标签:summary 频繁模式 结果 mic rate 展示 sso 提升 csv文件
具体库
代码如下
import pandas as pd from CorrelationAnalysis import apriori from pyecharts.charts import Graph from pyecharts import options as opts # 配置方法库
基本思路
代码如下

# 读取csv文件 data = pd.read_csv(‘order_table.csv‘) # 数据转换 order_ids = pd.unique(data[‘order_id‘]) order_records = [data[data[‘order_id‘] == each_id][‘product_name‘].tolist() for each_id in order_ids]
基本思路
代码如下
# 通过调用自定义的apriori做关联分析 minS = 0.01 # 定义最小支持度阈值 minC = 0.05 # 定义最小置信度阈值 L, supportData = apriori.apriori(order_records, minSupport=minS) # 计算得到满足最小支持度的规则 rules = apriori.generateRules(order_records, L, supportData, minConf=minC) # 计算得到满足最小置信度的规则 # 关联结果报表评估 model_summary = ‘data record: {0} \nassociation rules count: {1}‘ # 展示数据集记录数和满足阈值定义的规则数量 print(model_summary.format(len(order_records), len(rules))) # 用str.format做格式化输出 print(‘-‘*60) # 创建频繁项集和关联规则的数据框 rules_all = pd.DataFrame(rules, columns=[‘item1‘, ‘item2‘, ‘instance‘, ‘support‘, ‘confidence‘, ‘lift‘]) rules_sort = rules_all.sort_values([‘lift‘], ascending=False) # 按照提升度排序,降序 pd.set_option(‘display.max_columns‘, None) # 显示所有的列 print(rules_sort.head(10))
执行结果
data record: 2240 association rules count: 582 ------------------------------------------------------------ item1 item2 347 (berries) (whipped/sour cream) 346 (whipped/sour cream) (berries) 496 (pip fruit) (tropical fruit, other vegetables) 495 (tropical fruit) (pip fruit, other vegetables) 514 (yogurt) (fruit/vegetable juice, other vegetables) 579 (curd) (yogurt, whole milk) 550 (root vegetables) (yogurt, tropical fruit) 549 (yogurt) (root vegetables, tropical fruit) 515 (fruit/vegetable juice) (yogurt, other vegetables) 548 (tropical fruit) (root vegetables, yogurt) instance support confidence lift 347 27 0.0121 0.3253 4.1168 346 27 0.0121 0.1525 4.1168 496 23 0.0103 0.1474 4.0772 495 23 0.0103 0.1000 3.9298 514 26 0.0116 0.0836 3.6719 579 29 0.0129 0.2042 3.6307 550 24 0.0107 0.0980 3.5972 549 24 0.0107 0.0772 3.5278 515 26 0.0116 0.1566 3.3735 548 24 0.0107 0.1043 3.2464
基本思路
代码如下
# 结果展示 # 选择有效数据 rules_sort_filt = rules_sort[rules_sort[‘lift‘] > 1] # 只选取有效规则 display_data = rules_sort_filt.iloc[:, :3] # 取出前项,后项和实例数 # 统计item出现的次数 item1 = display_data[[‘item1‘, ‘instance‘]].rename(index=str, columns={‘item1‘: ‘item‘}) item2 = display_data[[‘item2‘, ‘instance‘]].rename(index=str, columns={‘item2‘: ‘item‘}) item_concat = pd.concat((item1, item2), axis=0) item_count = item_concat.groupby([‘item‘])[‘instance‘].sum() # 取出规则最多的TOP N items control_num = 10 top_n_rules = item_count.sort_values(ascending=False).iloc[:control_num] top_n_items = top_n_rules.index top_rules_list = [all((item1 in top_n_items, item2 in top_n_items)) for item1, item2 in zip(display_data[‘item1‘], display_data[‘item2‘])] top_display_data = display_data[top_rules_list] # 画图 node_data = top_n_rules/100 # 等比例缩小100倍 nodes = [{"name": (‘‘).join(i[0]), "symbolSize": i[1], "value": j} for i, j in zip(node_data.to_dict().items(), item_count)] # 创建边数据以及边权重数据 edges = [{"source": (‘‘).join(i), "target": (‘‘).join(j), "value": k} for i, j, k in top_display_data.values] # 创建关系图 graph = Graph(init_opts=opts.InitOpts(width="750px", height="750px")) graph.add(‘‘, nodes, edges, repulsion=8000, layout=‘circular‘, is_rotate_label=True) graph.set_global_opts(title_opts=opts.TitleOpts(title="商品关联结果图")) print(graph.render()) # 服务器端渲染画图
关系图
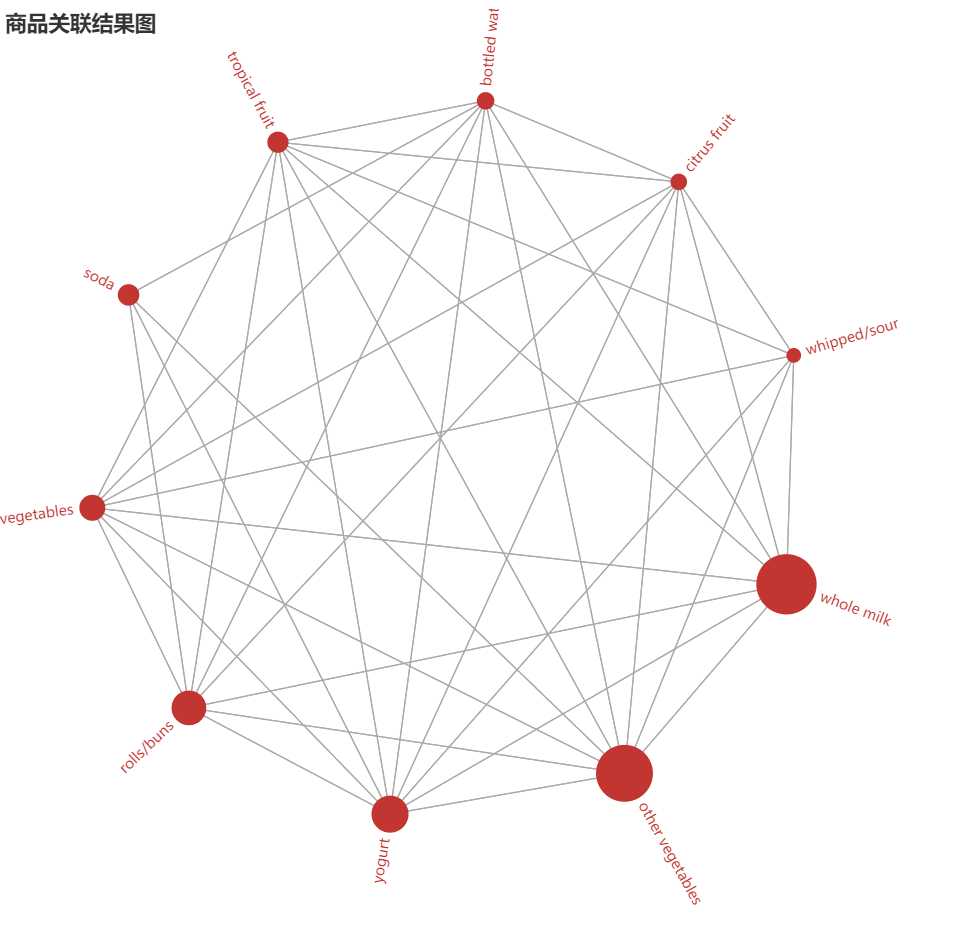
结果分析
参考资料
《Python数据分析与数据化运营》
标签:summary 频繁模式 结果 mic rate 展示 sso 提升 csv文件
原文地址:https://www.cnblogs.com/yanmai/p/12731927.html
