标签:rod 聚合 不可 应该 形式 图表 unknown ssd box
作者:蒋天园
Date:2020-04-21
前言
本文是一篇来自Carnegie Mellon大学和Argo AI的合作工作,目前已经被CVPR20接收(oral),该文的主要内容是基于点云的3D目标检测,与以往的研究内容不同的是,本文基于观察发现在BEV视图中无法区分free和unknown区域,如下图中(a)展示的两个红色框所示,在BEV看上去都是不包含点的free space。但是假如通过lidar的扫描的激光对该图重新绘制如图(b),其中绿色表明为激光扫描到的区域,白色为未知的区域,即白色是被前景物体所遮挡的区域,而绿色是真正被扫描到的,因此,我们可以得到的信息是左边的红框区域表示的是未知,而右边实际上是真正的freespace。因此本文的作者正是利用freespace的信息来提高检测精度。
文章地址:https://arxiv.org/pdf/1912.04986.pdf
主要内容概述
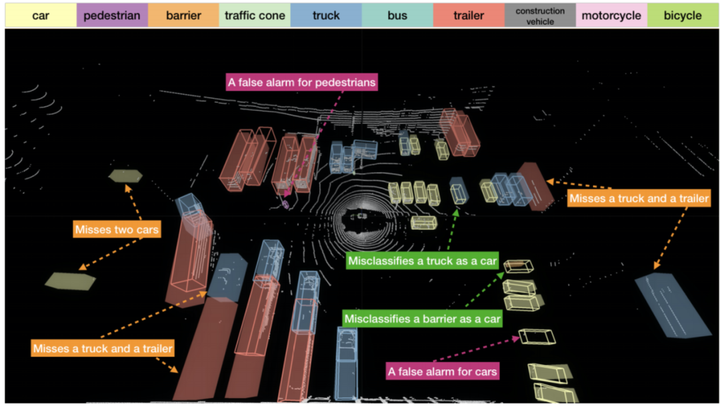
笔者认为,本文主要上面所述的这样一个观察,认为free-space 和unknown的信息是可以可用特征信息加入到深度学习网络中去的,因为目前的深度学习网络在BEV条件下并无法区分unkown和free-space信息,作者据此观察构建了visiblitymap,并采用pointpillars 为baseline,采用了多种融合策略及数据增广方式,最终实验表面在Nuscenes上的效果提升不少。证实了这种观察的有效性。如下是可视化的实验效果。
1. Abstract
1.目前3D检测的研究很大一部分是在找到一个合适的3D传感器数据的表示形式。目前主流的表示形式有两类,分别是原始的Point表示和voxel表示,其中基于point的表示形式能够不丢失几何结构信息,保留到了最原始的信息,但是基于Point的方法受到SA和FP模块timecost很大的问题,但是今年的CVPR20的3DSSD采取了省略FP层,同时改进SA模块设计的3D检测方法,可以和目前两阶段的方法媲美精度,同时能做到25FPS。基于voxel的方法在稀疏卷积的引入后得到了很大的发展,正如CVPR2020中PV-RCNN中的表述的该类方法又高效精度也高,但是直观感受是,在预处理中时体素化时,肯定会有信息丢失,尤其是细节信息,就这个问题,同样是今年的CVPR20的SA-SSD,则是将voxel-feature表征到最原始的点云结构中,使得最初的细节几何信息和xoel的原始信息融合,提高voxelbackbone对几何结构信息的感知能力。此外,今年也有GNN检测的网络,因此点云的表示为graph,在预处理时需要对该点云结构建图,但是不可避免该类方法timecost很大。因此本文作者也应该探究这样一种表示的方式,该方式应该可以很好的结合本文观察到的free-space信息,最终采用了voxel的表达形式。
2.作者指出之前的很多点云的representanions实际上针对真正的3Ddata而提出的,而在自动驾驶场景中的点云实际上是实时扫描的lidarsweep,只能算作2.5D。作者提出的这一个观点,确实是有这样的一个问题,最开始的Point系列都是在modelnet40这个数据集进行实验,都是完整的3D数据,而对于实时的Lidarsweep实际上仅仅只有表面点,并且对于遮挡部分都是需要重建的,对于重建后的完整的点云地图才能算作是3D信息。
3.因为lidar sweep是2.5D信息,如果只采用(x,y,z)表示则会丢失freespae这一隐藏信息。因此本文则是通过3D光线投射恢复这些信息:作者在输入时加入了voxelized visibility map作为该freespace的信息补充。作者也在本文中实验了该freespace结合两种数据增广方法的效果:虚拟对象的数据扩充(SECOND)和Multi-time frames的融合。
4.在nuscenes上添加了本文的visibility input,可以明显提高当前sota方法的检测精度。
2. Introduction
正如在引言中介绍到的内容,本文针对实时的lidar sweep数据的遮挡特性,表明这种2.5D的数据实际上只能采集到最表面的点,对该点之后的点实际上是存在遮挡问题的;文中表述为“once a particular sceneelement is measured at a particular depth, visibility ensures that all otherscene elements behind it along its line-of-sight are occluded”。这也是对于3Dsensor得到的数据可以采用二维结构表达的原因,实际上表示为2.5D数据更为准确。
文中指出,在很多任务中,如map-building和自动驾驶导航任务中,visibility是很重要的内容;但是在目标检测中还没有文章挖掘这一信息作为指导信息,以此来提高检测的精度。所在本文作者表示可以简单的修改深度学习架构和加入数据增广策略来实现在3D检测中对free space信息的探索。因此本文作者在目前的sota的voxel-based的方法中加入了visiblity 信息
(1)occupancy map:在移动机器人建图中常用的表达形式
(2)Octomap:通用的3D 构图中的Visibility表示形式
(1)one-stage和two-stage的方法,后续会出一篇综述性文章来介绍目前比较新的几种方法的对比
作者在本文中,专门提到了在SECOND中的数据增广方法(把所用场景中的gt先整合在一起成为一个database,然后对训练的场景随机插入若干个database的gt),目前几乎所有的sota的方法都有采用这种数据增广方法,,也是因为该种增广方法非常有效,但是本文作者指出,这种数据增广方式违反了真实场景中的遮挡关系,在本文中,作者对这部分数据增广内容作了修改,以适应真实场景中的遮挡关系。
(3)多帧sweep融合第一个利用了帧之间连续的信息,并采用RNN设计的3D目标检测的网络发表在CVPR18的[1],后续有SECOND单地聚合不同帧的信息,同时保留它们相对于当前帧的时间戳。同样在今年的CVPR20上,3D-VID这一篇百度研究院的工作通过空间特征提取和时空融合模块可以减少FP的检测结果,在笔者之前的博文中是有介绍到这一篇文章。值得一提的是,这两篇文章都是在pointpillars的基础上cite的。
1.作者最先引入了“raycasting algorithms”(光线投射)方法,用于对voxel-grid高效的计算 visibility性。并证实该加入的信息可以被加入到batch-based的梯度学习中去
2.在voxel-based的方法上增加了一个简单的数据增方式:作者把voxelized 的visibility map作为额外输入信息。
3.证实了visibility map可以被当前两种数据增广方法的结合所代替:即是虚拟object的数据扩充和lidar sweep之间的融合。
3. Visibility for 3D Object Detection
在介绍结构前之前,作者列举了很多的目前的方法,指出这些方法有两个主要的创新,其中一是采用了Object插入到训练场景中的数据增广方法,二是融合了多帧的特征。作者也将在这两种方法上和自己的方法做对比研究。其实按照笔者的理解,多帧融合实际上可以达到3D重建的效果,也就有了作者本文提到的free space和unknown space可区分的效果。就本文的创新而言为:
1.作者首先引入了一种高效计算visibility的方法,称作raycasting algorithm
2.将上得到的visibility和当前的深度学习网络结构融合
overview 网络结构
如下,这里的网络结构和设计和之前voxel-based的方法是一样的,具体的流程可以表示为两部分,即predefined 3D anchors和网络结构
1.左图表示的是voxel-based方法常用的anchor-based的方法,即是对每一类的object,在BEV平面上按照一定的距离设定anchor box,其中有多少类别,anchor的数量就成线性增长,所以在19年的文章OHS和今年CVPR20的3D -SSD都采用了anchor-free的方法来减少显存消耗。
2.右图则是标准的目前的voxel-based的方法,首先从 point sweep中采用3D稀疏卷积使得高度降为1,再采用2D卷积对3D anchor box进行回归和分类。
数据增广和多帧融合
前文说到,本文的数据增广方式主要研究对SECOND提出的“从gt base中抽取object插入到训练场景进行数据增广”,在后续的消融实验中会展示改进的效果,实验显示提高了9.1%。同样对于多帧融合,本文中同样采用了多帧融合配准,使得输入信息多一个维度表示为(x,y,z,t),实验显示最终的结果可以提高+8.6%。
前文中提到,本文通过增加了一个Visibility map信息使得检测精度得到提升,这里着重介绍如何计算该Visibility:
1.我们都知道,激光雷达朝某一个方向发射激光后,遇到物体表面反射被接收,通过激光飞行时间TOF可以计算出返回点,也就是物体表面点的位置信息。
2.作者的Visibility的方法实际上就是很直观的方法:根据point和lidar的位置,我们可以连接该两点在空间中形成一条线,该线穿过的voxel都被标记为free-space,点存在的voxel被标记为occupied,其余的则是unknown(default).在实现中,则是从最开始的voxel出发,计算从哪个面穿出该voxel,则下一个被考察的voxel就是和这个voxle共享这个接触面的voxel,直至到达最后的点结束。可以表示为下面的伪代码过程:
计算单帧点云的Visibility
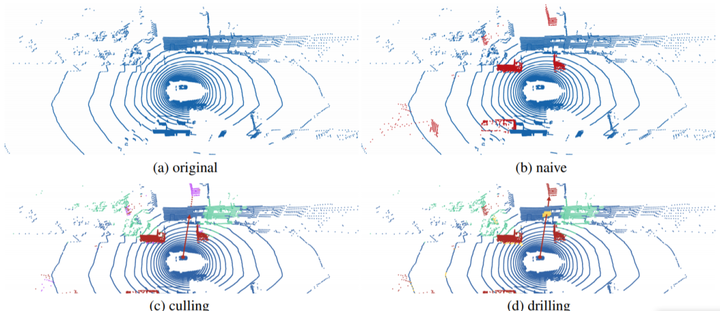
和上述的算法思路一致,只需要把最后的终止条件由到达end更改为遇到BLOCKED即为终止,也就是说,被增广进来的点云数据实际上是被当做BLOCKED处理。如下图所示的内容,这里的(a)表示的是原始场景,(b)是插入增广后的物体但是不加任何处理的,可以明显的看到,在墙的后面是存在一个被遮挡的object的,这是不符合常理的。因此在(c)中采用了符合常理的做法,即是把被遮挡的object删除,但是这样可能带来的问题是插入的object可能都被删除,因此正确的做法是删除前面遮挡的墙体,如图(d),这就是是上文中所说的遇到BLOCKED才结束。
计算多帧的Visibility
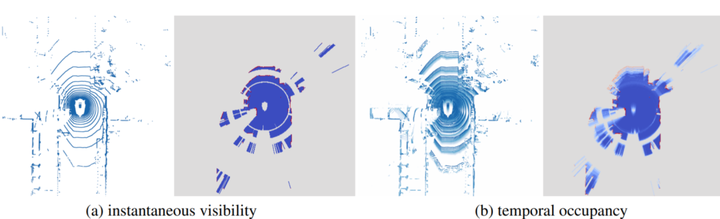
上文的计算voxel 的Visibility仅仅计算了单帧的Visibility,对于连续的sweep,一个简单的想法就是,既然我们知道初始传感器的位置,我们就可以对所用帧都当做单帧处理,但是这类方法会造成比较大的time cost,作者采用了贝叶斯滤波对连续帧的visibility map就行预测。如下图所示,左图分别表示了单帧sweep的俯视图和对应的visiblitymap,其中红色表示标记为occupy,蓝色为freespace,灰色为unknown;图(b)则表示了采用贝叶斯滤波预测的多帧的点云俯视图和对应的visiblity,这里对于每一个vxole,越红则表示被占据的可能性就越大。
3.3 将 Visibility map融合进backbone
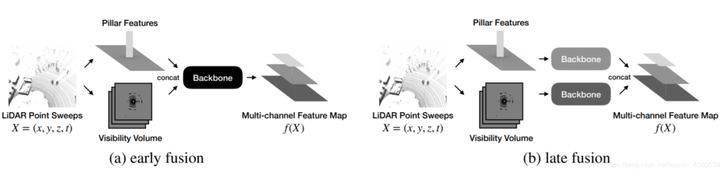
如下图所示,作者选择的融合方式有early fusion和late fusion,实际上也就是在原始信息上融合和语义特征上融合的区别。
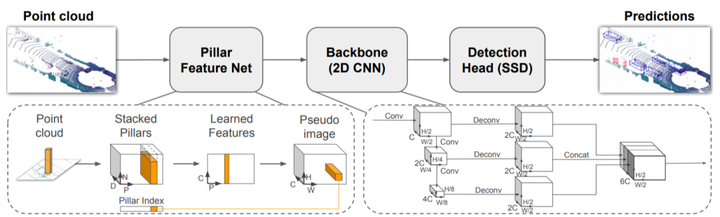
这里介绍一下本文使用的backbone,为19年CVPR的Pointpillars,网络结果如下,该文章是在voxelnet的基础上改进的,将voxelnet 的voxelnet划分为了pillar,因此可以直接省略掉3D CNN的部分,同时做到的精度不下降。
4. Experiments
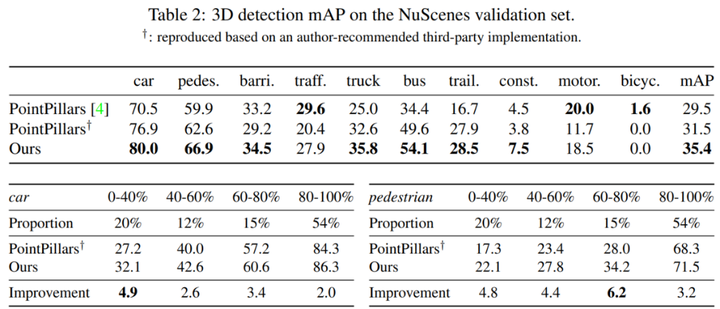
如下图,作者在nuscence benchmark上进行实验,效果如下,可以看出在大部分的情形下相对baseline,都得到了不少的提升。
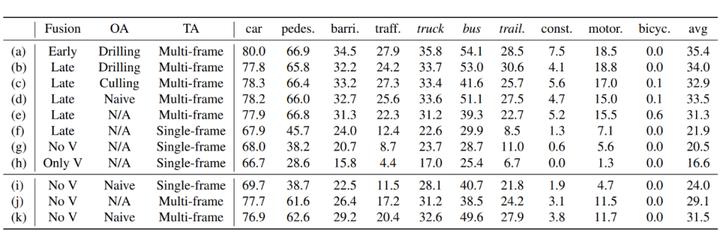
如下图所示,针对fusion的方式、对增广object的处理方式,已经多帧融合等做了如下的消融实验,综合起来“early+drilling+multi-frame”的实验效果是最好的。
5. 笔者的思考
本文是基于观察,发现在目前的SOTA的方法中,并没有利用freespace的信息,从而根据这个观察对baseine网络添加了对应的visilitymap;本文在nuscenes上进行实验,消融实验做的很充分;和之前很多的文章不同的是,这一篇文章的出发点不是对网络结构中的问题的改进,而是对实际中忽略的信息的观察。同样笔者认为这一篇文章和今年其他做3D检测文章对比起来,更加的接近工程和底层,利用了更加基础的信息丢失,但是同样可以思考到,对于pillar本身是丢失了深度信息的,而同样lidar扫描是具有一个角度的,我们是否可以将此信息同样利用起来?此外,笔者认为这样的一个free-spce采用voxel的表示方法,重点在这样可以对free-spce的信息表示出来,而如果采用point-based的方法,则不知到应该怎样将free-space的信息附在Point中。
CVPR2020|物体可见性信息在3D检测中的探索
标签:rod 聚合 不可 应该 形式 图表 unknown ssd box
原文地址:https://www.cnblogs.com/YongQiVisionIMAX/p/12742156.html