标签:mod strong 中心 单词 来源 fan 主题 开源 解码
论文地址 :https://www.aclweb.org/anthology/P19-1479/
作者 : Wei Li, Jingjing Xu, Yancheng He, ShengLi Yan, Yunfang Wu, Xu Sun
机构 : 北大,腾讯PCG
研究的问题:
关注的是对于新闻自动生成评论的问题。传统的方法可以用Seq2seq模型,但是新闻文本很长,这样生成的结果显然是不好的。这里的挑战主要包括:新闻内容长、新闻标题夸张、评论角度的相差大。
本文提出了一种Graph2seq的方法,使用主题交互图来表示文章,将文章的句子组织成若干以主题为中心的顶点。
研究方法:
模型整体结果如下图所示。
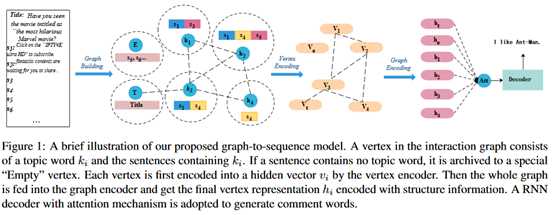
图的构造:
(1)使用Stanford CoreNLP对于新闻分词和做NER。
(2)通过textrank提取关键词。
(3)将句子分配给关键词,如果一个关键词出现在一个句子中,就将这个句子赋给这个关键词,一个句子可以与多个关键词相连,如果一个句子不含任何关键词,就放入空顶点。同时设一个特殊的顶点“title”,包含了标题句。这些句子和关键词(设为k)就组成了一个顶点(V_k)
(4)添加边。如果两个顶点至少共享一个句子,就在它们之间添加一条边。权重由共享句子的数量计算,或使用基于内容的方法,如tf-idf。
顶点编码器:
(1)获得单词的向量表示。包括词编码和位置编码两个部分,最终单词的表示是词编码和位置编码的和。这里关键词和非关键词使用同一种编码方法。这里把关键词放到句首,也就是说所有关键词的位置编码都是相同的,这是为了突出关键词的特殊作用。
(2)通过一个self-attention模块获得隐藏层的向量表示。表示如下:
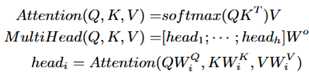
(3)选择句首的关键词的表示作为整个顶点的向量表示。
图像编码器:
使用标准的GCN模型。这种方法的优点在于既可以对顶点的内容进行建模,也可以利用图的结构信息。由于新闻标题是重要信息,使用图编码器的标题顶点的隐藏输出作为解码器的初始状态。表示如下:
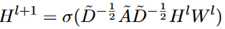
为了过渡平滑问题,在层与层之间加上了残差连接。通过tanh得到输出。
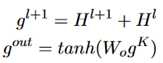
解码器:使用RNN+attention。
这里的输入是GCN的编码结果{g_0,…,g_n}
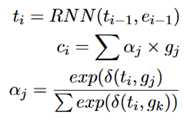
由于标题文字是重要信息,可能会出现在评论中,所以对于标题使用copy机制。
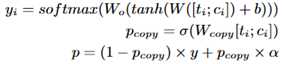
可以理解为,对于标题使用另一种attention计算方式。
实验:数据来源自腾讯快报,主题是娱乐和体育。这部分的数据已经开源了,
https://pan.baidu.com/s/1b5zAe7qqUBmuHz6nTU95UA(提取码:6xdw)
评价指标是人工打分,找了三个人(此处心疼这三位外包同学或实习生)来标的。
Baeline模型:
(1)seq2seq模型:分别以标题(T)、内容(C)、标题+内容(TC)作为输入,最大长度设为100.
(2)self-attention:编码器是self-attention的,解码器是RNN结构的。
(3)多层attention。编码是是多层attention,解码器是RNN。
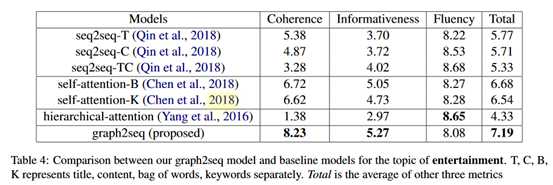
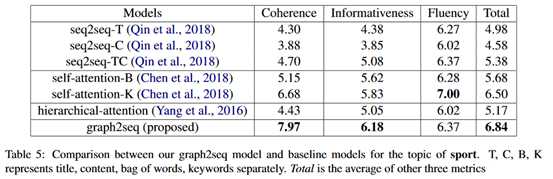
实验结果如下:
一个例子:
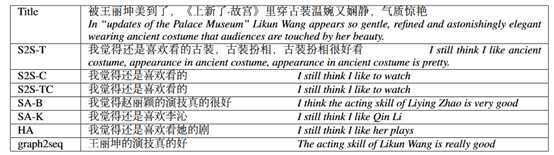
评价:
偏工程的一篇论文。GNN也是当前NLP中比较热门的一个研究方向。这篇文章就是把GNN用到了评论生成中,通过关键词构建顶点,用GCN构成边。针对标题使用了copy机制,也是生成任务中很常用的方法。代码和数据都已经开源,一共是20万篇文章。
另外同样是中文新闻评论生成的,也可以看一下这篇论文。Automatic Article Commenting: the Task and Dataset(https://www.aclweb.org/anthology/P18-2025/)
论文阅读 | Coherent Comments Generation for Chinese Articles with a Graph-to-Sequence Model
标签:mod strong 中心 单词 来源 fan 主题 开源 解码
原文地址:https://www.cnblogs.com/bernieloveslife/p/12748878.html