标签:信息 计算 深度 png 实现 with 语句 逻辑 父节点
论文地址 : https://www.aclweb.org/anthology/P19-1410
作者 : Xiang Lin, Shafiq Joty, Prathyusha Jwalapuram, M Saiful Bari
机构 : Nanyang Technological University, Salesforce Research Asia
研究的问题:
关注的是句子级别的连贯分析问题。当前的研究方法有基于贪心转换的算法,优点在于解析时间是线性复杂度,缺点在于每一步的决策都是基本本地信息,会导致错误累积。另一种是基于图表的解析方法,优点在于结果更精确,缺点在于速度很慢。
本文基于修辞结构理论提出了一种句子级别的语篇分析框架,包括一个识别文本中的基本语篇单元的语篇分段器和一个自顶向下构造语篇树的语篇解析器,它基于指针网络来进行话语分割和话语解析。值得一提的是,它们都是O(n)的时间复杂度。
研究方法:
修辞结构理论:
首先介绍修辞结构理论,它将文本定义为一个层次结构,称为话语树。示例如下:

它的叶子节点是文本跨度,称为EDU,相邻的节点通过一定的关系(如属性)递归地连接起来。一致性分析(coherence analysis)就被拆分为了两个子任务:将文本分解为EDU序列,也就是话语分割;将EDU连接成话语树,也就是话语解析。
话语解析:
目标如上所述,是将EDU序列链接到一个标记树中。具体任务是,找到哪些话语单元相关(即找到正确的树结构)和在连接它们时使用什么关系(即使用正确的标签)。
整体结构如下图所示。
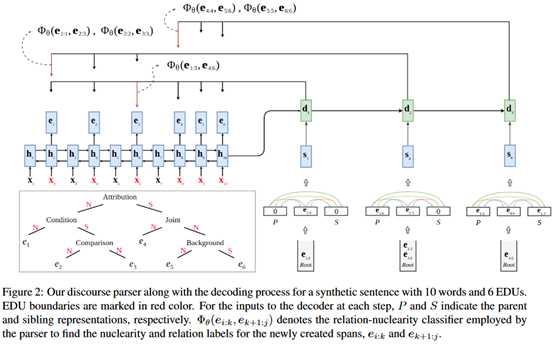
主干是一个指针网络,输入是词向量序列。
编码器将句子编码为状态序列H=(h_1,…,h_n),选择每个EDU的最后一个隐藏状态来表示对应的EDU,从而得到EDU表示序列E=(e_1,…,e_m)。
解码器维护一个堆栈s来跟踪需要进一步解析的文本段和顺序(深度优先),初始化是一个特殊的根符号。在每一个解码步骤,解码器从栈的顶部提取一个文本段e_i:j,生成它的状态表示d_t,用来计算这一段的attention分数。基于attention分布,在i和j之间选择一个位置k将其分割成两段,使用一个关系分类器来得到两个文本段之间的关系。对于得到的两个文本段e_i:k和e_k+1:j,如果某个段的长度大于2,将它重新压进栈。递归运行。
在具体的实现上,使用的是GRU网络,这里作者尝试了Transformer网络,但发现性能不如RNN类网络。
对于关系分类器,它是一个bi-affine分类器。具体是一个两层的神经网络,输入是e_i:k和e_k+1:j目标是预测两者之间的关系。同样地,使用最后一个EDU的表示作为该文本段的表示,也就是用e_k表示e_i:k,用e_j表示e_k+1:j。两层的具体表示如下:
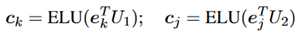
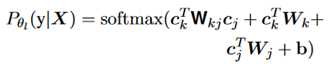
另外在解码器这里,除了当前段的信息,也考虑了它的父节点和左兄弟节点的表示,由于三部分信息的重要度不相同,通过attention获得各部分的权重。
损失函数:包括结构损失和标签损失两个部分,另外加上了L2正则,表示如下:
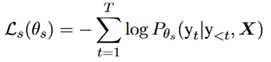
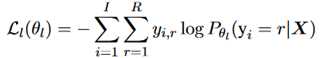
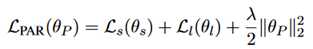
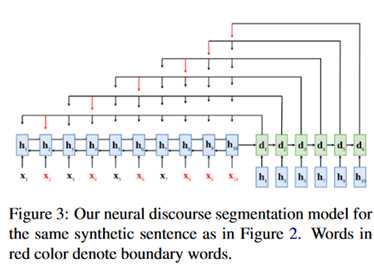
话语分割:
目标是找出一个句子中的EDU界限。这里主要用的是Segbot: A generic neural text segmentation model with pointer network里的网络结构。
模型描述:
整体也是一个端到端的结构。编码器和话语解析的编码器相同,在解码器端生成的状态,用于计算输入语句的分布。结构如下:
其损失函数如下:
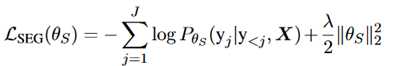
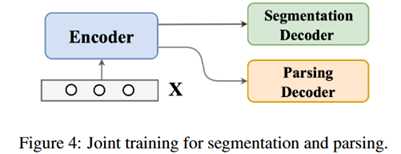
联合训练:
实际上两个网络可以联合训练,并公用一个编码器。
目标函数表示如下:
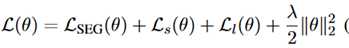
两个decoder的目标其实是相似的,一个更好的分割会有利于更好的解析,反之亦然。
实验部分:
话语分割的实验结果:
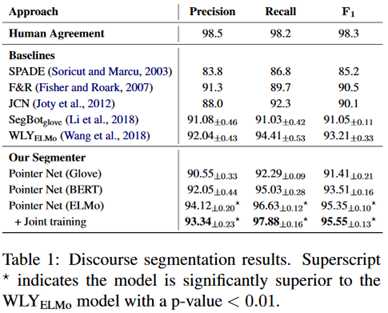
总的来说是优于baseline模型。关注到最后一栏,ELMO相比于Glove有很明显的改进,但是BERT的表现反而不如ELMO。
话语解析的实验结果:
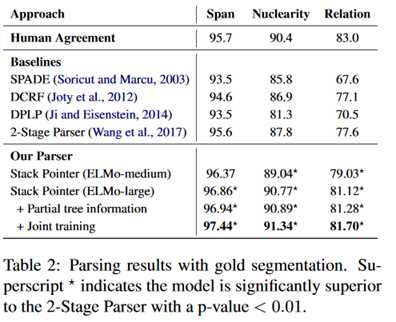
同样是优于baseline模型,可以注意到联合训练对于结果也是有不少的提升的。
整体的端到端性能:
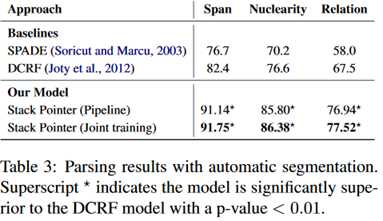
效果很好,不过这里的解析器是单独训练的。
评价:
本文提出的这个网络是一个完全的端到端的网络,不依赖于人工设计的规则。这是模型相比于之前的模型的一个明显的优点,另外模型在时间效率上也有很大的提升,比当前最快的可用系统快了6倍。联合训练减少了整体的参数量,而且两个任务目标是相似的,也是符合逻辑的,从结果来看,也是有一些提升的。
论文阅读 | A Unified Linear-Time Framework for Sentence-Level Discourse Parsing
标签:信息 计算 深度 png 实现 with 语句 逻辑 父节点
原文地址:https://www.cnblogs.com/bernieloveslife/p/12748788.html