标签:analysis 非共享 问题 lan nta 适用于 图片 可变 摘要
目标跟踪与分割
Fast Online Object Tracking and Segmentation: A Unifying Approach
论文链接:
摘要
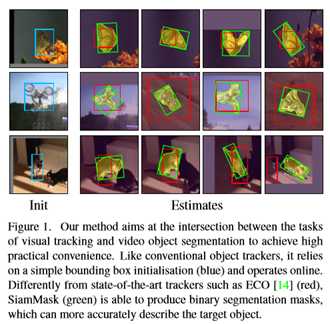
本文介绍了如何用一种简单的方法实现视频目标的实时跟踪和半监督视频目标分割。本文的方法被称为SiamMask,通过增加二元分割任务的损失,改进了目前流行的全卷积siames目标跟踪方法的模糊训练过程。经过训练后,SiamMask仅依赖于一个边界框初始化并在线操作,以每秒55帧的速度生成与类无关的对象分割遮罩和旋转边界框。尽管其简单、多功能和快速,本文的策略使本文能够在VOT-2018上的实时跟踪器中建立一个新的最先进的状态,同时展示在DAVIS-2016和DAVIS-2017上的半监督视频对象分割任务的竞争性能和最佳速度。
1. Introduction
本文提出了一种简单的多任务学习方法SiamMask,旨在缩小任意目标跟踪与VOS之间的差距。本文的方法的动机是基于完全卷积SiamMask网络的快速跟踪方法的成功[4]训练了数百万对视频帧(例如[31,71,17,67]),以及最近YouTube VOS的可用性[64],这是一个带有像素注释的大型视频数据集。本文的目标是保持这些方法的灵活性和在线速度,同时显著地重新定义它们对目标对象的表示,这仅限于简单的轴对齐边界框。为了实现这一目标,本文同时在三个任务上训练SiamMask网络,每个任务对应不同的策略,以在新的框架中建立目标对象和候选区域之间的对应关系。如Bertineto等人[4]的完全卷积方法,一个任务是以滑动窗口的方式学习目标对象和多个候选对象之间的相似性度量。
输出是一个密集的响应映射,它只指示对象的位置,而不提供有关其空间范围的任何信息。为了重新定义这些信息,本文同时学习两个进一步的任务:使用区域建议网络的边界盒回归[53,31]和类无关的二进制分割[49]。值得注意的是,二进制标签只需要在飞行训练期间计算分割损失,而不是在分割/跟踪期间在线。在本文提出的架构中,每一个任务都由一个不同的分支来表示,这个分支从一个共享的CNN出发,导致最终的损失,这三个输出相加。经过训练后,SiamMask仅依赖于一个边界框初始化,在线操作而无需更新,并以每秒55帧的速度生成对象分割遮罩和旋转边界框。
尽管简单快速,但SiamMask在VOT-2018上为实时目标跟踪问题建立了一个新的技术状态。此外,与DAVIS-2016和DAVIS-2017上最近的半监督VOS方法相比,同样的方法也非常有竞争力,同时以很大的优势成为速度最快的方法。这个结果是通过一个简单的边界框初始化(与掩模相反)来实现的,并且没有采用VOS方法通常使用的昂贵技术,例如微调[39、45、2、60]、数据增强[25、33]和光流[57、2、45、33、10]。
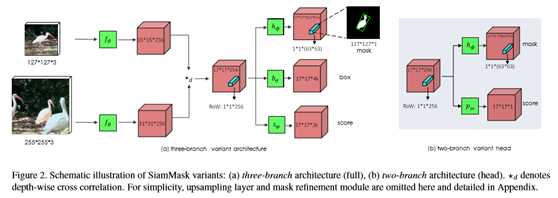
2. Methodology
为了实现在线可操作性和快速性,本文采用了Bertineto等人[4]的全卷积Siamese框架。此外,为了说明本文的方法与作为起点(例如[4,31,71,67,18])的特定完全卷积方法是不可知的,本文将流行的SiamFC[4]和SiamRPN[31]作为两个典型例子。
2.1. Fully-convolutional Siamese networks
SiamFC
Bertineto等人 [4] 提议使用柔性全卷积SiamFC网络作为跟踪系统的基本组成部分,该网络将示例图像z与(较大)搜索图像x进行比较,以获得密集的响应图。z和x分别是以目标对象为中心的w×h裁剪和以目标最后估计位置为中心的较大裁剪。
2.2. SiamMask
与现有的基于低分辨率目标表示的跟踪方法不同,本文论证了产生逐帧二值分割掩模的重要性。为此,本文证明,除了相似性分数和边界框坐标外,全卷积连体网络的行还可以对生成像素级二值掩模所需的信息进行编码。这可以通过扩展现有的SiamMask跟踪与一个额外的分支和损失。
重要的是,分割任务的网络hφ由两个1×1卷积层组成,一个具有256个信道,另一个具有632个信道(图2)。这使得每一个像素分类能够利用包含在整行中的信息,从而在x中拥有其对应的候选窗口的完整视图,这对于消除看起来像目标的实例(如图4的最后一行)之间的歧义至关重要,也称为干扰器[52,71]。为了产生更精确的目标掩模,本文遵循了[50]的策略,该策略使用由上采样层和跳过连接组成的多个增强模块合并低分辨率和高分辨率特征。
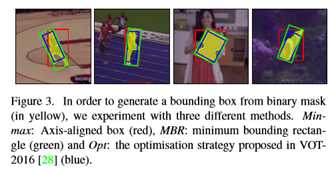
虽然VOS基准需要二进制掩码,但典型的跟踪基准(如VOT[30])需要一个边界框作为目标对象的最终表示。本文考虑三种不同的策略从二进制掩码生成一个边界框(图3):
(1) 轴对齐的边框(最小最大值),
(2) 旋转最小边界矩形(MBR)和
(3) VOT-2016[28]中提出的用于自动边界框生成的优化策略。
2.3. Implementation details
网络体系结构
对于本文的两个变体,本文使用ResNet-50[20]直到第4阶段的最终卷积层作为本文的主干fθ。为了获得更深层的高空间分辨率,本文使用步长1的卷积将输出步长减少到8。此外,本文通过扩大卷积来增加感受野[8]。在本文的模型中,本文在共享骨干网fθ上增加了一个非共享调整层(1×1 conv,256个输出)。为了简单起见,本文在式1中省略它。本文在附录中更详细地描述了网络体系结构。 训练
与SiamFC[4]一样,本文使用示例和搜索分别为127×127和255×255像素的图像块。在训练过程中,本文随机抖动样本并搜索补丁。具体来说,本文考虑了随机平移(高达±8像素)和重缩放(分别为2±1/8和2±1/4的示例和搜索)。网络骨干网接受了ImageNet-1k分类任务的预先培训。本文使用带第一个预热阶段的SGD,在该阶段中,前5个阶段的学习率从10-3线性增加到5×10-3,然后在另外15个阶段的学习率从对数下降到5×10-4。本文使用COCO[35]、ImageNet VID[54]和YouTube VOS[64]来训练所有的模特。
推论
在跟踪过程中,SiamMask只对每帧进行一次评估,没有任何自适应。在本文的两个变体中,本文使用在分类分支中获得最大分数的位置来选择输出掩码。然后,在应用每像素sigmoid后,本文以0.5的阈值对掩模分支的输出进行二值化。在两个分支变量中,对于第一个视频帧之后的每个视频帧,本文使用最小-最大框来确定输出掩码,并将其用作裁剪下一个帧搜索区域的参考。相反,在三分支变体中,本文发现更有效地利用box分支的最高得分输出作为参考。
3. Experiments
在本节中,本文将评估本文在两个相关任务上的方法:视觉对象跟踪(在VOT-2016和VOT-2018上)和半监督视频对象分割(在DAVIS2016和DAVIS-2017上)。本文分别用SiamMask-2B和SiamMask来指代本文的两个分支和三个分支变体。
3.1. Evaluation for visual object tracking
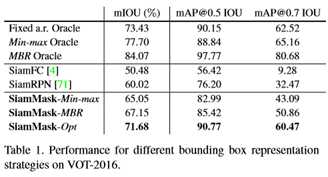
在表1中,本文使用Min max、MBR和Opt方法比较了本文的三个分支变量(在第3.2节末尾和图3中描述)。对于透视图,本文还报告了作为固定和可变长宽比方法代表的SiamFC和SiamRPN的结果,以及三个能够访问每帧背景真实信息并作为不同表示策略上限的oracle。
(1) 固定纵横比oracle使用每帧地面真实区域和中心位置,但将纵横比设置为第一帧之一,并生成一个轴对齐的边界框。
(2) Minmax oracle使用旋转的地面真值边界框的最小包围矩形来生成与轴对齐的边界框。
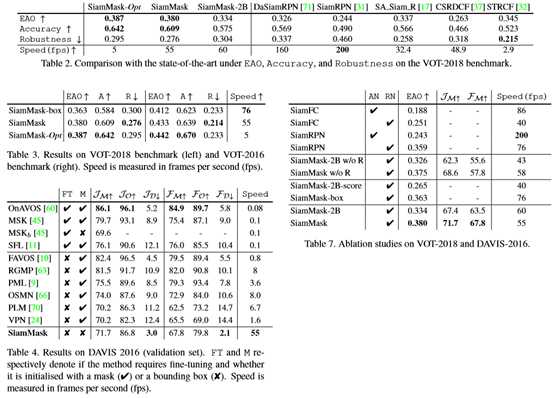
(3) 最后,MBR oracle使用地面真值的旋转最小边界矩形。注意,(1),(2)和(3)可以分别考虑SiamFC、SiamRPN和SiamMask的表示策略的性能上界。表1显示本文的方法实现了最好的mIOU,不管使用的是框生成策略(图3)。尽管SiamMask Opt提供了最高的IOU和mAP,但由于优化过程缓慢,它需要大量的计算资源[28]。SiamMask MBR的mAP@0.5iou为85.4,两个完全卷积基线的w.r.t分别提高了+29和+9.2点。有趣的是,在0.7 IOU:+41.6和+18.4的较高精度范围内,当考虑mAP时,差距显著扩大。值得注意的是,本文的准确度结果与固定长宽比oracle相差不远。此外,比较由oracles表示的上限性能,可以注意到,通过简单地更改边界框表示,有很大的改进空间(例如,固定纵横比和MBR oracles之间+10.6%的mIOU改进)。总的来说,这项研究表明,MBR策略如何从对象的二进制掩码中获取旋转的边界框,与简单地报告轴对齐边界框的流行策略相比,具有显著的优势。 VOT-2018和-2016结果
在表2中,本文将SiamMask的两个变体与MBR策略和SiamMask–Opt与最近在VOT-2018基准上发布的最新状态跟踪程序进行了比较。除非另有说明,否则SiamMask是指本文采用MBR策略的三分支变体。SiamMask的两个变种都实现了出色的性能和实时运行。特别是,本文的三个分支变体的性能明显优于最近表现最好的DaSiamRPN[71],EAO达到0.380,运行速度为55 fps。即使没有盒回归分支,本文简单的两分支变体(SiamMask2B)也能达到0.334的高EAO,这与SA-Siam R[17]相当,并且优于已发表文献中的任何其他实时方法。此外,SiamMask–Opt在EAO为0.387的情况下可以达到最佳性能,但运行速度只有5fps。这是预期的,因为盒子优化策略需要更多的计算来提供更高的IOU。
本文的模型在精度指标下尤其强大,显示出相对于基于相关滤波器的跟踪器CSRDCF[37]和STRCF[32]的显著优势。这并不奇怪,因为SiamMask依赖于更丰富的对象表示,如表1所示。有趣的是,与本文相似的是,(SA Siam R)[17]通过考虑多个旋转和重新缩放的边界框来实现更精确的目标表示。但是,它们的表示仍被限制在固定长宽比框中。表3给出了在VOT-2018和-2016上采用不同盒子生成策略的SiamMask的进一步结果。SiamMask box是指在对掩码分支进行训练的情况下,采用SiamMask的box分支进行推理。本文可以通过使用mask分支来生成框,观察到所有评估指标的明显改进。
3.2. Evaluation for semi-supervised VOS
本文的模型,一旦训练,也可以用于VOS的任务,以实现竞争性能,而不需要在测试时进行任何调整。重要的是,与典型的VOS方法不同,本文的方法可以在线操作,实时运行,只需要简单的边界框初始化。
数据集和设置
本文报告了SiamMask在DAVIS-2016[46]、DAVIS-2017[51]和YouTube VOS[64]基准上的表现。对于这两个DAVIS数据集,本文使用了官方性能度量:Jaccard索引(J)表示区域相似性,F度量(F)表示轮廓精度。对于每个测度C∈{J,F},考虑了三个统计量:平均CM、回忆CO和衰减CD,这三个统计量告诉本文随着时间的推移性能的增益/损失[46]。在[64]之后,YouTube VOS上的最终结果O是四个指标的平均值:J表示已见类别,F表示已见类别,J表示未见类别,F表示未见类别。为了初始化SiamMask,本文从第一帧提供的掩码中提取轴对齐的边界框(最小最大策略,图3)。与大多数VOS方法类似,如果同一视频(DAVIS-2017)中有多个对象,本文只需执行多个推断。
DAVIS和YouTube VOS的结果
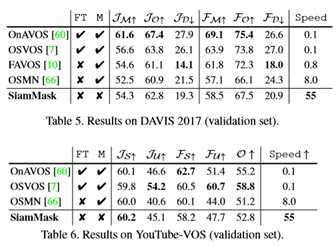
在半监督设置中,VOS方法使用二进制掩码初始化[44],其中许多方法在测试时需要计算密集型技术,例如finetuning[39、45、2、60]、数据增强[25、33]、对MRF/CRF的推断[61、57、40、2]和光流[57、2、45、33、10]。因此,VOS技术需要几分钟来处理一个短序列并不少见。显然,这些策略使得在线应用(这是本文的重点)变得不可能。因此,在本文的比较(表4、表5和表6)中,本文主要关注最新的快速方法。
这三个表显示了SiamMask如何被视为在线VOS的一个强大基线。
首先,它几乎比精确方法快两个数量级,如OnAVOS[60]或SFL[11]。
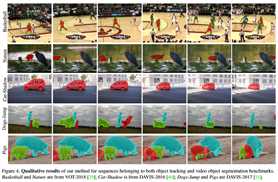
其次,它与不采用精确调谐的最新VOS方法相比具有竞争力,同时其效率是最快方法(即OSMN[66]和RGMP[63])的四倍。有趣的是,本文注意到SiamMask在DAVIS-2016和DAVIS-2017上的区域相似性(JD,)和轮廓精度(FD)均达到低衰减[46]。这表明本文的方法在时间上是稳健的,因此它适用于特别长的序列。VOT和DAVIS序列的SiamMask定性结果如图4和附录所示。尽管速度很快,SiamMask即使在有干扰的情况下也能产生精确的分割掩模。
3.3. Further analysis
在本节中,本文将介绍消融研究、失败案例和本文方法的时间安排。
网络体系结构
在表7中,AN和RN表示本文是否使用AlexNet或ResNet-50作为共享主干fθ(图2),而使用“w/o R”表示该方法不使用Pinheiro等人的增强策略[50]。
根据表7的结果,可以提出若干意见。
(1) 表7中的第一组行表明,通过简单地更新fθ的体系结构,可以实现重要的性能改进。然而,这是以速度为代价的,特别是对于SiamRPN。
(2) SiamMask-2B和SiamMask在其基线(fθ相同)SiamFC和SiamRPN上有显著改善。
(3) 有趣的是,Pinheiro等人[50]的竞争方法对于轮廓精度FM非常重要,但对于其他度量则不那么重要。
多任务训练
为了理清多任务训练的效果,本文又进行了两个实验。结果见表7和表3。为了实现这一点,本文在推理过程中修改了SiamMask的两个变体,以便它们分别从score分支(SiamMask-2B-score)或box分支(SiamMask box)报告轴对齐的边界框。因此,尽管经过训练,但在引用期间不使用掩码分支。
本文可以观察到这两种变体相对于它们的无掩模分支对应物(SiamFC和SiamRPN)如何获得改进:在VOT2018上,两个分支的EAO从0.251到0.265,三个分支的EAO从0.359到0.363。因此,这些差距完全是由于多任务培训的好处。
时机
SiamMask在没有对测试序列进行任何调整的情况下在线运行。在单个NVIDIA Titan X GPU上,本文分别测量了两个分支和三个分支变体的平均每秒55帧和60帧的速度。注意,最大的计算负担来自于特征提取器fθ。
失败案例
最后,本文讨论了两个SiamMask失败的场景:运动模糊和“非对象”模式(图5)。尽管性质不同,但这两种情况可以说是由于在诸如YouTube VOS[64]这样的训练集中完全缺乏类似的训练样本,该训练集中在可以从前景中明确分割的对象上。

4. Conclusion
本文介绍了SiamMask,这是一种简单的方法,使完全卷积的siamesk跟踪器能够生成目标对象的类不可知的二进制分割掩码。本文展示了它如何成功地应用于视觉目标跟踪和半监督视频目标分割两个任务,显示出比最先进的跟踪器更好的精度,同时,在VOS方法中速度最快。本文提出的SiamMask的两个变体是用一个简单的边界框初始化的,在线操作,实时运行,不需要对测试序列进行任何调整。本文希望本文的工作能启发进一步的研究,将视觉目标跟踪和视频目标分割这两个问题结合起来考虑。
标签:analysis 非共享 问题 lan nta 适用于 图片 可变 摘要
原文地址:https://www.cnblogs.com/wujianming-110117/p/12733024.html