标签:产生 ide top 实验 结果 seq 理想 优化 映射
论文地址:https://www.aclweb.org/anthology/P19-1281/
作者:Henry Moss, Andrew Moore, David Leslie, Paul Rayson
机构:Lancaster University
研究的问题:
关注模型选择的问题,也就是在尽可能减少计算资源的前提下评估模型效果,更多地关注于更有希望的模型。
对于一个模型,它的不确定性主要来自于以下两个方面:
1、数据集导致的不确定性,因为需要对数据集随机划分为训练集和测试集。
2、随机seed的选择,也就是初始化、采样等产生的不确定性。
本文提出了FIESTA(fast identification of start-of-the-art),目标是通过少量的模型评估,从候选者模型中识别出最佳模型。
研究方法:
分别根据不同的需求,在固定预算(分配固定的计算资源)的情况下和固定置信度(希望所选出的模型是最好的)的两种场景下分别讨论。
固定预算:一般方法是连续地消除不可靠的模型,直到只剩下最后一个最理想的模型。主要借鉴了sequential halving(SH)算法,使用logN轮来从N个模型中选择,也就是每次丢弃一半模型。计算资源首先在各轮中平均分配,然后在每轮的各个模型中平均分配。示例如下:
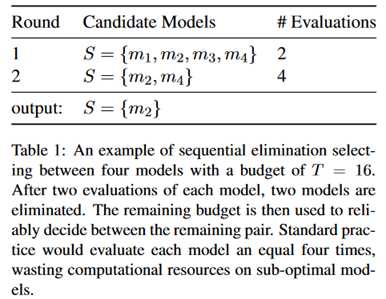
上面的例子中,预算是16次评估,在第一轮中,每个模型评估两次,第二轮中,每个模型被评估四次,多次评估的目的在于减少随机性带来的偏差。
算法的理论前提上每个模型的奖励分布是有界的,但一半的NLP指标,准确率、召回率等都是有界的。
整体算法流程如下:

固定置信度:这种情况下希望选择的是性能最优的模型。方法主要基于贝叶斯采样方法的一个变体,top-two Thompson sampling(TTTS)。
它的前提是每个模型的评价就遵循高斯分布,有着不同的均值和方差。但一般NLP的指标都是有界的,并不遵循。作者这里进行了实验,将指标映射到整个实数范围,但发现这个改变对实验几乎没有帮助。
用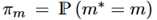 表示模型的最佳性能,模型的选择策略为标准的Thompson sampling,也就是根据当前
表示模型的最佳性能,模型的选择策略为标准的Thompson sampling,也就是根据当前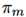 作为它的采样概率来选择模型。
作为它的采样概率来选择模型。
由于假设模型结果服从高斯分布 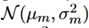 ,问题就是评估
,问题就是评估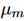 和
和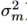 ,同时使用T_m记录每个模型的评估次数。为了便于推断,设定一个统一的
,同时使用T_m记录每个模型的评估次数。为了便于推断,设定一个统一的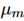 和
和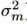 。将估计的均值和方差定义为
。将估计的均值和方差定义为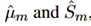 。
。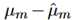 满足:
满足:
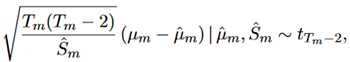
总体流程如下:

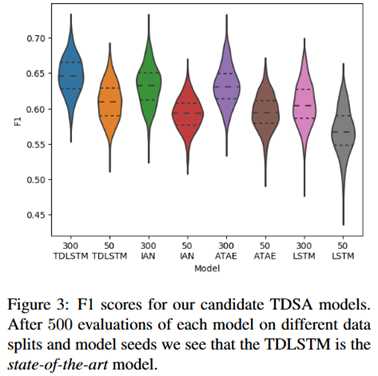
实验部分:实验在目标级的情感分析任务上进行,选择了八个模型作为评估对象。部分实验结果如下:
评价:
将multi-armed bandits用来提高模型选择的可靠性和降低成本的,之前MAB大多用在了优化翻译算法中。但事实上这个方面的需求并不多,模型的用处不大。
论文阅读 | FIESTA: Fast IdEntification of State-of-The-Art models using adaptive bandit algorithms
标签:产生 ide top 实验 结果 seq 理想 优化 映射
原文地址:https://www.cnblogs.com/bernieloveslife/p/12748408.html