标签:i+1 todo lse 使用 next col nbsp 输入数据 conf
写在前面
我之前使用的LSTM计算单元是根据其前向传播的计算公式手动实现的,这两天想要和TensorFlow自带的tf.nn.rnn_cell.BasicLSTMCell()比较一下,看看哪个训练速度快一些。在使用tf.nn.rnn_cell.BasicLSTMCell()进行建模的时候,遇到了模型保存、加载的问题。
查找了一些博主的经验,再加上自己摸索,在这里做个笔记,总结经验。其中关键要素有以下3点:
1.需要保存哪些变量(tensor),就要给哪些变量取名字(即name=‘XXXXX‘)。
2.将tf.train.Saver()与需要保存的变量(tensor)定义在一个函数里,否则保存会出错。
3.加载模型的时候,先加载图,再加载变量(tensor)。
下面通过实例进行描述。
模型保存
tf.train.Saver()可以自动保存变量和计算图。
保存前注意!!!需要对要保存的变量命名,即属性中的name=XXX
下面是使用tf.nn.rnn_cell.BasicLSTMCell()自建的一个LSTM_Cel
1 class LSTM_Cell(object): 2 # train_data 格式示例,batch_size*num_steps*input_dim 批大小*时间窗口长度*单时间节点输入维度 3 # train_label格式示例,batch_size*1 # TODO 该模型紧输出一维结果。 4 # input_dim 格式 int, 输入数据在单时间节点上的维度 5 # num_nodes 神经元数目/维度 6 def __init__(self, train_data, train_label, input_dim, batch_size=10, num_nodes=64): 7 tf.reset_default_graph() 8 self.num_nodes = num_nodes 9 self.input_dim = input_dim 10 self.train_data = train_data 11 self.train_label = train_label 12 self.batch_size = batch_size 13 gpu_options=tf.GPUOptions(per_process_gpu_memory_fraction=0.666) 14 self.sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) 15 16 def loss_func(self,lr=0.001): 17 self.w = tf.Variable(tf.truncated_normal([self.num_nodes, 1], -0.1, 0.1),name=‘w‘) # 1 是指输出维度,这里预测一个值,因此维度是1 18 self.b = tf.Variable(tf.zeros([1]),name=‘b‘) 19 self.batch_in = tf.placeholder(tf.float32, [None, self.train_data.shape[1], self.input_dim],name=‘batch_in‘) 20 self.batch_out = tf.placeholder(tf.float32, [None, 1],name=‘batch_out‘) 21 lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self.num_nodes,forget_bias=1.0,state_is_tuple=True) 22 # init_state = lstm_cell.zero_state(self.batch_in[0],dtype=tf.float32) 23 output, final_state = tf.nn.dynamic_rnn(lstm_cell, self.batch_in, time_major=False, dtype=tf.float32) # initial_state=init_state, 24 self.y_pre = tf.nn.sigmoid(tf.matmul(final_state[1], self.w) + self.b,name="y_pre") 25 self.mse = tf.sqrt(tf.reduce_mean(tf.square(self.y_pre-self.batch_out)),name=‘mse‘) 26 self.cross_entropy = -tf.reduce_mean(self.batch_out * tf.log(self.y_pre),name=‘cross_entropy‘) 27 self.train_op = tf.train.GradientDescentOptimizer(lr).minimize(self.mse) 28 self.saver = tf.train.Saver() 29 30 def train_model(self,savepath,epochs=1000): 31 self.sess.run(tf.global_variables_initializer()) 32 for i in range(epochs): 33 for j in range(int(len(self.train_data)/self.batch_size)): 34 batch_i = self.train_data[j*self.batch_size:(j+1)*self.batch_size] 35 batch_o = self.train_label[j*self.batch_size:(j+1)*self.batch_size] 36 self.sess.run(self.train_op, feed_dict={self.batch_in:batch_i, 37 self.batch_out:batch_o.reshape(self.batch_size,1)}) 38 if (i+1)%200==0: 39 print(‘epoch:%d‘%(i+1),self.sess.run(self.mse,feed_dict={self.batch_in:batch_i, 40 self.batch_out:batch_o.reshape(self.batch_size,1)})) 41 save_path = self.saver.save(self.sess, savepath) 42 print("模型保存于: ", save_path)
在LSTM_Cell类中,构造函数定义了一些固定参数以及TensorFlow会话(tf.Session()),而我们所要保存的变量(tensor)都在loss_func()函数中定义。包括:
①最后一个全连接层的w和b;
②输入、输出变量的占位符batch_in,batch_out;
③LSTM单元的计算过程;
④计算最终计算结果y_pre,均方根误差mse,交叉熵计算结果cross_entropy,使用随机梯度下降的训练步骤train_op;
⑤存储器tf.train.Saver()。
在本例中,只有变量’w’, ’b’, ’batch_in’, ’batch_out’, ’y_pre’, ’mse’, ’cross_entropy’在属性中有过命名,会被保存下来。
这里,tf.train.Saver()只能保存本函数(即loss_func)中定义的变量(tensor)。
train_model()函数实现训练过程,并调用self.saver.save(self.sess, savepath)来对模型及命名了的变量(tensor)进行保存。
下面是调用LSTM_Cell类进行训练并保存模型的代码:
1 # 初始化LSTM类 2 lstm_obj = LSTM_Cell(sample_input,sample_output,input_dim=1,batch_size=_batch_size,num_nodes=hidden_size) 3 lstm_obj.loss_func(lr) # 构建计算图 4 # TODO 训练 5 lstm_obj.train_model(savepath=saved_path,epochs=epochs)
其中,保存路径为
1 saved_path = "./standard_LSTM/models/Basic_LSTM_TF_models/59model.ckpt"
最终得到的保存结果为下方4个文件(暂时无视两个png图片)
.meta文档是计算图保存的位置,.data是参数数据,后面的00000-of-00001是模型的版本号。
模型加载
加载困扰了我很久,后面经过摸索才知道有两个关键部分,一个是计算图的加载,一个是变量的加载,两者缺一不可。
LSTM_Cell类中,加载函数(load_model)定义如下。
1 def load_model(self,savepath): 2 len_last = len(savepath.split(‘/‘)[-1]) 3 self.saver = tf.train.import_meta_graph(savepath+‘.meta‘) 4 self.saver.restore(self.sess,tf.train.latest_checkpoint(savepath[:-len_last])) # 加载最后一个模型 5 self.graph = tf.get_default_graph() 6 tensor_name_list = [tensor.name for tensor in self.graph.as_graph_def().node] 7 self.w = self.graph.get_tensor_by_name(‘w:0‘) 8 self.b = self.graph.get_tensor_by_name(‘b:0‘) 9 self.batch_in = self.graph.get_tensor_by_name("batch_in:0") 10 self.batch_out = self.graph.get_tensor_by_name("batch_out:0") 11 self.y_pre = self.graph.get_tensor_by_name(‘y_pre:0‘) 12 self.mse = self.graph.get_tensor_by_name(‘mse:0‘) 13 self.cross_entropy = self.graph.get_tensor_by_name(‘cross_entropy:0‘)
首先定义一个self.saver,来辅助加载图及变量。
第一步加载图,即tf.train.import_meta_graph(savepath+‘.meta‘),就是加载上图中的 59model.ckpt.meta
saver.restore()函数将模型参数进行加载,savepath[:-len_last]是指保存模型的文件夹路径,即"./standard_LSTM/models/Basic_LSTM_TF_models/" ,将模型加载到默认的计算图中(default_graph)。
此时,各变量(即tensor)已经在计算图中了,但要正常调用,还需要从图中取出并将其设置成变量。
具体方法是先取得默认的计算图self.graph,再通过get_tensor_by_name()方法将tensor实例化,每个tensor的名称与模型保存时name=”XXX”的名称相同,并且后方需要加上:<index>,不重名的情况下这个index一般是0。
也有博主说tensor的名称可以在tensor_name_list中查看到,但我打印出来后发现这个list太长,不大实用。
这时候就加载模型完毕了,可以调用self.sess对self.y_pre、self.mse进行计算。
示例计算如下:
1 def predict_next_one(self,batch_i): # batch_i长度 为样本时间序列长度 2 temp = self.sess.run(self.y_pre,feed_dict={self.batch_in:batch_i.reshape(1,len(batch_i),1)}) 3 return temp[0][0]
外部的调用方法如下,(构造函数后就不用使用loss_func构建计算过程了,直接加载模型就行。)
1 # 初始化LSTM类 2 lstm_obj = LSTM_Cell(sample_input,sample_output,input_dim=1,batch_size=_batch_size,num_nodes=hidden_size) 3 # TODO 加载模型 4 lstm_obj.load_model(savepath=saved_path)
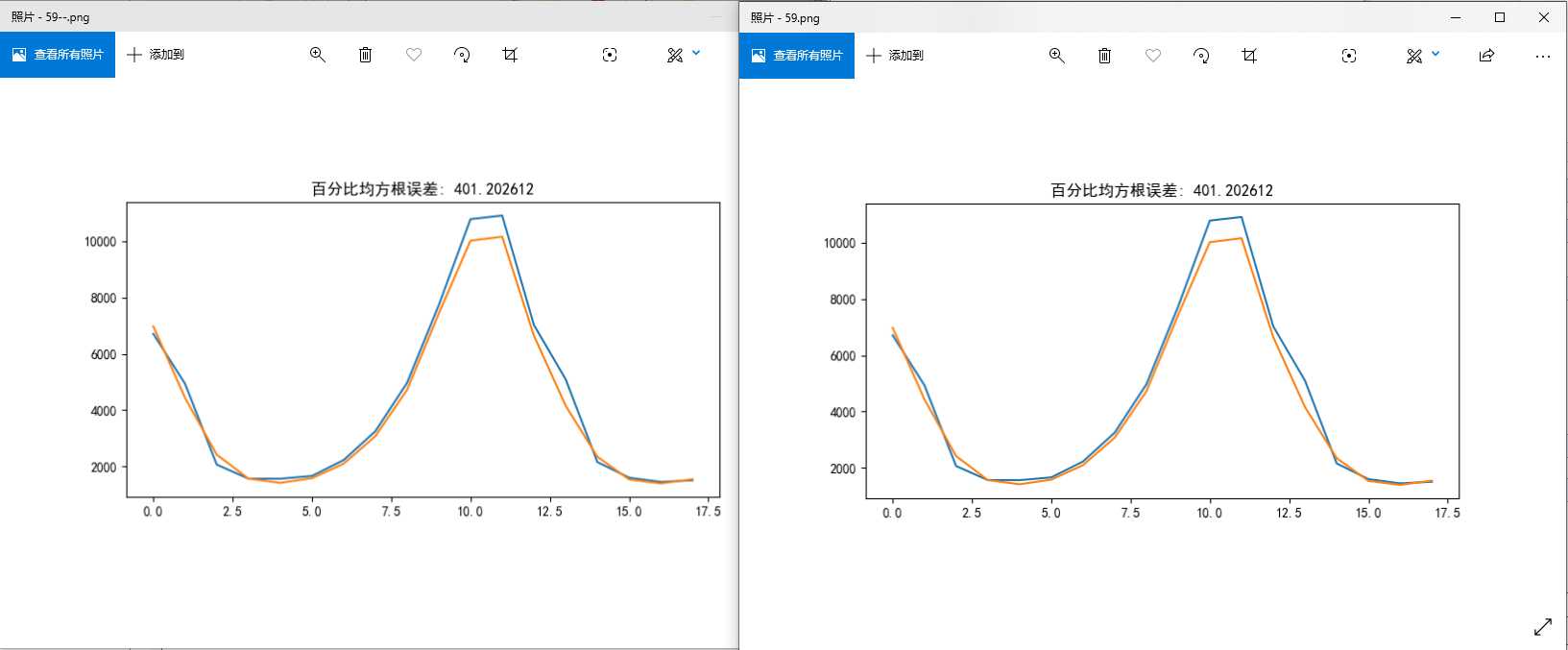
下面两个图是训练完后直接预测以及加载模型再预测的结果,可以看出模型加载后,计算结果与之前一致。
TensorFlow保存、加载模型参数 | 原理描述及踩坑经验总结
标签:i+1 todo lse 使用 next col nbsp 输入数据 conf
原文地址:https://www.cnblogs.com/NosenLiu/p/12724688.html