标签:新闻 判断 上下 ant val eval 数据库 ali pack
论文地址 :https://www.aclweb.org/anthology/P19-1412/
作者 :Nanjiang Jiang, Marie-Catherine de Marneffe
机构 : The Ohio State University
研究的问题:
讨论的是推断说话人承诺Inferring speaker commitment(或称event factuality)。它的含义可以通过下面这个例子来理解:
Do you know that Florence is packed with visitors?
Do you think that Florence is packed with visitors?
对于这两句话,前者更体现了提问者对于佛罗伦萨是否充满游客的一个观点,而后者较少地体现提问者的观点,更多的是询问。
因此作者提出假设,语言学的信息导致了推断说话人承诺模型的错误。本文要做的就是,通过实验来比较基于语言学知识的模型和基于神经网络的模型的表现。
研究方法:
任务介绍:
对于说话人承诺任务,它的目标是判断说话人在一个句子当中对于某个事件的承诺程度,分为三类:实际的、非实际的、不确定的。
数据:
使用CommitmentBank数据库,包括1200条数据,每条数据最多由两个上下文句子和一个目标句子组成。数据来源自华尔街日报的新闻专线、英国国家语料库的小说和Switchboard的对话。示例如下:

每条都有至少八名英语母语的人对事实警醒判断。参与者使用李克特量表(Likert scale),在3个点(确定是真、不确定、确定是假)上打分,判断说话者是否确定目标句子中的补语内容正确。
模型:
评估了Stanovsky等(2017)和Rudinger等(2018)的模型。
Stanovsky的模型:一个rule-based的模型,基于TrethTeller,根据谓词的隐含标记和谓词是否处于否定和不确定性修饰符的范围内来得到依赖树。
Rudinger等的模型:一个基于神经网络的模型,包括线性BiLSTM、依赖树BiLSTM以及两种模型的混合模型。
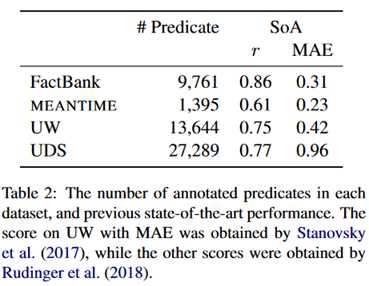
这两个模型分别是基于规则和基于神经网络的state-of-art,在其他数据集上的表现如下:
实验结果如下:
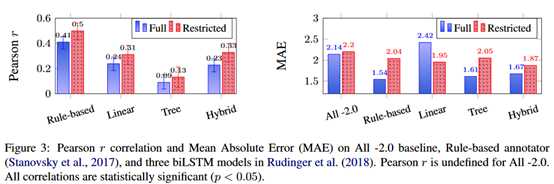
对于图中红色的restricted,也就是数据集的一个子集。这个子集上评估人员达成共识的比例更大一些。
分析:
(1)基于规则的模型只能捕获包含否定的推论,混合模型在否定、情态、问题中表现得比较一致。,两种模型都不能处理条件句。
(2)两种模型在Switchboard的对话上表现最好,在华尔街日报的新闻专线上表现最差。
(3)两种模型在有事实动词的句子中表现更好。
(4)模型行为。混合模型大多预测为正向的,基于规则的模型预测集中在-3和+3.如下图所示。
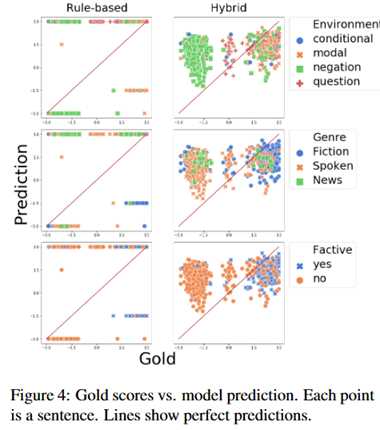
结论:
(1)模型在否定式和非事实动词上表现很好,但是在其它语言学环境(比如情态动词、条件语句)下泛化能力有待提高。
(2)规则基础的模型在一些有挑战难度的数据中比神经网络模型表现更好。
评价:
本届acl的best short paper。文章的结论是基于规则的模型的泛化能力更强一些。但实际上用来训练LSTM的模型只有1000多条数据,所以神经网络模型的表现不好是很显然的。但是基于规则的模型也是存在问题的,从图4中可以看出来,基于规则的模型没有梯度,分布两极化。总的来说,未来的方向应该是结合了规则的神经网络模型。
标签:新闻 判断 上下 ant val eval 数据库 ali pack
原文地址:https://www.cnblogs.com/bernieloveslife/p/12748827.html