标签:proc capture 过滤 exec exit RKE 官方文档 ase 也有
回顾一下OpenResty的架构图
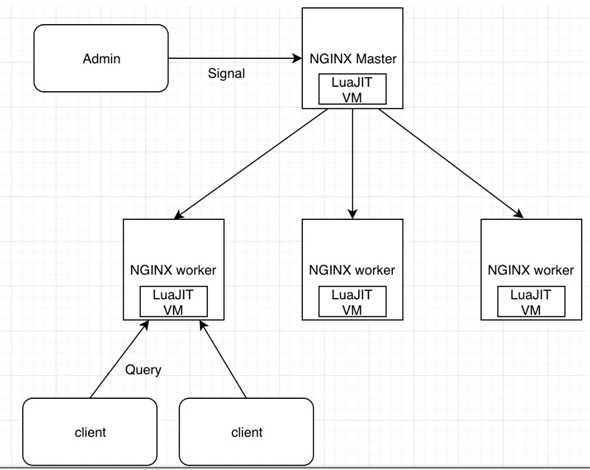
OpenResty 的 master 和 worker 进程中,都包含一个 LuaJIT VM。在同一个进程内的所有协程,都会共享这个 VM,并在这个 VM 中运行 Lua 代码。
在同一个时间点上,每个 worker 进程只能处理一个用户的请求,也就是只有一个协程在运行。
NGINX 实际上是通过 epoll 的事件驱动,来减少等待和空转,才尽可能地让 CPU 资源都用于处 理用户的请求。毕竟,只有单个的请求被足够快地处理完,整体才能达到高性能的目的。如果采用的是多线程模式,让一个请求对应一个线程,那么在 C10K 的情况下,资源很容易就会被耗尽的。
在 OpenResty 层面,Lua 的协程会与 NGINX 的事件机制相互配合。如果 Lua 代码中出现类似查询 MySQL数据库这样的 I/O 操作,就会先调用 Lua 协程的 yield 把自己挂起,然后在 NGINX 中注册回调;在 I/O 操 作完成(也可能是超时或者出错)后,再由 NGINX 回调 resume 来唤醒 Lua 协程。这样就完成了 Lua 协程 和 NGINX 事件驱动的配合,避免在 Lua 代码中写回调。
下面这张图,描述了这整个流程。其中,lua_yield 和 lua_resume 都属于 Lua 提供的 lua_CFunction。
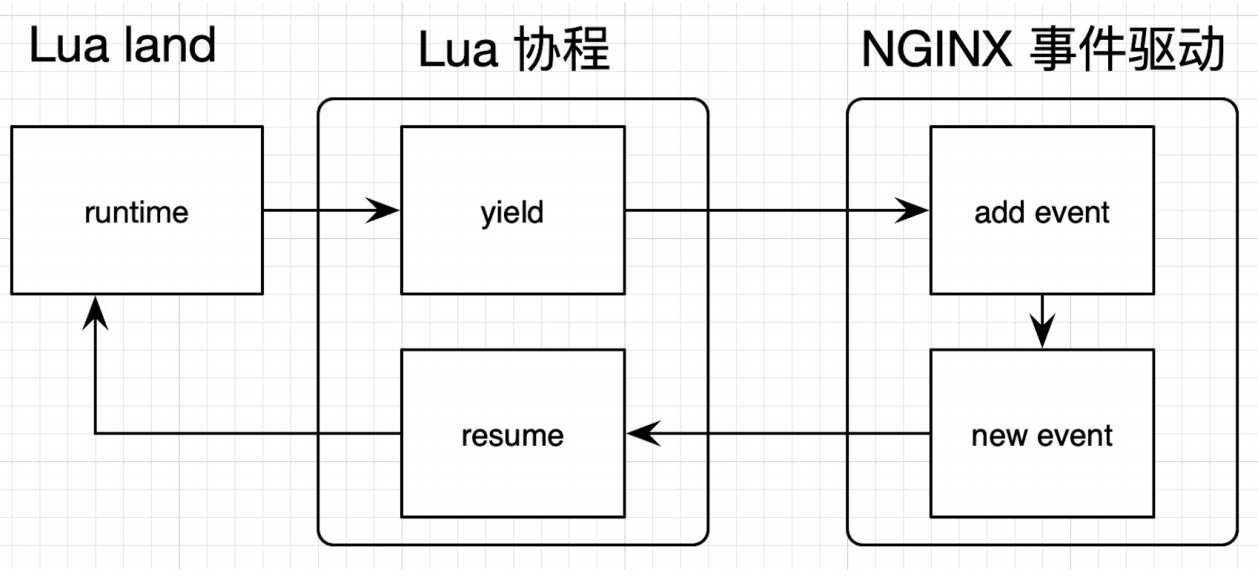
如果 Lua 代码中没有 I/O 或者 sleep 操作,比如全是密集的加解密运算,那么 Lua 协程就 会一直占用 LuaJIT VM,直到处理完整个请求。
以ngx.sleep 作为示例,代码位于 ngx_http_lua_sleep.c 中,可以在 lua-nginx-module 项目的 src 目录中找到。
void
ngx_http_lua_inject_sleep_api(lua_State *L)
{
lua_pushcfunction(L, ngx_http_lua_ngx_sleep);
lua_setfield(L, -2, "sleep");
}
下面便是 sleep 的主函数,这里只摘取了几行主要的代码:
static int ngx_http_lua_ngx_sleep(lua_State *L)
{
coctx->sleep.handler = ngx_http_lua_sleep_handler;
ngx_add_timer(&coctx->sleep, (ngx_msec_t) delay);
return lua_yield(L, 0);
}
当 sleep 操作完成后, ngx_http_lua_sleep_handler 这个回调函数就被触发了。它里面调用了 ngx_http_lua_sleep_resume, 并最终使用 lua_resume 唤醒了 Lua 协程。
OpenResty 和 NGINX 一样,都有阶段的概念,并且每个阶段都有自己不同的作用:
如果代码逻辑并不复杂,都放在 rewrite 或者 content 阶段执行,也是可以的。
不过需要注意,OpenResty 的 API 是有阶段使用限制的。每一个 API 都有一个与之对应的使用阶段列表, 如果超范围使用就会报错。这与其他的开发语言有很大的不同。
以 ngx.sleep 为例,它只能用于下面列出的上下文中,并不包括 log 阶段,如果在它不支持的 log 阶段使用 sleep 的话,在 NGINX 的错误日志中,就会出现 error 级别的提示:
location / {
log_by_lua_block {
ngx.sleep(1)
}
}
由 OpenResty 提供的所有 API,都是非阻塞的。以 sleep 1 秒这个需求为例来说明,如果要在 Lua 中实现它,需要这样做:
function sleep(s)
local ntime = os.time() + s
repeat until os.time() > ntime
end
因为标准 Lua 没有直接的 sleep 函数,所以这里我用一个循环,来不停地判断是否达到指定的时间。这个实现就是阻塞的,在 sleep 的这一秒钟时间内,Lua 正在做无用功,而其他需要处理的请求,只能在一边等待。
不过,要是换成 ngx.sleep(1) 来实现的话,根据上面分析过的源码,在这一秒钟的时间内, OpenResty 依然可以去处理其他请求(比如 B 请求),当前请求(我们叫它 A 请求)的上下文会被保存起 来,并由 NGINX 的事件机制来唤醒,再回到 A 请求,这样 CPU 就一直处于真正的工作状态。
在 OpenResty 中,推荐把所有变量都声明为局部变量,并用 luacheck 和 lua-releng 这样的工具来检测全局变量。这其实对于模块来说也是一样的,比如下面这样的写法:
local ngx_re = require "ngx.re"
在 OpenResty 中,除了 init_by_lua 和 init_worker_by_lua 这两个阶段外,其余阶段都会设置一个隔离的全局变量表,以免在处理过程中污染了其他请求。
试图用全局变量来解决的问题,其实更应该用模块的变量来解决,而且还会更加清晰。下面是一个模块中变量的示例:
local _M = {}
_M.color = {
red = 1,
blue = 2,
green = 3
}
return _M
在一个名为 hello.lua 的文件中定义了一个模块,模块包含了 color 这个 table。然后,又在 nginx.conf 中增加了对应的配置:
location / {
content_by_lua_block {
local hello = require "hello"
ngx.say(hello.color.green)
}
}
这段配置会在 content 阶段中 require 这个模块,并把 green 的值作为 http 请求返回体打印出来。
在同一 worker 进程中,模块只会被加载一次;之后这个 worker 处理的所有请求,就可以共享模块中的数据了。“全局”的数据很适合封装在模块内,是因为 OpenResty 的 worker 之间完全隔离, 所以每个 worker 都会独立地对模块进行加载,而模块的数据也不能跨越 worker。
这里也有一个很容易出错的地方,那就是访问模块变量的时候,你最好保持只读,而不要尝试去修改,不然在高并发的情况下会出现 race。这种 bug 依靠单元测试是无法发现的,它在线上偶尔会出现,并且很难定位。
举个例子,模块变量 green 当前的值是 3,而你在代码中做了加 1 的操作,那么现在 green 的值是 4 吗? 不一定,它可能是 4,也可能是 5 或者是 6。因为在对模块变量进行写操作的时候,OpenResty 并不会加 锁,这时就会产生竞争,模块变量的值就会被多个请求同时更新。
有些情况下,我们需要的是跨越阶段的、可以读写的变量。而像我们熟悉的 NGINX 中 $host、$scheme 等变量,虽然满足跨越阶段的条件,但却无法做到动态创建,你必须先在配置文件中定义才能使用它们。比 如下面这样的写法:
location /foo {
set $my_var ; # 需要先创建 $my_var 变量
content_by_lua_block {
ngx.var.my_var = 123
}
}
OpenResty 提供了 ngx.ctx,来解决这类问题。它是一个 Lua table,可以用来存储基于请求的 Lua 数 据,且生存周期与当前请求相同。官方文档中的这个示例:
location /test {
rewrite_by_lua_block {
ngx.ctx.foo = 76
}
access_by_lua_block {
ngx.ctx.foo = ngx.ctx.foo + 3
}
content_by_lua_block {
ngx.say(ngx.ctx.foo)
}
}
ngx.ctx 也有自己的局限性:
虽然 OpenResty 是基于 NGINX 的 Web 服务器,但它与 NGINX 却有本质的不同:NGINX 由静态的配置文 件驱动,而 OpenResty 是由 Lua API 驱动的,所以能提供更多的灵活性和可编程性。
OpenResty 的 API 主要分为下面几个大类:
处理请求和响应;
SSL 相关;
shared dict;
cosocket;
处理四层流量;
process 和 worker;
获取 NGINX 变量和配置;
字符串、时间、编解码等通用功能。
OpenResty 的 API 不仅仅存在于 nginx-lua-module 项目中,也存在于 lua-resty-core 项目中,比如 ngx.ssl、ngx.base64、ngx.errlog、ngx.process、ngx.re.split、ngx.resp.add_header、ngx.balancer、 ngx.semaphore、ngx.ocsp 这些 API 。
对于不在 nginx-lua-module 项目中的 API,你】需要单独 require 才能使用。举个例子,如果想使用 split 这个字符串分割函数,就需要按照下面的方法来调用:
$ resty -e ‘local ngx_re = require "ngx.re"
> local res, err = ngx_re.split("a,b,c,d", ",", nil, {pos = 5})
> print(res)
> ‘
cd
这可能会给你带来一个困惑:在 nginx-lua-module 项目中,明明有 ngx.re.sub、ngx.re.find 等好几 个 ngx.re 开头的 API,为什么单单是 ngx.re.split 这个 API ,需要 require 后才能使用呢?
OpenResty 新的 API 都是通过 FFI 的方式在 luarety-core 仓库中实现的,所以难免就会存在这种割裂感。
HTTP 请求报文由三部分组成:请求行、请求头和请求体,下面就按照这三部分来对 API 做介绍。
HTTP 的请求行中包含请求方法、URI 和 HTTP 协议版本。在 NGINX 中,你可以通过内置变 量的方式,来获取其中的值;而在 OpenResty 中对应的则是 ngx.var.* 这个 API。
既然可以通过ngx.var.* 这种返回变量值的方法,来得到请求行中的数据,为什么 OpenResty 还要单独提供针对请求行的 API 呢?
OpenResty 提供了多个专门操作请求行的 API,它们可以对请求行进行改写,以便后续的重定向等 操作。
OpenResty 的 API ngx.req.http_version 和 NGINX 的 $server_protocol 变量的作用一样,都是返回 HTTP 协议的版本号。不过这个 API 的返回值是数字格式,而非字符串,可能的值是 2.0、1.0、1.1 和 0.9,如果结果不在这几个值的范围内,就会返回 nil。
ngx.req.get_method 和 NGINX 的 $request_method 变量的作用、返回值一样,都是字符串格式的方法名。改写当前 HTTP 请求方法的 API,也就是 ngx.req.set_method,它接受的参数格式却并非字符串,而是内置的数字常量。比如,下面的代码,把请求方法改写为 POST:
ngx.req.set_method(ngx.HTTP_POST)
$ resty -e ‘print(ngx.HTTP_POST)‘
在改写请求行的方法中,还有 ngx.req.set_uri 和 ngx.req.set_uri_args 这两个 API,可以 用来改写 uri 和 args。我们来看下这个 NGINX 配置:
rewrite ^ /foo?a=3? break;
用等价的 Lua API 来解决:
ngx.req.set_uri_args("a=3")
ngx.req.set_uri("/foo")
HTTP 的请求头是 key : value 格式的,比如:
Accept: text/css,*/*;q=0.1 Accept-Encoding: gzip, deflate, br
在OpenResty 中,可以使用 ngx.req.get_headers 来解析和获取请求头,返回值的类型则是 table:
local h, err = ngx.req.get_headers()
if err == "truncated" then
-- one can choose to ignore or reject the current request here
end
for k, v in pairs(h) do
...
end
这里默认返回前 100 个 header,如果请求头超过了 100 个,就会返回 truncated 的错误信息,由开发者 自己决定如何处理。
需要注意的是,OpenResty 并没有提供获取某一个指定请求头的 API,也就是没有 ngx.req.header[‘host‘] 这种形式。如果你有这样的需求,那就需要借助 NGINX 的变量 $http_xxx 来实现了,那么在 OpenResty 中,就是 ngx.var.http_xxx 这样的获取方式。
看看应该如何改写和删除请求头,这两种操作的 API 其实都很直观:
ngx.req.set_header("Content-Type", "text/css")
ngx.req.clear_header("Content-Type")
官方文档中也提到了其他方法来删除请求头,比如把 header 的值设置为 nil等,但为了代码更加清晰 的考虑,还是推荐统一用 clear_header 来操作。
出于性能考虑,OpenResty 不会主动读取请求体的内容,除非你在 nginx.conf 中强制开启了 lua_need_request_body 指令。对于比较大的请求体,OpenResty 会把内容保存在磁盘的 临时文件中,所以读取请求体的完整流程是下面这样的:
ngx.req.read_body()
local data = ngx.req.get_body_data()
if not data then
local tmp_file = ngx.req.get_body_file()
-- io.open(tmp_file)
-- ...
end
这段代码中有读取磁盘文件的 IO 阻塞操作。应该根据实际情况来调整 client_body_buffer_size 配 置的大小(64 位系统下默认是 16 KB),尽量减少阻塞的操作;也可以把 client_body_buffer_size 和 client_max_body_size 配置成一样的,完全在内存中来处理,当然,这取决于内存的大小和处理的并发请求数。
请求体也可以被改写,ngx.req.set_body_data 和 ngx.req.set_body_file 这两个API,分别接受字符串和本地磁盘文件做为输入参数,来完成请求体的改写。不过,这类操作并不常见,
处理完请求后,我们就需要发送响应返回给客户端了。和请求报文一样,响应报文也由几个部分组成,即状 态行、响应头和响应体。
状态行中,我们主要关注的是状态码。在默认情况下,返回的 HTTP 状态码是 200,也就是 OpenResty 中 内置的常量 ngx.HTTP_OK。
如果你检测了请求报文,发现这是一个恶意的请求,那么需要终止请求:
ngx.exit(ngx.HTTP_BAD_REQUEST)
OpenResty 的 HTTP 状态码中,有一个特别的常量:ngx.OK。当 ngx.exit(ngx.OK) 时,请求会退出当前处理阶段,进入下一个阶段,而不是直接返回给客户端。
当然,也可以选择不退出,只使用 ngx.status 来改写状态码,比如下面这样的写法:
ngx.status = ngx.HTTP_FORBIDDEN
你有两种方法来设置它。第一种是最简单的:
ngx.header.content_type = ‘text/plain‘ ngx.header["X-My-Header"] = ‘blah blah‘ ngx.header["X-My-Header"] = nil -- 删除
第二种设置响应头的方法是 ngx_resp.add_header ,来自 lua-resty-core 仓库,它可以增加一个头信 息,用下面的方法来调用:
local ngx_resp = require "ngx.resp"
ngx_resp.add_header("Foo", "bar")
与第一种方法的不同之处在于,add header 不会覆盖已经存在的同名字段。
在 OpenResty 中,可以使用 ngx.say 和 ngx.print 来输出响应体:
ngx.say(‘hello, world‘)
这两个 API 的功能是一致的,唯一的不同在于, ngx.say 会在最后多一个换行符。
为了避免字符串拼接的低效,ngx.say / ngx.print 不仅支持字符串作为参数,也支持数组格式:
$ resty -e ‘ngx.say({"hello", ", ", "world"})‘
hello, world
这样在 Lua 层面就跳过了字符串的拼接,把这个它不擅长的事情丢给了 C 函数去处理。
标签:proc capture 过滤 exec exit RKE 官方文档 ase 也有
原文地址:https://www.cnblogs.com/liekkas01/p/12741365.html