标签:识别 ber eid using 这一 针对 额外 连接 The
论文地址 :https://www.aclweb.org/anthology/P19-1408/
作者 :Nafise Sadat Moosavi1, Leo Born, Massimo Poesio, Michael Strube
机构 : Technische Universitat Darmstadt, Heidelberg University, Queen Mary University of London, Heidelberg Institute for Theoretical Studies gGmbH
研究的问题:
关注的是共指消解问题,也就是找到指向相同实体的不同表达式。一般解决该问题的方法是识别每个指代的最大跨度。为了解决这个问题,在较小的语料库中手工标注最小跨度。但是这个方案的标注成本比较高,本文做的就是提出了一种自动提取最小跨度的算法MINA。
研究方法:
为了解决最大跨度边界检测的复杂性,一些较小的语料库中明确标注了每个指代的最小跨度和最大跨度。传统的算法基于Gold parse tree和system parse tree,它们存在的问题是可能会产生不同的结果。MINA为了减少gold和system两种方法之间的性能差异而提出。
如何决定最小跨度:
从词所对应的解析树(constituency-based parse trees)中提取MINA范围,也就是说MINA范围是词对应的最大跨度的词的子集。对于对应的最大跨度的解析子树,以宽度优先的方式确定最小跨度。下面是算法描述。

其中,根是解析树的根,标记是用于提取最小跨度的可接受语法标记集,最小深度是解析树中最小跨度节点的深度,mini-spans是算法中对应于最小跨度的词集。可接受的终端节点集(acceptable terminal)指除限定词、连接词以外还包含至少一个词的节点集,终端节点不再进一步拆分。具体包括NP(名词短语)、NML(名词修饰语)、QP(包括量词的名词短语)、NX(一些特定的名词短语)和VP(唯一可接受的动词短语)。
在处理的过程中,以宽度优先的方式处理。跳过标记为不可接受的节点为根的子树。对于其余的节点,将所有的到根距离最近的终端节点作为最小跨度。
例子:
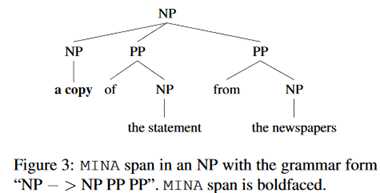
评估最小跨度:
评估包括以下两个指标:
(1)使用MINA提取出的最小跨度长度应小于最大跨度。
(2)MINA提取出的最小跨度和专家手动注释的是否一致。
实验结果如下:
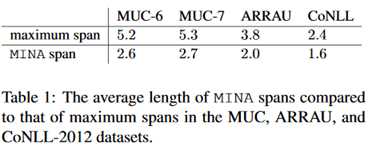
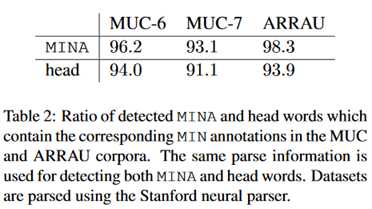
这张表中的head也就是人工标注的结果。可以看到MINA总是大于head,可以认为MINA包含了大部分的指代。
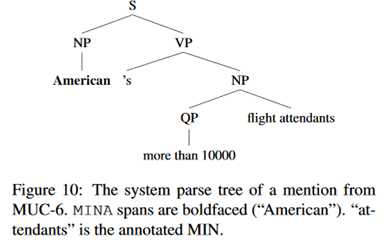
作者分析了这种错误来源,主要来自于解析错误。如下面这张图。
在共指关系任务上的实验:
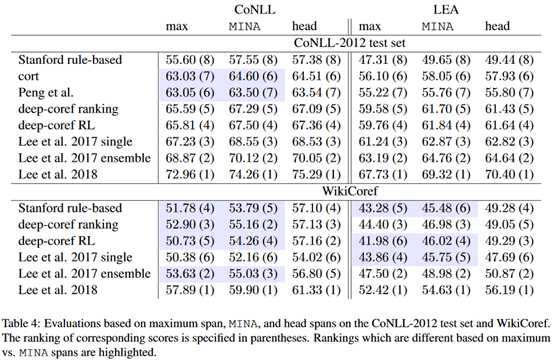
结论:
(1)在跨数据集的评估中,使用最大跨度和最小跨度的评估结果差异比较大,这样因为在最大跨度中边界检测的错误更加明显,会影响评估结果。
(2)MINA在一定程度上减少了gold和system解析树之间的性能差异,也就是分别对两者使用MINA得到的最小跨度在一定程度上抹平了这一点。
(3)由于最大跨度的评估有更多的噪声,基于最小跨度的评估减少了这部分的影响。
评价:
本文提出的MINA,最大的优点在于,不增加额外标注成本的额情况下,基于gold和system解析树提取最小跨度。基于实验结果提出了对于共指关系任务评估的建议和看法。本文的一些分析还是很详细的,针对MINA本身还有共指关系任务上分别作了实验和分析。这个MINA算法在命名实体识别或者其他的一些NLP任务中应该也可以应用。
标签:识别 ber eid using 这一 针对 额外 连接 The
原文地址:https://www.cnblogs.com/bernieloveslife/p/12748744.html