标签:mbed 评价 pac 生成 image 作者 word rms line
论文地址 :https://arxiv.org/abs/1906.01753
作者 :Shany Barhom, Vered Shwartz, Alon Eirew, Michael Bugert, Nils Reimers, Ido Dagan
机构 : Bar-Ilan University, Intel AI lab, Technische Universitat Darmstadt
研究的问题:
关注的是跨文档的实体识别,也就是判断来两个来自于不同文档的实体/事件是否是同一个实体/事件。当前主要的研究是关注于同一个文档内的识别,对于跨文档任务,常用的数据集是ECB+,但当前在该数据集上的工作只涉及事件的共指识别。本文提出了一种用于跨文档共指解析的联合模型。
研究方法:
指代的表示:
对于给定的一个指代(实体或事件),使用以下特征来计算它的向量表示。
(1)跨度。使用词级别和字级别的特征,连接在一起作为跨度向量。
(2)上下文。使用ELMO来对上下文建模,取三个LSTM层结果的平均值。
(3)对于其他指代的语义依赖。使用SRL系统对指代之间的语义关系建模,具体是,使用Arg0,Arg1,location,time四种语法角色来表示。如果Arg1被填充了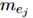 ,它当前属于C这个实体类别。Arg1的向量就是C中所有指代的跨度向量的平均,否则就将它置为零向量。这部分的最终表示是Arg0,Arg1,location,time四部分向量的拼接
,它当前属于C这个实体类别。Arg1的向量就是C中所有指代的跨度向量的平均,否则就将它置为零向量。这部分的最终表示是Arg0,Arg1,location,time四部分向量的拼接
最终使用的向量是上述三种向量表示的拼接。
表示如下:
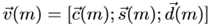
指代的匹配:
整个模型如下图所示。
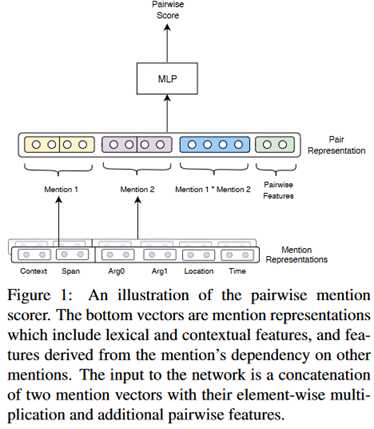
通过S(m_i,m_j)来返回两个指代相同的概率分数,对于实体和事件使用不同的函数。
输入是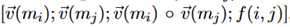 ,O代表的是按元素的乘法。F(i,j)是一个50维的二进制向量,表示两个指代是否有相互引用的参数或谓词。损失函数为二元交叉熵损失函数。
,O代表的是按元素的乘法。F(i,j)是一个50维的二进制向量,表示两个指代是否有相互引用的参数或谓词。损失函数为二元交叉熵损失函数。
Inference:
首先使用k-means对文档聚类,生成一组主题T。在实体聚类和事件聚类之间交替迭代,逐步构建最终的聚类结果。
训练:
与inference的区别在于,使用gold standard的主题集群和初始化来减少训练时的噪音。
下面这种表是两个过程的算法描述。

一些额外的启发式规则:
(1)将带所有格的名字性事件(如Amazon’s)定义为谓词和它的Arg0。
(2)使用spaCy识别主语和宾语是实体的动词事件,将这些实体作为他们的Arg0和Arg1.
(3)对于给定的事件,将其最接近的左/右实体定义为它的Arg0/Arg1.
实验结果:
实体引用的结果:

事件引用的结果:
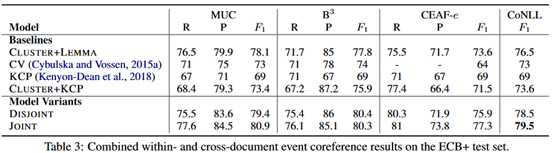
总的来看,优于各种baseline模型。
评价:
本文的主要亮点在于提出的对于指代的表示,分别使用了自身的embedding,这里用了词粒度和字粒度两种,上下文向量,直接使用ELMO来作为上下文表示,ELMO相比于word2vec得到的embedding本身就有很多优点,最后是对于指代之间的关系的建模。一些缺点在于在提取谓语-内容结构时使用的固定的规则带来的误差,另外本文没有提到模型的时间运行效率,不过看下来模型的embedding时间应该消耗比较大。
论文阅读 | Revisiting Joint Modeling of Cross-document Entity and Event Coreference Resolution
标签:mbed 评价 pac 生成 image 作者 word rms line
原文地址:https://www.cnblogs.com/bernieloveslife/p/12748760.html