标签:固定 实验 http 研究 相关 机构 网络 之间 引入
论文地址 :https://www.aclweb.org/anthology/P19-1413/
作者 :I-Ta Lee, Dan Goldwasser
机构 : Purdue University
研究的问题:
关注的是脚本知识的建模问题。脚本,它是结构化的知识表示,用于捕获给定场景下事件与参与者之间的关系。举个例子,对于“汤姆用枪打了约翰”这个事件,“他被警察逮捕了”比“他睡着了”更有可能。
早期的方法,有使用PMI(点互信息)来捕获两者之间关系的,近几年有使用基础事件共现的向量来表示事件,通过向量相似度来度量它们之间的关系。
上述方法的思路就是通过共现来处理,也就是说出现在相似的上下文的事件往往具有相似的表示,这个想法在很多NLP任务中都有效,但对于脚本建模来说过于粗糙。
本文要做的就是,通过捕获多个细粒度关系来表示事件,通过引入翻译中的embedding目标来捕获事件之间的不同关系。
研究方法:
模型部分:
模型概述:框架包括两个预处理阶段:事件提取和关系三元组提取。预处理阶段的输出是一组关系三元组(e_h,e_t,r),其中e_h,是头事件,e_t是尾事件,r是它们之间的关系类型。之后它们作为输入,输入到另一个神经网络,用于学习事件的关系embedding,目标函数是一个能量函数f(e_t,e_h,r),可以被用来做为条件概率p(e_t/e_h,r)或p(r/e_t,t_h)的近似。学习到的时间的关系embedding就是脚本知识,可以用于后续的NLP任务。
事件提取:首先定义事件,每个事件e包括谓语pred(e)、主语subj(e)、宾语obj(e)。
这里通过Stanford CoreNLP的依赖解析器和共指消解来提取事件,和其它的工作不同的是,作者在提取的事件中使用的是完整的提及跨度(mention span)。举个例子,“珍妮走进了她最喜欢的餐厅”,一般的提取结果是“走进,珍妮,餐厅”,本文提取的是“走进,珍妮,她最喜欢的餐厅”。作者认为这有助于模型捕获一些微妙的信息。
三元组提取:
前边提到了,三元组表示为(e_h,e_t,r),其中e_h, e_t是事件,它们的内部结构都是(pred(e),subj(e),obj(e)),r是它们之间的关系类型。本文考虑了11种关系类型和9种话语关系。
对于关系类型,分为两种,一种是同一指代链上的事件之间的顺序,记为COREF_NEXT。另一种是不共享参数的相关事件,如“森林着火了”和“树木燃烧”之间本身没有共同的论点,但它们警察同时发生,因此是相关的。也就是固定大小上下文窗口之间同时发生的事件,记为NEXT。
对于话语关系,从PDTB(一个数据库)中提取了9种关系类型,如reason、result等。鉴于PDTB中带注释的数据不够,这里实现了一个基于规则的注释器来产生数据,比如对于“because”总会连接有因果关系的两句话。作者为了减少误差只选择一些高置信度的词。
那么对于一个给定的事件,最多可能有三种关系,一个话语关系,一种COREF_NEXT、一种NEXT。
复合事件表示:
模型的结构如下图表示。
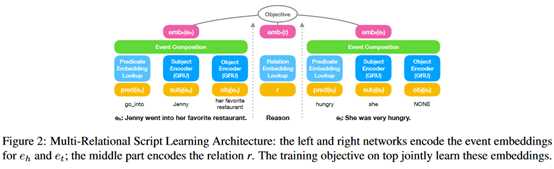
前边提到,对于事件,由(pred(e),subj(e),obj(e))表示,对于它的向量表示,其中pred(e)是通过查表得到的,预先有一个各个动词的向量表示表,subj(e)和obj(e)通过两个独立的Bi-GRU得到,分别称为主语编码器,宾语编码器。
得到事件编码表示之后,通过一层全连接网络来组合输入事件。
对于关系,通过是通过查表的方法得到它的向量表示。
作者提出了两种模型,下面分别介绍。
EventTransE:将节点及其关系嵌入到同一个向量空间中,使用节点之间的距离来表示节点之间的关系。表示如下:
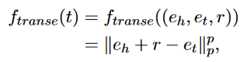
EventTransR:EventTransE的一个缺点在于,不能很好地处理1-N、N-1、N-N的关系。EventTransR将时间和关系使用不同的向量空间表示,通过引入特定于关系的的参数来建模空间之间的交互
目标函数:Margin-based ranking loss
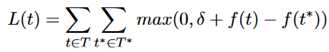
实验部分:
实验的数据来自于纽约时报。
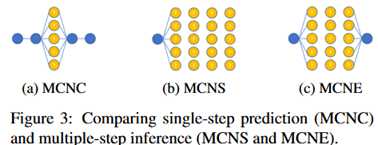
实验一:任务分别是选择是完形填空(MCNC)、选择式叙述序列(MCNS)、选择式叙述解释(MCNE)。
下面这张图很好地解释了这三个任务。
实验结果如下:
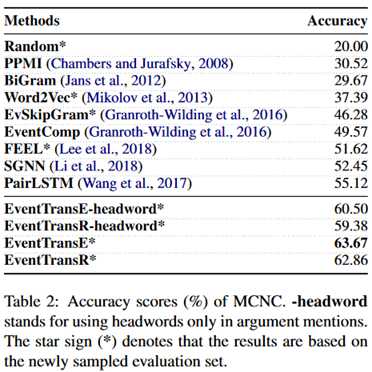
MCNC上的实验结果:
MCNS和MCNE上的实验结果。
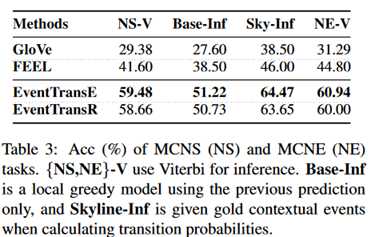
相比于baseline,提升还是比较明显的。这里EventTransR的表现不如EventTransE,也就是说EventTransE对于COREF_NEXT的预测能力比较强。
实验二:内在话语关系评价
给定一个(e_1,e_2,r),定义三种任务分别是预测下一个事件e_2,预测关系r,预测它是否为真。实验结果比较类似,这里就不放图了。EventTransR和EventTransE两个模型均超越了ELMO模型。
实验三:隐含话语意义分类(implicit discourse sense classification)
实验目的是测试在下游任务上的表现。实验结果如下:
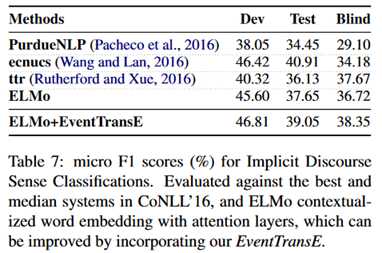
可以看到,只用ELMO就已经达到了很好的效果,结合了本文的模型对于结果又有一定的提升。
评价:
本文实验还是比较充分,实验一、二用来证明模型可以捕获特定关系的信息,实验三用来证明模型在下游任务上的表现。比较有意思的点是,本文的一部分训练数据是通过基于规则的方法(关键词检测)来标注的,在数据不足的情况下是可以考虑用这种方法的。有个疑惑的地方在于,为什么动词和关系embedding都是通过查表得到的,关系的种类是确定的,通过查表可以理解,但是相对来说动词的种类是比较多的。主语和宾语的embedding是通过Bi-GRU编码得到的。这里作者没有给出相应的解释。
论文阅读 | Multi-Relational Script Learning for Discourse Relations
标签:固定 实验 http 研究 相关 机构 网络 之间 引入
原文地址:https://www.cnblogs.com/bernieloveslife/p/12748846.html