标签:导致 缓存 art 版权 系统 net 介绍 并行 问题
布隆过滤器(BloomFilter)是一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 某样东西一定不存在或者可能存在,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间,但是布隆过滤器也存在一定的缺陷:数据只能插入不能删除。
布隆过滤器的底层实现是位图。
2.1 布隆过滤器的插入
布隆过滤器是由一个很长的bit数组和一系列哈希函数组成的。结构如下:

数组的每个元素都只占1bit空间,并且每个元素只能为0或1。
布隆过滤器还拥有k个哈希函数,当一个元素加入布隆过滤器时,会使用k个哈希函数对其进行k次计算,得到k个哈希值,并且根据得到的哈希值,在数组中把对应下标的值置位1。
例:“baidu"这个值对应的三个不同的哈希函数返回三个哈希值分别为:1 、4 、7,则将其对应的下标置1,其结构就会变成下面这样:
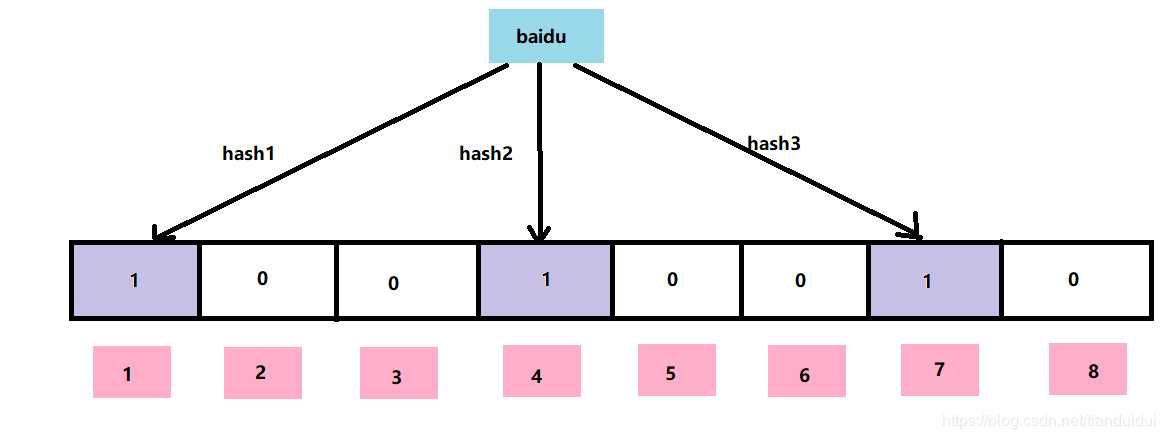
2.2 布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1.
所以在查询某个是否存在时,若该值利用三个不同的哈希函数返回的哈希值对应的下标至少有一个为0,则说明该值一定不存在,若对应的值均为1,说明该值可能存在。
为什么说是可能存在而不是一定存在呢?
因为可能会出现不同的值利用哈希函数返回的哈希值对应的下标相同,所以说只能得出可能存在的结果,即某些哈希函数存在一定误判。
2.3 布隆过滤器产生误判的原因
当插入的元素越来越多时,当一个不在布隆过滤器中的元素,经过同样规则的哈希计算之后,得到的值在数组中查询,有可能这些位置因为其他的元素先被置1了。
所以布隆过滤器存在误判的情况,但是如果布隆过滤器判断某个元素不在布隆过滤器中,那么这个值就一定不在。
在介绍布隆过滤器的概念时提到布隆过滤器的缺点是不支持删除,但是它不支持删除的原因是什么呢?
因为删除一个元素时可能会影响到其他元素。
举个例子:“baidu"利用三个不同的哈希函数返回的哈希值为1,4,7,“tencent"利用三个不同的哈希函数返回的哈希值为3,4,8,假设删除“baidu"这个元素,则1,4,7对应的下标置0,但是“tencent"这个元素与“baidu”对应的下标4重合,这样就会将“tencent”这个元素也删除,所以布隆过滤器不支持删除。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
但是这中删除方法也存在一定缺陷:
无法确认元素是否真正在布隆过滤器中
存在计数回绕
增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
哈希函数相互之间没有关系,方便硬件并行运算
布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
使用同一组散列函数的布隆过滤器可以进行交、并、差运算
有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
不能获取元素本身
一般情况下不能从布隆过滤器中删除元素
如果采用计数方式删除,可能会存在计数回绕问题
网页爬虫对URL的去重,避免爬去相同的URL地址。
垃圾邮件过滤,从数十亿个垃圾邮件列表中判断某邮箱是否是杀垃圾邮箱。
解决数据库缓存击穿,黑客攻击服务器时,会构建大量不存在于缓存中的key向服务器发起请求,在数据量足够大的时候,频繁的数据库查询会导致挂机。
秒杀系统,查看用户是否重复购买。
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法?
思路:精确算法利用位图来实现
近似算法利用布隆过滤器实现,将一个文件的中100亿个query放在一个布隆过滤器中,另个一个文件中的数据到布隆过滤器中去查找,若查找到则说明是这两个文件的交集。
————————————————
版权声明:本文为CSDN博主「田怼怼」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/tianduidui/article/details/104772178/
标签:导致 缓存 art 版权 系统 net 介绍 并行 问题
原文地址:https://www.cnblogs.com/cjjjj/p/12735267.html