标签:pen sea 连接 pat user book style upload main
jieba库的使用和好玩的词云
一、jieba库使用
(1)安装:
输入命令:pip install jieba(如图:在后面加上所示网址超级快)

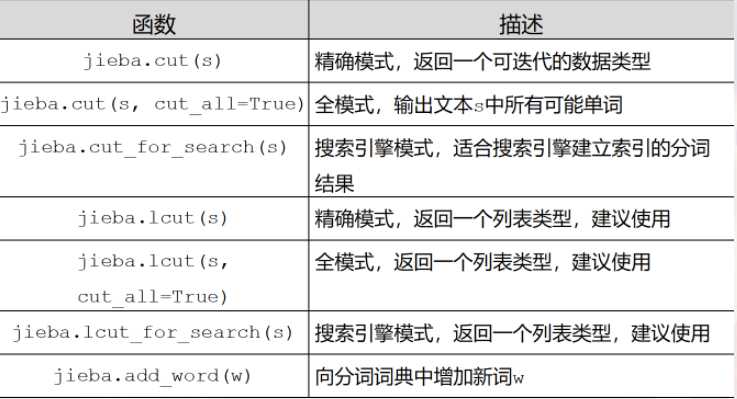
jieba库分词的三种模式:
1、精准模式:把文本精准地分开,不存在冗余
2、全模式:把文中所有可能的词语都扫描出来,存在冗余
3、搜索引擎模式:在精准模式的基础上,再次对长词进行切分
精准模式:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家")
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\25282\AppData\Local\Temp\jieba.cache
Loading model cost 0.869 seconds.
Prefix dict has been built succesfully.
[‘中国‘, ‘是‘, ‘一个‘, ‘伟大‘, ‘的‘, ‘国家‘]
全模式:
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
[‘中国‘, ‘国是‘, ‘一个‘, ‘伟大‘, ‘的‘, ‘国家‘]
搜索引擎模式:
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
[‘中华‘, ‘华人‘, ‘人民‘, ‘共和‘, ‘共和国‘, ‘中华人民共和国‘, ‘是‘, ‘伟大‘, ‘的‘]
向分词词典增加新词:
>>> jieba.add_word("蟒蛇语言")
>>> jieba.lcut("python是蟒蛇语言")
[‘python‘, ‘是‘, ‘蟒蛇语言‘]
二、关于词云
WordCloud库常规方法
| 函数 | 简述 |
| w.generate(txt) | 向WordCloud对象w中加载文本txt |
| w.to_file(file name) | 将词云输出为图像文件,例如.png格式 |
步骤:
| 函数 |
简述 |
| font_path | 字体路径,做中文词云必须设置字体,否则无法显示 |
| width | 输出的画布宽度,默认为400像素 |
| height | 输出的画布高度,默认为200像素 |
| max_words | 要显示的词的最大个数,默认为200 |
| stop_words | 指定词云的排除词列表,即不显示的单词列表 |
| max_font_size | 显示的最大字体大小 |
| min_font_size | 显示的最小字体大小 |
| background_color | 指定词云图片的背景颜色,默认为黑色 |
| mask | 指定词云形状,默认为长方形,需要引用imread()函数 |
实例:
(以红楼梦为例)
下载一个《红楼梦》文本 这里将文本命名为 hongloumeng.txt
win10电脑文本编码默认为ASCII码,我们应将其改为UTF-8编码,打开 hongloumeng.txt --文件--另存为--编码--UTF-8,取名为 shitouji.txt ,按照上述方法找到新的文本位置即可。改正的代码如下:
代码如下:
#DreaminRedMansions.py import jieba #调用jieba库 txt = open("D:\我爱学习\python3\wenben\shitouji.txt","r",encoding="UTF-8").read() #打开txt文件阅读 words = jieba.lcut(txt) #分词 counts = {} #建立一个空字典 for word in words: if len(word)==1: continue else: counts[word]=counts.get(word,0) + 1 #遍历每个中文单词,通过字典来计数 items = list(counts.items()) #将字典counts转换为列表类型 items.sort(key=lambda x:x[1],reverse = True) #对列表进行排序 for i in range(20): word,count = items[i] print("{0:<10}{1:>5}".format(word,count)) #打印出前20个词
结果如图:

词云展现:
运用jieba库和wordcloud库,代码如下:注: .join( )函数: 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的长字符串
代码如下:
from wordcloud import WordCloud import jieba def create_word_cloud(): path_txt = ‘D:\我爱学习\python3\wenben\\shitouji.txt‘ text = open(path_txt,"r",encoding="UTF-8").read() wordlist = jieba.lcut(text) # jieba分词 wl = " ".join(wordlist) # 设置词云 w = WordCloud( # 设置背景颜色为白色 background_color="white", # 设置最大显示的词云数为200 max_words=200, # 字体的一般路径--宋体 font_path=‘simsun.ttc‘, height=1200, width=1600, # 设置字体最大的字体大小 max_font_size=100, # 设置配色方案 random_state=100, ) w.generate(wl) # 生成词云 w.to_file(‘img_book1.png‘) # 把词云保存下 if __name__ == ‘__main__‘: create_word_cloud()
结果如图:

标签:pen sea 连接 pat user book style upload main
原文地址:https://www.cnblogs.com/linantelope/p/12728654.html