标签:style blog http io color ar os 使用 for
原文:你不知道的 页面编码,浏览器选择编码,get,post各种乱码由来asp.net页面编码和浏览器的选择编码
每个asp.net的朋友都知道,在新版本的visual studio,在没有任何设置的情况下,新建页面时的默认编码为utf-8
我们可以从两个地方可以看出:
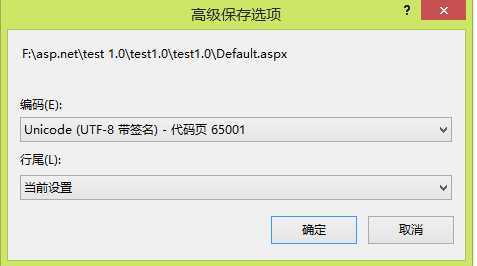
第一:打开aspx页面,“文件”->“高级保存选项”,如下图,可以看出编码为:Unicode(UTF-8带签名)
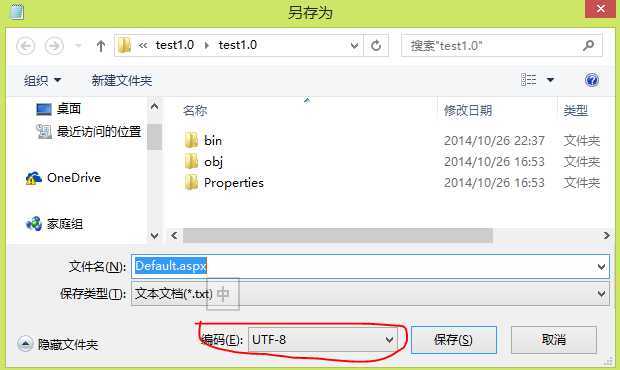
第二:找到aspx存放路径,用系统自带的文本编辑器打开,然后“文件”->"另存为",如下图,可以看出编码为UTF-8
很多时候我们有些疑问,我们经常在aspx页面的<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />强制把carset改为gb2312
然后我们在“文件”->“高级保存选项”,可以看出编码为:GB2312(如果你前面把carset改为gb2312,vs会自动在高级保存选项中进行绑定改变),然后编译运行后,右击html“查看源”发现<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />没有变化,这时候一切正常
下面以IE为例:我们以为此时 “右击浏览器”->“编码” 看到的是 浏览器会选中简体中文(GB2312),但是事实上,你看到的还是选中的Unicode(UTF-8) (再勾选了‘自动选择’前提下)
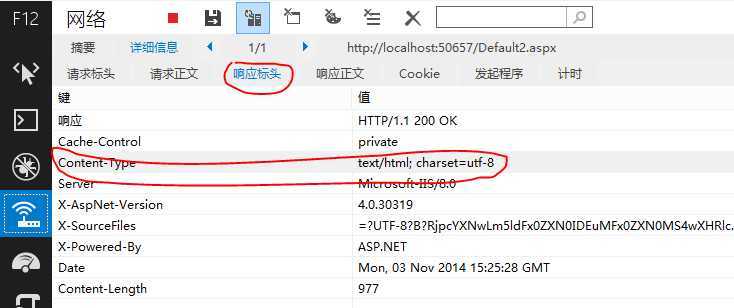
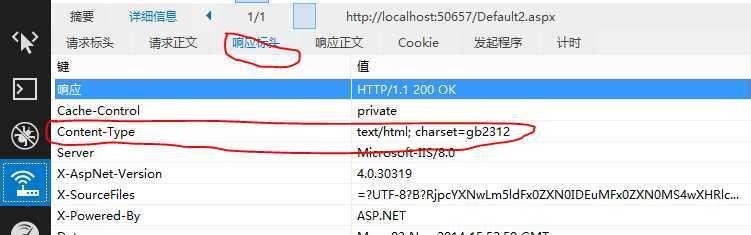
现象已经很明显,但是需要验证浏览器为何会这样,F12调试浏览器(如下图),我们发现content-type竟然是“text/html;charset=utf-8”!
这个现象至少说了两个问题点:
1、asp.net机制至少在某个地方改变了response的ContentEncoding,导致虽然html页面代码上看到的设置<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />并没有生效
2、浏览器再自动选择编码方式的时候不会优先根据html源码中的所展示的<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />代码来决定选择什么编码方式,很明显,以上的现象证明浏览器是优先根据“响应标头-response header”中的键为“Content-Type”的值来自动选择判断,导致html中的所看到的<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />形同虚设。
以上两个问题点很快得到论证:
问题1、在任意新建一个测试页面,在第一个“}”处设置断点,然后命中断点后再“即时窗口”中写入“Response.ContentEncoding.EncodingName”,按enter执行,输出什么?没错:"Unicode (UTF-8)"
protected void Page_Load(object sender, EventArgs e)
{
}
如果了解asp.net生命机制的朋友知道,在执行到Page_Load之前已经执行了很多潜在的初始化事件,类似:Page_Init,LoadViewState, LoadPostData等等,可以想象一定是在某个地方系统为响应页面指定修改了ContentEncoding的值,也就是“响应标头-response header”中的键为“Content-Type”的值为“UTF-8”
我们不妨做一个测试,上面说过,我把<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />的carset改为gb2312,是没有效果的,那么我如果在Page_Load事件中如下写上代码:
protected void Page_Load(object sender, EventArgs e)
{
Encoding gb2312 = Encoding.GetEncoding("gb2312");
Response.ContentEncoding = gb2312;
}
即我在load事件中再次强制性把响应标头中的“Content-Type”改为gb2312,那么浏览器表现如何呢?
这正是我们想看到的,我相信很多朋友有过中文乱码的情况,我先不说具体乱码的解决方案,但是至少搜索发现很多解决方案是在web.config下添加如下节点,即把网站内所有网页的请求编码和响应编码都改为utf-8
<system.web>
<globalization requestEncoding="utf-8" responseEncoding="utf-8" />
</system.web>
其实,上面案例其实只是单个页面的修改response Encoding为gb2312,我们也可以在web.config中添加<globalization requestEncoding="gb2312" responseEncoding="gb2312" />,即整个网站有效
问题2、浏览器编码方式是根据“响应标头-response header”中的键为“Content-Type”的值来自动选择判断,而不会简单的根据你在html中看到的标签值<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />来判定,虽然这个标签一般情况下会写入header,但是有时候会被暗中修改掉,导致html中看到的和调试捕捉到的Content-Type不一致的情况
当然在老版本的ie中,有时候出现的页面全部为空白,右击ie浏览器编码发现没有勾选“自动选择”的情况下会出现这种白屏现象,那不是本文讨论的范围,但是简单的说下原因(拷贝):老版本的ie浏览器解析网页编码时以HTML内的标签优先,而后才是HTTP header内的讯息,而mozilla系列的浏览器则刚刚相反,由于UTF-8为3个字节表示一个汉字,而普通的GB2312或BIG5是两个。页面输出时,由于上述原因,使浏览器解析、输 出<title$amp;>amp;$lt;/title>的内容时,如果在</title>前有奇数个全角字符时,IE把UTF-8当作两 个字节解析时出现半个汉字的情况,这时该半个汉字会和</title>的<结合成一个乱码字,导致IE无法读 完<title>部分,使整个页面为空百输出。而这个时候如果察看源文件的话,会发现实际上整个叶面全部已经输出了
解决方法:将<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />放在<title>测试标题</title>之前(好像现在新建网页默认都在title之前)
asp.net URL参数编码
几乎所有的朋友都会遇到中文情况下乱码的问题,其原因到底是为何?
我先不说乱码问题,先说get和post的区别,几乎没有人不知道
我们在新建asp.net页面时,是很少去对form进行修改的,即保持默认的<form id="form1" runat="server">,可是编译运行后查看代码发现变成<form method="post" action="Default2.aspx" id="form1">
很显然,asp.net默认会为form的method写上post,但是需要注意的是如果仅仅是单纯的html页面,form默认的method是get
我这边可以举一个例子诠释一些无关紧要但是又比较重要的东西:
情况1(post):
浏览器选择编码 : utf-8
编译前的aspx : <form id="form1" runat="server">
运行后的html : <form id="form1" action="Default2.aspx" method="post">
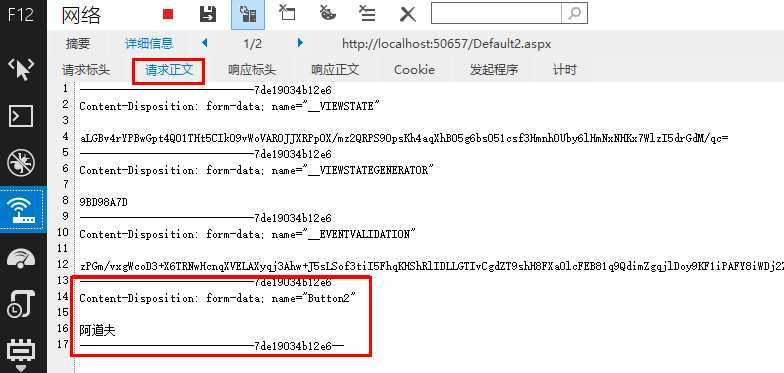
点击服务器按钮(按钮文本:阿道夫):F12在请求正文中有如下图内容

情况2(get):
浏览器选择编码 : utf-8
编译前的aspx : <form id="form1" runat="server" method="get">
运行后的html : <form id="form1" action="Default2.aspx" method="get">
点击服务器按钮(按钮文本:阿道夫):F12在请求正文中有如下图内容

其实,情况1和情况2的对比,并不是我今天想说的意图,但是我还是要稍微顺带说下:
1、我们可以看到get方式的提交,参数仅仅是拼接在url后面,然后直接向web服务器请求,所以我们图中“请求标头-request header”中就可以看到参数的值,而post可以从图中看到,在“请求标头”中并看不到值,而在“请求正文”中看到值,说明post提交时值是包装在请求的body中,发送给服务器,然后向服务器请求数据
2、在asp.net中,图中可以看到不管是get还是post,提交形式不一样,内容确是一样的,本文仅为测试,所以内容相对较少,但是看起来也非常的长了,如果用get提交方式,这就带来隐患,浏览器到底支持多长的uri,web服务器到底支持多长的uri,反正是有限制的(具体长度见:http://www.cnblogs.com/henryhappier/archive/2010/10/09/1846554.html),不仅仅是长度,数据量也是有限制,get数据量较小,不能大于2KB。post传送的数据量较大,一般被默认为不受限制。但理论上,web服务器载体例如iis应该会有限制,比如IIS5的post最大传输量为100kb等
3、安全性,get更加容易暴露参数,而且会被保存在浏览器的历史记录中,但是对于稍微专业点的人来说,post请求传送的数据也是可以被捕捉到的
4、缓存和seo优化等就不提了
5、编码问题!!!(这边上面说这么多,就是为了最后一个“编码问题”)
我将着重讲解编码问题:
在Form元素的语法中,EncType表明提交数据的格式
用 Enctype 属性指定将数据回发到服务器时浏览器使用的编码类型。
一般是下面几种类型:
application/x-www-form-urlencoded: 窗体数据被编码为名称/值对。这是标准的编码格式。
multipart/form-data: 窗体数据被编码为一条消息,页上的每个控件对应消息中的一个部分。
text/plain: 窗体数据以纯文本形式进行编码,其中不含任何控件或格式字符。
假设此时使用get提交form方式:
浏览器则会用x-www-form-urlencoded的数据格式,虽然在F12浏览器调试或者cs代码中的Request.ContentType都看不出来。注意如下是我的get提交的url:
GET /Default2.aspx?__VIEWSTATE=MGASeC9kBMq4iDCI2YLRzkZYqkKYhDhWH2jlP5mpv7idP8gAoNcy0T0y6g6wRvccP%2BFz%2FVx4HdMGwLLW%2BYPbJsMEOTMi5PjS7Ea66DmHQJc%3D&__VIEWSTATEGENERATOR=9BD98A7D&__EVENTVALIDATION=BFMAr0Q6mSwngMhaCLeScGaXywIIRlFClDYAnVhHprxOeifBIGWKNbsunWO9yVOAV6jWHW%2FJ4g2laHQpTvJe%2Fc7X8vralK3hyO5Y0nuiJkT%2FdfxEj9NnCb8S5BfNvZKXVJA%2FOy8yH4Bf9K5DN%2FRI9aDR3EFR86Zm6fN4iEkvJfc%3D&Button2=%E9%98%BF%E9%81%93%E5%A4%AB
我只看最后部分“Button2=%E9%98%BF%E9%81%93%E5%A4%AB”,这是我的服务器按钮“阿道夫”,这一串“%E9%98%BF%E9%81%93%E5%A4%AB”是“阿道夫”三个汉字编码后的,究竟这个编码方式到底是什么?又是如何经常引起乱码问题的呢?
首先:get只能向服务器发送ASCII字符,这是W3C组织规定的,所以任何参数最后都要以ASCII码的形式传递,例如“Button2=%E9%98%BF%E9%81%93%E5%A4%AB”都是ASCII码中的英文字符和符号等字符,没有任何中文字符,其次编码方式是根据当前网页采用选择的编码来编码,例如asp.net网页使用的是utf-8码,那么“阿道夫”用utf-8的编码后的十六进制字符串就是“E9-98-BF-E9-81-93-E5-A4-AB”,和上面提到的“%E9%98%BF%E9%81%93%E5%A4%AB”是不是非常的类似,只是多了百分号
如何查看中文字符的十六进制字符串?方法:BitConverter.ToString(System.Text.Encoding.UTF8.GetBytes("阿道夫"));
如果用本文一开始介绍的方法,在Page_Load中加上
Encoding gb2312 = Encoding.GetEncoding("gb2312");
Response.ContentEncoding = gb2312;
强制把当前页面编码改为gb2312,然后点击按钮,那么我们猜测在F12浏览器调试时,get提交的url的最后部分一定不再是“%E9%98%BF%E9%81%93%E5%A4%AB”,
调试后发现是:“%B0%A2%B5%C0%B7%F2”
那么用BitConverter.ToString(System.Text.Encoding.Default.GetBytes("阿道夫"))生成的值呢?答案是:B0-A2-B5-C0-B7-F2
这一切证明了url参数编码方式是根据当前网页采用选择的编码来编码
然后我将在服务端接受参数,这边有两种情况
情况1、ok,我再次以get方式提交form,并是以utf-8编码(默认),此时,我在服务端通过Request.QueryString["Button2"],我将得到“阿道夫”,一切正常
情况2、ok,我继续以get方式提交form,并是以gb2312编码(如何设置上文讲过),此时,我在服务端通过Request.QueryString["Button2"],我将得到“??????”,正如我愿
为何一开始正常,后面会出现乱码,我这边做几个假设:
假设1、对于情况1 的Request.QueryString["Button2"]没有出现乱码,我是否可以猜测微软Request.QueryString内部自带有解码的操作?并且在这种情况下该操作是utf-8的解码方式
假设2、对于情况2 的Request.QueryString["Button2"]出现乱码,我是否可以猜测是因为微软Request.QueryString内部自带有解码的操作,并按照utf-8解码方式 解码我用gb2312编码的字符,这种不对称的解码肯定是错误的
如何验证我的结论?路过秋天 的这篇文章写的很详细,我总结下大概就是:
反编译Request.QueryString属性,你会发现有这么如下代码:最后深入到代码关键点:this._queryString.FillFromEncodedBytes(queryStringBytes, this.QueryStringEncoding);从FillFromEncodedBytes方法中可以看出调用HttpUtility.UrlDecode(bytes, num2, num3 - num2, encoding)的解码方法,我们现在知道Request.QueryString内部实现是调用了HttpUtility.UrlDecode解码的方法,那么关键点就在HttpUtility.UrlDecode方法的第三个参数encoding到底是哪种解码方式

1 public NameValueCollection QueryString 2 { 3 get 4 { 5 this.EnsureQueryString(); 6 if (this._flags[1]) 7 { 8 this._flags.Clear(1); 9 this.ValidateHttpValueCollection(this._queryString, RequestValidationSource.QueryString); 10 } 11 return this._queryString; 12 } 13 }
1 internal HttpValueCollection EnsureQueryString() 2 { 3 if (this._queryString == null) 4 { 5 this._queryString = new HttpValueCollection(); 6 if (this._wr != null) 7 { 8 this.FillInQueryStringCollection(); 9 } 10 this._queryString.MakeReadOnly(); 11 } 12 return this._queryString; 13 }
1 private void FillInQueryStringCollection() 2 { 3 byte[] queryStringBytes = this.QueryStringBytes; 4 if (queryStringBytes != null) 5 { 6 if (queryStringBytes.Length != 0) 7 { 8 this._queryString.FillFromEncodedBytes(queryStringBytes, this.QueryStringEncoding); 9 return; 10 } 11 } 12 else 13 { 14 if (!string.IsNullOrEmpty(this.QueryStringText)) 15 { 16 this._queryString.FillFromString(this.QueryStringText, true, this.QueryStringEncoding); 17 } 18 } 19 }
下面是FillFromEncodedBytes方法实现:
1 internal void FillFromEncodedBytes(byte[] bytes, Encoding encoding) 2 { 3 int num = (bytes != null) ? bytes.Length : 0; 4 for (int i = 0; i < num; i++) 5 { 6 this.ThrowIfMaxHttpCollectionKeysExceeded(); 7 int num2 = i; 8 int num3 = -1; 9 while (i < num) 10 { 11 byte b = bytes[i]; 12 if (b == 61) 13 { 14 if (num3 < 0) 15 { 16 num3 = i; 17 } 18 } 19 else 20 { 21 if (b == 38) 22 { 23 break; 24 } 25 } 26 i++; 27 } 28 string name; 29 string value; 30 if (num3 >= 0) 31 { 32 name = HttpUtility.UrlDecode(bytes, num2, num3 - num2, encoding); 33 value = HttpUtility.UrlDecode(bytes, num3 + 1, i - num3 - 1, encoding); 34 } 35 else 36 { 37 name = null; 38 value = HttpUtility.UrlDecode(bytes, num2, i - num2, encoding); 39 } 40 base.Add(name, value); 41 if (i == num - 1 && bytes[i] == 38) 42 { 43 base.Add(null, string.Empty); 44 } 45 } 46 }
this.QueryStringEncoding是HttpUtility.UrlDecode解码的关键,我们发现系统默认会先取globalization配置节点的编码方式,如果取不到,则默认为UTF-8编码方式
1 internal Encoding QueryStringEncoding 2 { 3 get 4 { 5 Encoding contentEncoding = this.ContentEncoding; 6 if (!contentEncoding.Equals(Encoding.Unicode)) 7 { 8 return contentEncoding; 9 } 10 return Encoding.UTF8; 11 } 12 }
1 public Encoding ContentEncoding 2 { 3 get 4 { 5 if (this._flags[32] && this._encoding != null) 6 { 7 return this._encoding; 8 } 9 this._encoding = this.GetEncodingFromHeaders(); 10 if (this._encoding is UTF7Encoding && !AppSettings.AllowUtf7RequestContentEncoding) 11 { 12 this._encoding = null; 13 } 14 if (this._encoding == null) 15 { 16 GlobalizationSection globalization = RuntimeConfig.GetLKGConfig(this._context).Globalization; 17 this._encoding = globalization.RequestEncoding; 18 } 19 this._flags.Set(32); 20 return this._encoding; 21 } 22 set 23 { 24 this._encoding = value; 25 this._flags.Set(32); 26 } 27 }
得出结论:
在method为get的提交方式中,如果在web.config中不配置任何globalization相关节点,那么Request.QueryString属性获取uri参数时会自动用utf-8解码,如果此时你的页面是采用gb2312编码,那么cs端获取必定会是乱码
解决方法(form提交method为get):
方法1、配置globalization节点,例如<globalization requestEncoding="gb2312" responseEncoding="gb2312" fileEncoding="gb2312" culture="zh-CN"/>
那么get提交的uri附加的参数会采用gb2312编码,cs服务端Request.QueryString就会根据globalization配置的requestEncoding值gb2312进行内部的HttpUtility.UrlDecode
方法2、不配置globalization任何节点,在html端对将要拼接到uri后面的中文参数进行encodeURIComponent或者encodeURI编码处理,因为encodeURIComponent或者encodeURI就是utf-8的编码方法(永远不会变),然后再cs服务端Request.QueryString接收后,再用 HttpUtility.UrlDecode("", Encoding.Default)进行解码(或者用Server.UrlDecode()解码,效果一样,Server.UrlDecode为使用当前操作系统的编码解码方式),如下:
假设form method=get,当前环境ContentEncoding为gb2312
未做任何处理操作时要请求服务器的uri的一部分:
Default2.aspx?Button2=%B0%A2%B5%C0%B7%F2
在脚本端用encodeURIComponent对”阿道夫“进行编码后的将要请求服务器的uri的一部分:
Default2.aspx?Button2=%E9%98%BF%E9%81%93%E5%A4%AB
cs服务端:
string param1 = Request.QueryString["Button2"];//param1的值为:%E9%98%BF%E9%81%93%E5%A4%AB,虽然Request.QueryString内部有utf-8解码操作,但是对于全是英文和符号等属于assic码的字符不会做任何解码操作(utf-8包含assic)
string param2 = HttpUtility.UrlDecode(param1, Encoding.UTF8);//再针对性的用Encoding.UTF8对在脚本端用encodeURIComponent(编码方式为:utf-8)编码的param1进行对应解码,一切都安静了。值为“阿道夫”
如果理解了编码解码的机制,那么如果仅仅是在cs服务端编码传递带有中文参数的url到另一个页面,也需要注意对应的编码解码问题,比如A页面的按钮点击后跳转到B页面,我举四种情况,大家判断哪种情况下在B页面接收时会有乱码出现
备注: HttpUtility.UrlDecode(param1)在没有第二个参数的情况下默认和HttpUtility.UrlDecode(param1, Encoding.UTF8)等效,除非你强制指定第二个参数比如:HttpUtility.UrlDecode(param1, Encoding.Default)
第一种:没有配置任何globalization节点(正确)
A页面的按钮代码:
1 protected void Button1_Click(object sender, EventArgs e) 2 { 3 string param = "阿道夫"; 4 Response.Redirect("~/Default.aspx?param=" + param); 5 }
B页面的接收代码:
1 string param1 = Request.QueryString["param"];
第二种:配置了globalization节点<globalization requestEncoding="gb2312" responseEncoding="gb2312" fileEncoding="gb2312" culture="zh-CN"/>(正确)
A页面的按钮代码:
1 protected void Button1_Click(object sender, EventArgs e)
2 {
3 string param = "阿道夫";
4 Response.Redirect("~/Default.aspx?param=" + param);
5 }
B页面的接收代码:
1 string param1 = Request.QueryString["param"];
第三种:没有配置任何globalization节点(正确)
A页面的按钮代码:
1 protected void Button1_Click(object sender, EventArgs e)
2 {
3 string param = "阿道夫";
4 Response.Redirect("~/Default.aspx?param=" + HttpUtility.UrlEncode(param));
5 }
B页面的接收代码:
1 string param1 = Request.QueryString["param"];
第四种:配置了globalization节点<globalization requestEncoding="gb2312" responseEncoding="gb2312" fileEncoding="gb2312" culture="zh-CN"/>(乱码)
A页面的按钮代码:
1 protected void Button1_Click(object sender, EventArgs e)
2 {
3 string param = "阿道夫";
4 Response.Redirect("~/Default.aspx?param=" + HttpUtility.UrlEncode(param));
5 }
B页面的接收代码:
1 string param1 = Request.QueryString["param"];
参考上面的解释,应该能理解为何第四种是乱码,这里不再做太多解释
另外在jquery被大行其道的现在,$.ajax{}、$.post()、$.get()等函数使用时更是应该注意编码解码的问题,大致注意如下:
如果你的页面使用的是gb2312编码,不要用jquery的$.get()或$.post()做ajax提交,因为这两个方法默认为utf-8,而且是无法指定修改contentType的,默认为:contentType:"pplication/x-www-form-urlencoded; charset=UTF-8",为什么无法修改?因为$.post 和$.get()本身就只是 $.ajax 的 post 或者get方式的一种简写形式,既然是简写为了方便使用当然会固定死很多属性
可以用$.ajax()并在其中加入:contentType:"application/x-www-form-urlencoded; charset=GB2312";
写成以下形式,可以在大多数情况避免乱码:
$.ajax({
type: "POST",
contentType:"pplication/x-www-form-urlencoded; charset=GB2312",
url: "XXX“,
data: {},
success: function(msg){ alert( msg ); }
});
*****以上使用get提交form方式的介绍真的可以告一段落,我想我写的很臃肿,表达上会有很多冗余的地方******
下面介绍post提交form的方式
在asp.net页面的form不做任何处理的时候,默认编译生成html时会自动加上method="post" ,F12调试,发现Content-Type的值是:application/x-www-form-urlencoded,这也是我上面提到过的Form元素的EncType属性:表明提交数据的格式
一般Enctype 属性指定将数据回发到服务器时浏览器使用的编码类型。
application/x-www-form-urlencoded: 窗体数据被编码为名称/值对。这是标准的编码格式。
multipart/form-data: 窗体数据被编码为一条消息,页上的每个控件对应消息中的一个部分。
text/plain: 窗体数据以纯文本形式进行编码,其中不含任何控件或格式字符
那也就是说,假如我使用post方式提交,Enctype为application/x-www-form-urlencoded,那么那些需要提交服务器的值依然会被编码,只不过这次不是拼接在uri后面,而是存放在body里面,那么这样依然在不小心的情况下会带来上面描述的乱码问题,当然如果你是post提交,(或者你在asp.net页面不操作form任何属性,保持默认)那么在cs服务端请不要再用Request.QueryString获取值了,这是获取不到的,应该用Request.Form[""],请尽量少用Request[""]或者Request.Params[""],这两个将加大你的遍历搜索你需要参数值的范围,Request可以访问的有QueryString、Form、Cookies 或 ServerVariables这4个集合的数据,get请求用Request.QueryString,post用Request.Form,而Request[""]是依次访问这4个集合,找到就返回结果,而Request.Params[""]是在访问时,先将4个集合的数据合并到一个新集合(集合不存在时创建)再去查找,效率可想而知
我现在手动将form改为:<form id="form1" enctype="multipart/form-data" method="post" runat="server"> 注意multipart/form-data只能用于post
浏览器会把整个表单以控件为单位分割,并为每个部分加上Content-Disposition(form-data或者file),Content-Type(默认为text/plain),name(控件name)等信息,并加上分割符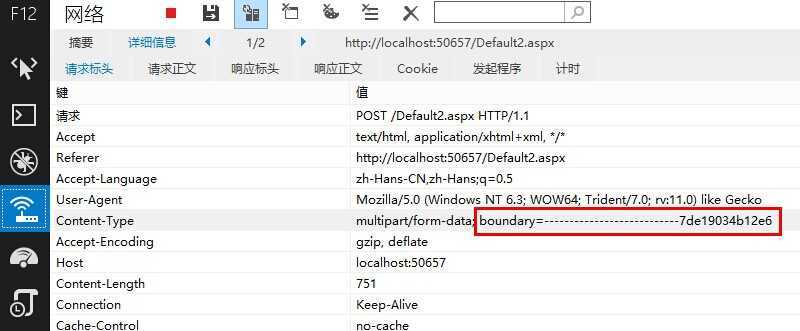
“boundary”是分隔符的意思,一般multipart/form-data用于文件上传,普通的传参或者提交form元素列表值还是使用默认的application/x-www-form-urlencoded吧
推荐的网址:
http://www.cnblogs.com/cyq1162/archive/2010/11/29/1891124.html
http://blog.sina.com.cn/s/blog_89cd68470101e21m.html
http://www.cnblogs.com/fish-li/archive/2011/12/06/2278463.html
你不知道的 页面编码,浏览器选择编码,get,post各种乱码由来
标签:style blog http io color ar os 使用 for
原文地址:http://www.cnblogs.com/lonelyxmas/p/4079143.html
