标签:params stat print mat inline rop 变量 top black
import pandas as pd
import numpy as np
data=pd.read_excel(r‘/Users/fangluping/Desktop/望潮府.xlsx‘,encoding=‘utf_8_sig‘,
usecols=[‘销售状态‘,‘产品类型‘,‘户型‘,‘户型配置‘,‘预测建筑面积‘,‘表价总价‘,‘建面表单价‘,‘价格方案名称‘,‘调价幅度(%)‘],
skipfooter=1)
#数据清洗
data.销售状态[data.销售状态==‘未售‘]=0
data.销售状态[data.销售状态 !=0]=1
data[‘业态‘]=[x.split(‘-‘)[1] for x in data.产品类型.dropna()]
data.drop([‘产品类型‘,‘价格方案名称‘],axis=1,inplace=True)
#哑变量处理
dummy=pd.get_dummies(data[[‘户型‘,‘户型配置‘,‘业态‘]])
#水平合并data和哑变量数据集
data=pd.concat([data,dummy],axis=1)
data.drop([‘户型‘,‘户型配置‘,‘业态‘],axis=1,inplace=True)
数据清洗完毕,找出最佳参数组:
#使用网格法找出最优越模型参数
from sklearn.model_selection import GridSearchCV
from sklearn import tree
#预设各参数的不同选项值
max_depth=[2,3,4,5,6]
min_samples_split=[2,4,6,8]
min_samples_leaf=[2,4,8,10,12]
#将各参数的值以字典的形式组织起来
parameters={‘max_depth‘:max_depth,‘min_samples_split‘:min_samples_split,‘min_samples_leaf‘:min_samples_leaf}
#网格搜索法,测试不同的参数值
grid_dtcateg=GridSearchCV(estimator=tree.DecisionTreeClassifier(),param_grid=parameters,cv=10)
#模型拟合
grid_dtcateg.fit(X_train,y_train)
#返回最佳组合的参数值
print(grid_dtcateg.best_params_)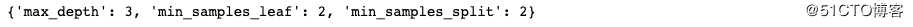
单棵决策树的预测准确率:
#单棵决策树建模
from sklearn import metrics
#构建分类决策树
CART_Class=tree.DecisionTreeClassifier(max_depth=3,min_samples_leaf=2,min_samples_split=2)
#模型拟合
decision_tree=CART_Class.fit(X_train,y_train)
#模型在测试集上的预测
pred=CART_Class.predict(X_test)
#模型的准确率
print(‘模型在测试集的预测准确率为:‘,metrics.accuracy_score(y_test,pred))
from matplotlib import pyplot as plt
y_score=CART_Class.predict_proba(X_test)[:,1]
fpr,tpr,threshold=metrics.roc_curve(y_test,y_score)
#计算AUC的值
roc_auc=metrics.auc(fpr,tpr)
#绘制面积图
plt.stackplot(fpr,tpr,color=‘steelblue‘,alpha=0.5,edgecolor=‘black‘)
#添加边际线
plt.plot(fpr,tpr,color=‘black‘,lw=1)
#添加对角线
plt.plot([0,1],[0,1],color=‘red‘,linestyle=‘-‘)
#添加文本信息
plt.text(0.5,0.3,‘ROC curve(area=%0.2f)‘%roc_auc)
#添加x轴与y轴标签
plt.xlabel(‘1-Specificity‘)
plt.ylabel(‘Sensitivity‘)
#显示图形
plt.show()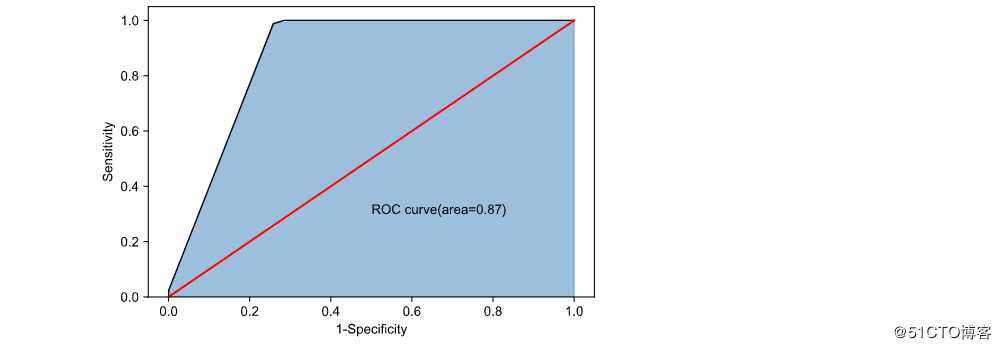
随机森林预测准确性:
#构建随机森林,随机森林可以提高单棵决策树的预测准确度
from sklearn import ensemble
RF_class=ensemble.RandomForestClassifier(n_estimators=200,random_state=1234)
#随机森林的拟合
RF_class.fit(X_train,y_train)
#模型在测试集上的预测
RFclass_pred=RF_class.predict(X_test)
#模型的准确率
print(‘模型在测试集的预测准确率为:‘,metrics.accuracy_score(y_test,RFclass_pred))
#计算绘图数据
y_score=RF_class.predict_proba(X_test)[:,1]
fpr,tpr,threshold=metrics.roc_curve(y_test,y_score)
#计算AUC的值
roc_auc=metrics.auc(fpr,tpr)
#绘制面积图
plt.stackplot(fpr,tpr,color=‘steelblue‘,alpha=0.5,edgecolor=‘black‘)
#添加边际线
plt.plot(fpr,tpr,color=‘black‘,lw=1)
#添加对角线
plt.plot([0,1],[0,1],color=‘red‘,linestyle=‘-‘)
#添加文本信息
plt.text(0.5,0.3,‘ROC curve(area=%0.2f)‘%roc_auc)
#添加x轴与y轴标签
plt.xlabel(‘1-Specificity‘)
plt.ylabel(‘Sensitivity‘)
#显示图形
plt.show()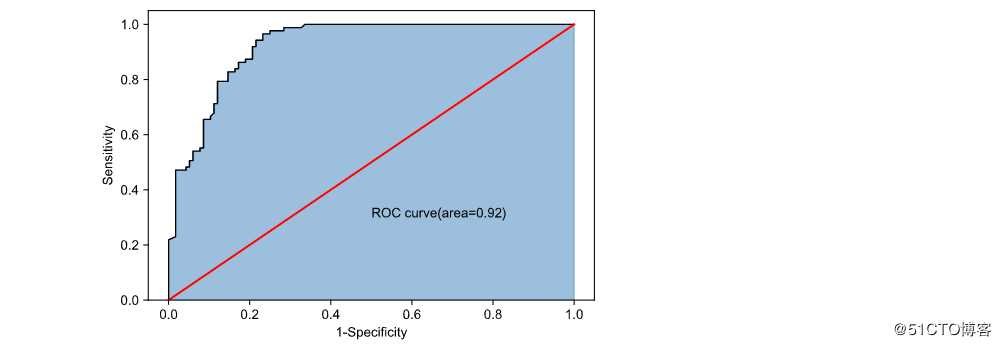
plt.rcParams[‘font.sans-serif‘] = [‘Arial Unicode MS‘]
plt.rcParams[‘axes.unicode_minus‘] = False
%config InlineBackend.figure_format = ‘svg‘
#自变量的重要性程度
importance=RF_class.feature_importances_
#构建序列用于绘图
Impt_Series=pd.Series(importance,index=X_train.columns)
#对序列排序绘图
Impt_Series.sort_values(ascending=True).plot(kind=‘barh‘)
plt.show()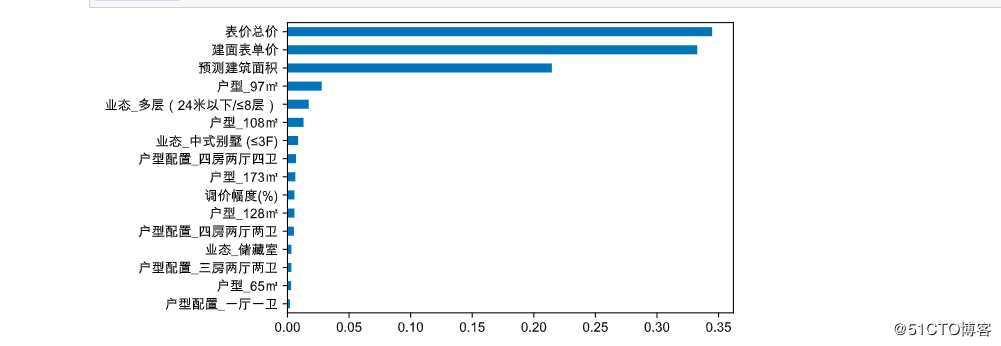
从图中可以看出,影响房屋出售率的因素,只有房价,不管是总价,还是单价,除此之外,还有可售面积。其他户型、业态等因素对房屋出售几乎没有影响。
标签:params stat print mat inline rop 变量 top black
原文地址:https://blog.51cto.com/14534896/2488421