标签:读取 分布式锁 长度 https 就会 dynamic 分布 简介 速度
简单来说, Redis就是一个数据库, 只不过是非关系型数据库, 而且数据是存储在内存中的.因此Redis的速度也很快, 被广泛用于缓存方面. 同时也常被用来做分布式锁. Redis支持多种数据类型, 可以支持不同的场景应用.
主要从高并发和高性能两点来看
高性能:
当用户第一次访问数据库中的数据时, 这个过程会比较慢, 因为从硬盘读取的(比如当我们访问淘宝时,可以测试一下, 第一次加载很慢, 后续就会很快), 如果我们将用户访问的数据放到缓存中, 下一次请求这些数据直接在内存中获取, 操作缓存就是操作内存, 所以速度很快.
高并发:
直接操作缓存能够承受的请求远远大于直接访问数据库, 所以我们考虑吧数据库中部分数据转移到缓存中去, 这样用户的一部分请求就会直接到缓存里请求, 降低数据库压力.
五种基本数据结构:String(字符串)、list(列表)、set(集合)、zset(有序集合)
Redis中的字符串是一种动态字符串,这意味着可以修改,底层实现类似于ArrayList,有一个字符数组,在源码的sds.h/sdshdr文件种可以看到Redis底层对于字符串的定义是SDS,simple dynamic String结构
同样一组结构Redis使用泛型定义了好多次,不直接使用int类型,当字符串比较短的时候,len和alloc可以使用byte和short来表示,Redis为了对内存做极致的优化,不同长度字符串使用不同的结构体来表示。
SET(设置) GET(获取) EXISTS(是否存在) DEL(删除) MGET(批量获取) MSET(批量设置) SETEX(设置过期时间) SETNX(不存在set成功,存在set失败)
List类似于Java中的LinkedList,双向链表,删除、插入操作很快,遍历比较慢
LPUSH、LPOP、RPUSH、RPOP 左右添加删除
LRANGE 去除一定范围内的元素
LINDEX 取出指定下标的元素
正是得益于List是双向链表,所以List可以实现队列(先进先出,RPUSH、LPOP),栈(后进先出,RPUSH、RPOP)
相当于Java中的Hash Map,内部实现类似,通过数组+链表的方法解决哈希冲突
实际上字典的结构的内部包含两个Hash table,通常在扩容缩容时,需要分配新的Hash table。
渐进式rehash:
大字典的扩容比较麻烦,需要申请空间,将旧字典移到新字典,所以Redis使用渐进式rehash小步搬迁,
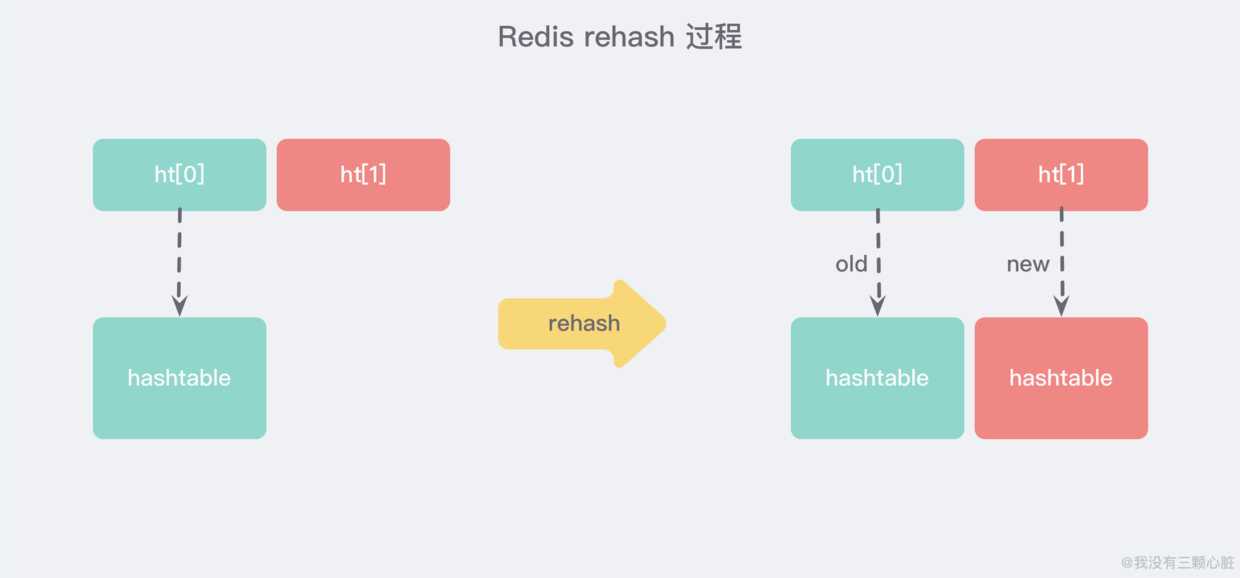
渐进式rehash在rehash的同时,保留新旧两个hash结构,查询时会同时查询连个hash结构,然后在后续的定时任务和hash操作中,循环渐进的把旧字典搬移到新字典,然后新字典取代旧字典。
扩缩容条件:
正常情况下当Hash表中元素个数等于第一维数组的长度时就开始扩容,扩容的新数组是原来的两倍,不过当Redis正在做BGSAVE(持久化操作),为了减少内存的过多分离,Redis尽量不扩容,但是当hash非常满了,达到第一维数组的5倍,就会强制扩容。
缩容时条件:当元素个数低于数组长度的10%,就会缩容,不会考虑是否在做bgsave。
HSET、HGET、HGETALL、HMSET
Redis中的set相当于Java中的HashSet,内部键值对是无序的、唯一的。它的内部实现相当于一个特殊字典,字典中所有的value都为空。
SADD,SMEMBERS查看所有、SISMEMBER是否存在、SCARD获取长度、SPOP弹出
类似于Java中SortedSet和HashMap的结合体,一方面是一个set,保证了内部value的唯一性,另一方面可以为每个value赋予一个score值,用来代表排序的权重
内部实现使用的是跳表
标签:读取 分布式锁 长度 https 就会 dynamic 分布 简介 速度
原文地址:https://www.cnblogs.com/codingLiu/p/12735411.html