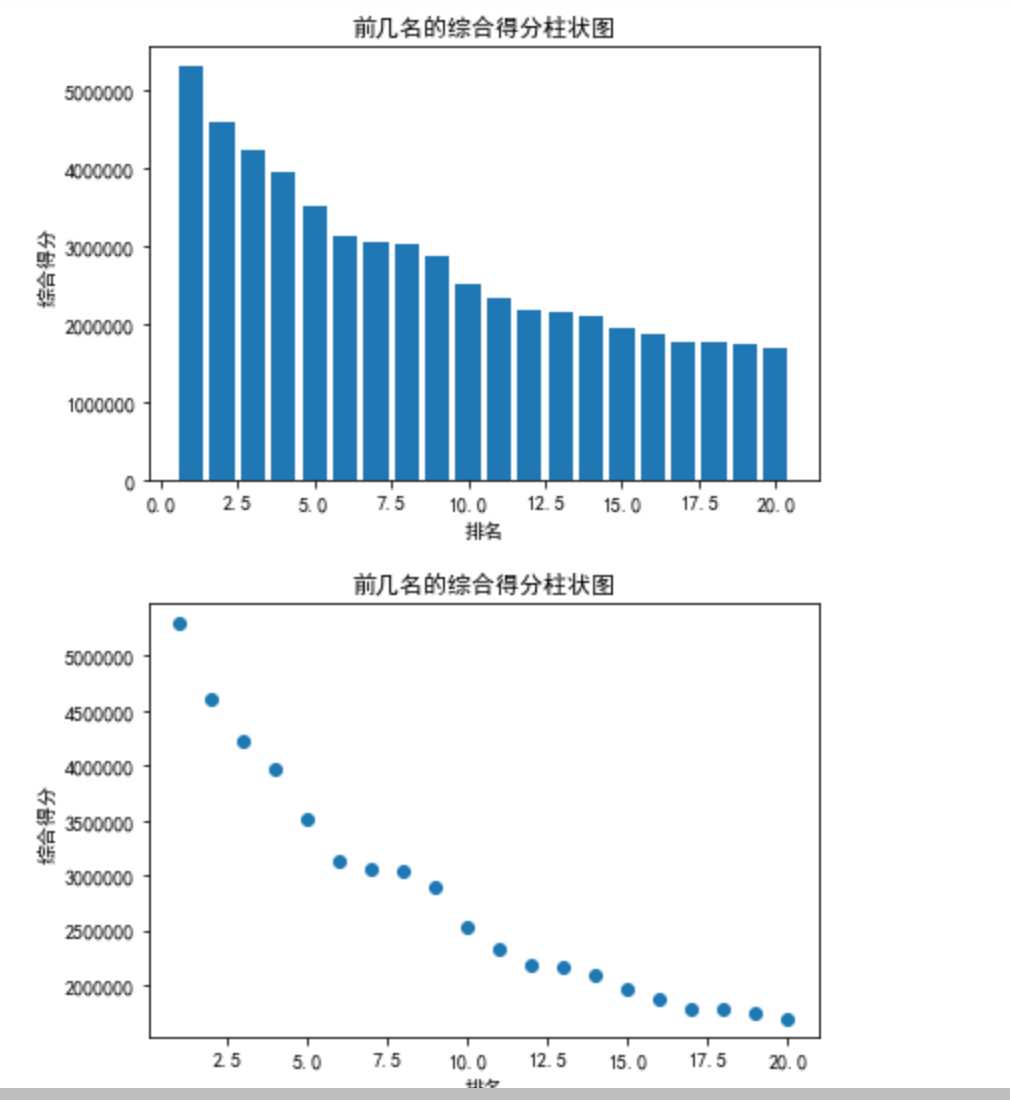
画出柱状图和散点图

输出结果
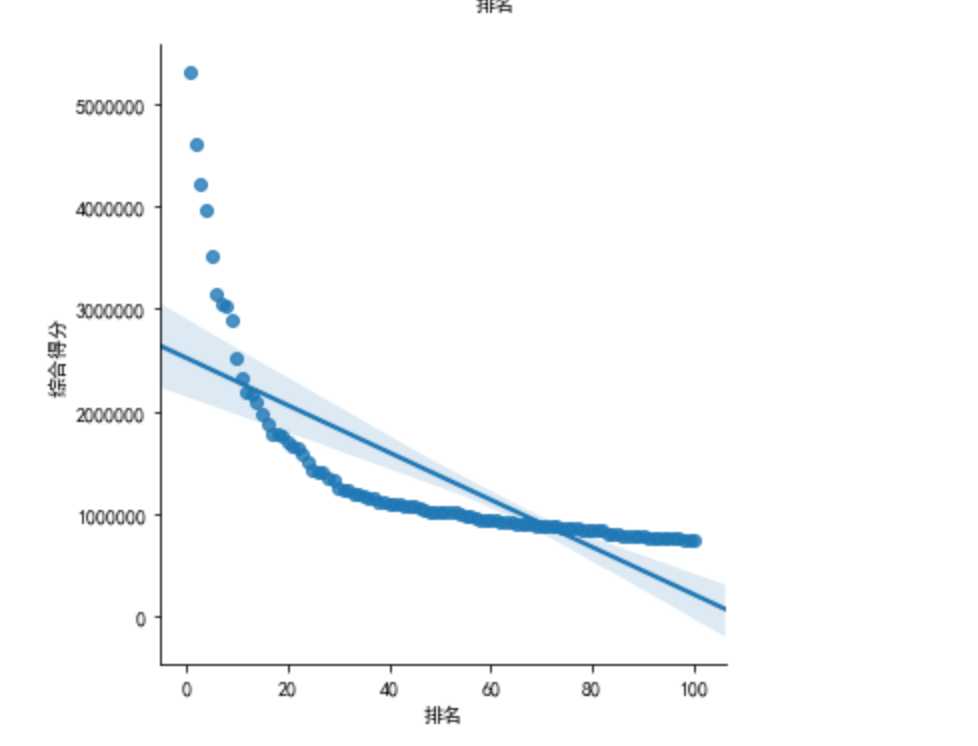
建立变量之间的回归方程

输出结果
四.
附上完整程序代码
#导入需要用到的模块
import requests import bs4 import re import matplotlib.pyplot as plt import seaborn as sns import pandas as pd plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘]#用来正常显示中文 plt.rcParams[‘axes.unicode_minus‘]=False#用来正常显示负号 def get_url(url):#获取网页内容 #伪装用户 headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3706.400 SLBrowser/10.0.4040.400‘} try: #尝试获取网页 f = requests.get(url,headers = headers) #如果状态码不是200则引发异常 f.raise_for_status() #编码 f.encoding = f.apparent_encoding #返回获取的网页 return f.text except: #状态码不是200打印产生异常 print(‘产生异常‘) def bs(text): #将读取到的网页解析 soup = bs4.BeautifulSoup(text,‘html.parser‘) return soup def cont_ent(soup): #提取排行前100的标题 m = soup.find_all(‘a‘,class_="title") n=[] for i in m: n.append(i.text) return (n)#整理成列表 def cont_ent2(soup): #提取播放量,弹幕,作者 x = soup.find_all(‘span‘,class_="data-box") n=[] for i in x: n.append(i.text) return (n)#整理成列表 def cont_ent3(soup): #提取综合得分 k = soup.find_all(‘div‘,class_="pts") n=[] for i in k: #因为分数没有过千万的所以可以搜集千万以内的数字 c=re.search(‘\d?\d?\d?\d?\d?\d?\d?\d?‘,i.text) n.append(eval(c.group())) return (n)#整理成列表 #把之前提取播放量,弹幕,作者再进行整理 def bofang(cone):#播放量 m=3 n=[] for i in cone: if m%3==0: n.append(i) m+=1 return n def danmu(cone):#弹幕 m=2 n=[] for i in cone: if m%3==0: n.append(i) m+=1 return n def zuozhe(cone):#作者 m=1 n=[] for i in cone: if m%3==0: n.append(i) m+=1 return n def main(): #哔哩哔哩热搜视频排行链接 url = ‘https://www.bilibili.com/ranking?‘ #获取网页 some = get_url(url) #解析网页 soup = bs(some) ‘‘‘with open(‘try2.txt‘,‘w‘,encoding=‘utf-8‘) as f: f.write(soup.text)#测试写代码过程中是否出错‘‘‘ #数据处理 #提取标题 title = cont_ent(soup) #提取播放量,弹幕,作者 cone = cont_ent2(soup) #提取综合得分 score = cont_ent3(soup) ‘‘‘ with open(‘title.txt‘,‘w‘,encoding=‘utf-8‘) as f: for i in title: f.write(str(title.index(i)+1)+‘.‘) f.write(i) f.write(‘\n‘) with open(‘cone.txt‘,‘w‘,encoding=‘utf-8‘) as f: for i in cone: f.write(i) f.write(‘\n‘) with open(‘score.txt‘,‘w‘,encoding=‘utf-8‘) as f: for i in score: f.write(i) f.write(‘\n‘) ‘‘‘ #导出数据查看是否有误 bfl = bofang(cone) dm = danmu(cone) zz = zuozhe(cone) df = pd.DataFrame({‘排名‘:range(1,101),‘标题‘:title,‘播放量‘:bfl,‘弹幕量‘:dm,‘作者‘:zz,‘综合得分‘:score}) df.to_excel(‘b站热门视频排行前100.xlsx‘) #因数据太多所以挑排名前几的作图 #柱状图 plt.bar(range(1,21),score[:20]) plt.xlabel(‘排名‘) plt.ylabel(‘综合得分‘) plt.title(‘前几名的综合得分柱状图‘) plt.show() #散点图 plt.scatter(range(1,21),score[:20]) plt.xlabel(‘排名‘) plt.ylabel(‘综合得分‘) plt.title(‘前几名的综合得分柱状图‘) plt.show() #回归分析 file_path = "b站热门视频排行前100.xlsx" dataf = pd.read_excel(file_path) sns.lmplot(x=‘排名‘,y=‘综合得分‘,data=dataf) main()
五、结论
1.排行是通过综合得分来进行排行,弹幕和播放量有一定的影响,吸引人的标题和视频的质量才是决定的关键
2.能够巩固之前学到的新知识,最好每隔一段时间前来复习一遍,网络爬虫很有趣。
标签:每日 dex 爬取 excel 定位 解析 获取 有趣 通过
原文地址:https://www.cnblogs.com/lanshj/p/12723146.html