标签:ima 技术 mamicode 压力 使用 翻译 经济 例子 ESS
论文地址 :https://arxiv.org/abs/1906.02243v1
作者 : Emma Strubell, Ananya Ganesh, Andrew McCallum
机构 : University of Massachusetts Amherst
研究的问题:
一篇很绿色的文章。作者认为现在的NLP模型,虽然精度提高了,但它们消耗了大量的计算资源,这些资源带来了大量的能源消耗。像模型的开发,本身需要很大成本,计算资源会消耗很多碳资源,产生很多二氧化碳。这很不环保。所以作者量化了最近的一些神经网络的经济成本和环境成本,希望来警醒NLP研究者。
研究方法:
NLP的进步得益于神经网络技术和硬件的进步。在十年前,大部分NLP模型可以在个人电脑进行,现在的都要在好多个GPU跟TPU上进行,这就消耗了很多财力。
即使有足够的钱呢,训练一个模型也会给环境带来很大压力。下面这张图是NLP模型训练排放的二氧化碳跟一些其他东西相比。
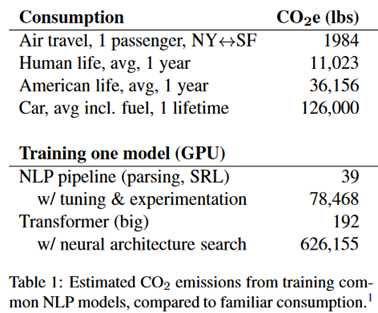
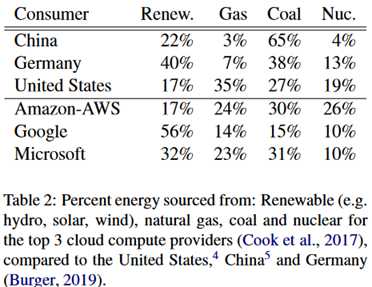
呐,可能会有人反驳说,现在已经有很多可再生资源了。但实际上大多数还是使用的非可再生资源,如下所示。
研究方法:在训练模型的过程中,反复地查询NVIDIA系统管理接口来获得GPU功耗,使用Intel的接口来获得CPU功耗。设p_c是CPU的平均功耗,p_r是DRAM的平均功耗,p_g是GPU的平均功耗。总功耗的公式为:
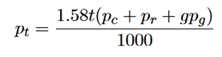
这里的1.58是power usage effectiveness系数。
然后根据美国环境保护署提供的美国电力消耗的平均二氧化碳排放量,将功耗转化为二氧化碳排放量:
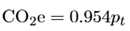
模型训练成本:
使用的模型包括Transformer、ELMO、BERT、GPT-2四个非常流行的模型。
实验结果如下:
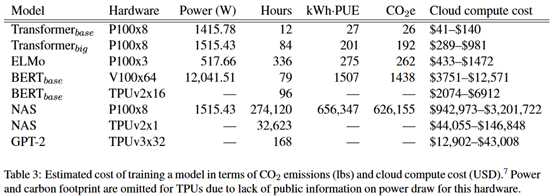
这里的云计算成本是估计的结果。可以看到,成本真的很贵。
这里举了一个例子,So等(2019)在英德翻译上取得了29.7的BLEU,仅仅提高了0.1BLEU,成本至少15万美元。
模型研发成本:
这里以EMNLP2018的Best long paper为例讨论。(我看了一下,就是本文的一作的论文)
这个模型相关的训练持续了172天,此期间执行了123小时的超参数搜索,所花的GPU时间是9998天,约27年。下表是他们花的成本。
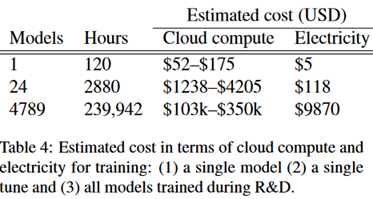
最后作者提出以下倡议:
1、研究人员报告他们的训练时间、超参数敏感性。
2、研究人员应当公平地使用计算资源。
3、研究人员应当考虑计算效率更高的硬件和算法。
评价:
作者提出的一些倡议还是有一定的见解的。也提出了当前越来越依赖计算资源下,会使研究陷入“富人越富”的情况,作者认为应当由政府来给所有研究人员提供公平的资源学术。总的来说,作者提出了他心目中NLP研究的“桃花源”。
论文阅读 | Energy and Policy Considerations for Deep Learning in NLP
标签:ima 技术 mamicode 压力 使用 翻译 经济 例子 ESS
原文地址:https://www.cnblogs.com/bernieloveslife/p/12748603.html