标签:href osi 语料库 发布 learn dir rac 机制 surf
论文地址: https://hal.inria.fr/hal-02131630/document
作者 : Ganesh Jawahar, Benoît Sagot, Djamé Seddah
机构 : Inria
研究的问题:
探究BERT的深层次表征学习的论文,也就是通过实验研究BERT的可解释性。主要是探究在BERT的每一层都编码了什么信息。
研究方法:
模型:
研究的模型是基于Devlin等发布的用104种语言组成的语料库上训练的多语言BERT模型。它由12层编码网络组成,每层的隐藏状态(hidden)尺寸为768,并且有12个注意力头(110M参数)。在所有的实验中,作者在每一层网络都使用第一个输入符号(‘[CLS]’)的输出来计算BERT的表征,这个输出通过自注意力机制汇聚了所有真实符号的信息表征。
实验一:短语语法
对于LSTM,已经被Peters等在2018年证明可以捕捉短语级别的结构信息。他们对于Transformer模型也做了研究,但没有得出结论。作者采用了跟Peters相同的研究方法,具体如下:
首先给定一个输入符号序列s_i,…,s_j,然后在每一层,通过结合第一个和最后一个隐藏向量,来计算该层的跨度表示。结果如下:
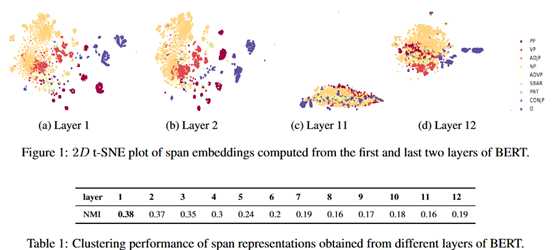
图中是利用t-SNE对跨度表征可视化的结果,可以看到BERT在低层网络捕捉了短语级别的结构信息,然后随着网络层数的加大,短语级别的结构信息逐渐消失。
进一步通过聚类算法k-means量化这个证明。在表中,作者使用归一化互信息(Normalized Mutual Information,NMI)展示了低层网络在编码短语级别的结构信息上优于高层网络。
实验二:探测任务(Probing Task)
探测任务能够帮助挖掘编码在神经网络模型中的语言学信息。作者使用探测任务来评估每层神经网络编码不同类型语言学特征的能力。
实验原理是通过设置一个辅助的分类任务来实现,也就是用一个分类器从BERT中获得输入,如果分类器的结果正确,说明BERT提取到了有用的信息。具体是通过SentEval工具包实现的。
作者使用十个句子级别的探测任务,这些探测任务被分为三组:
1)表层任务:句子长度(SentLen)探测,单词在句子中存在探测(WC);
2)句法层任务:词序敏感性(BShift),句法树深度(TreeDepth),句法树顶级成分序列(TopConst);
3)语义层任务:时态检查(Tense),主语数量(SubjNum),名词动词随机替换敏感度(SOMO),协作分句连词的随机交换(CoordInv)。
实验结果如下:
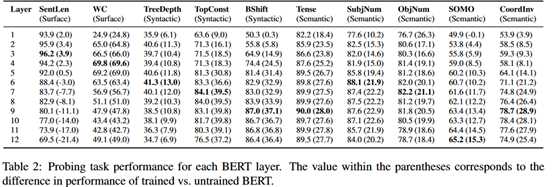
结论:BERT编码了丰富的语言学层次信息。表层信息特征在底层网络,句法信息特征在中间层网络,语义信息特征在高层网络。
实验三:主谓一致
主谓一致是一个探究神经网络模型是否正确编码句法结构的任务。当句子中有更多相反编号(attractors)的名词插入到主语和动词中时,预测动词编号的任务会逐渐变得困难。在之前,Glodberg已经探究了这个方面。作者做了进一步的研究,在每一层网络使用不同的激励(Stimuli)来测试BERT是否学习到较好的句法结构信息。结果如下:
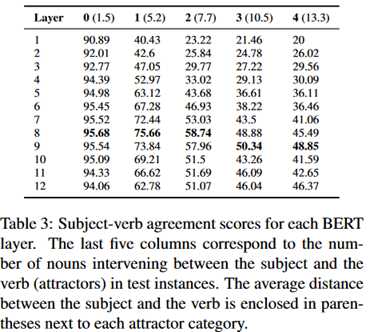
上表是主谓一致得分表,第二列到第六列是在主语和动词插入的名词数量,括号里面的数字是主语到谓语动词的平均距离。结果表明在大多数情况下,中间层网络表现得更好,这也印证了上一部分句法特征主要在BERT中间层进行编码的假设。另外,随着插入名词的增多,BERT更高层的网络也逐渐能够处理长程依赖问题,效果要比低层网络更好,这证明BERT只有有更深的层数才能在大多数自然语言处理(NLP)上更有竞争力。
实验四:组成结构
使用Tensor Product Decomposition Networks(TPDN)来探究。TPDN通过基于使用向量乘积和的预先选择的方案(role scheme)来组合输入符号表示。一个单词的方案可以是基于从语法树根节点到它自身的路径,比如LR代表根节点的左孩子的右孩子。作者假设,对于一个给定的角色设计,如果一个TPDN模型能够很好地被训练去估计一个神经网络学到的表征,那么这个角色设计就很可能能够确定这个神经网络模型学到的组合性特征。
对于BERT的每层网络,作者使用五种不同的角色方案:left-to-right,right-to-left,bag-of-words,bidirectional以及tree。
仿照McCoy等的实验,在SNLI语料库的premise句子上来训练TPDN模型,并使用MSE作为损失函数。结果如下:
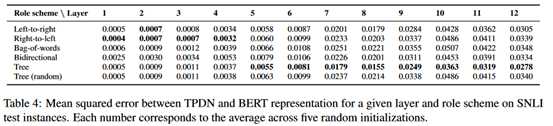
可以看出BERT的高层网络学习到了某种树形结构。
进一步地,作者从自注意力机制权重中推导出了依赖树。具体是使用了Chu-Liu-Edmond算法。结果如下:
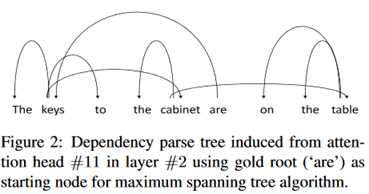
根节点是are,可以看出像are keys的主谓语之间是存在依赖关系的。
作者最终的结论如下:
We have shown that phrasal representations learned by BERT reflect phrase-level information and that BERT composes a hierarchy of linguistic signals ranging from surface to semantic features. We have also shown that BERT requires deeper layers to model long-range dependency information. Finally, we have shown that BERT’s internal representations reflect a compositional modelling that shares parallels with traditional syntactic analysis.
评价:
关注BERT的可解释性已经有不少论文了,彼此之间的侧重点不一样。总体来说,这些工作都证明了BERT是一个很优秀的模型。BERT当前在工业界也已经得到了很广泛的应用。不过本文相较于之前的工作,只是起到了补充证明的作用,没有得出了一些新的结论。
论文阅读 | What Does BERT Learn about the Structure of Language?
标签:href osi 语料库 发布 learn dir rac 机制 surf
原文地址:https://www.cnblogs.com/bernieloveslife/p/12748621.html