标签:style blog http color ar os 使用 java for
假设有三台机器,它们的IP地址和对应的主机名为:
192.168.12.18 localhost.localdomain
192.168.2.215 rhel5530g
192.168.35.198 mddb01
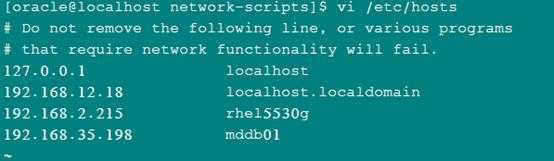
1:在每一台机器的/etc/hosts文件中加入ip地址和主机名的映射,也就是把上面的三行加入到hosts文件中,注意在实际的安装中我们往往需要修改主机名称。配置好的hosts内容如下所示:
2:配置ssh无密码访问:
执行以下命令:
ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
并且把所有节点的authorized_keys的内容相互拷贝加入到每一个节点的authorized_keys中,配置完成后每一个节点的authorized_keys文件的内容应该是一样的。

在继续安装前,一定要保证这一步安装正确,可以使用ssh 主机名命令来测试是否成功,例如:ssh rhel5530g,如果成功则会进入到rhel5530g机器中。
3:解压hadoop文件夹。
4:进入conf目录,配置hadoop文件,我们需要配置以下几个文件:
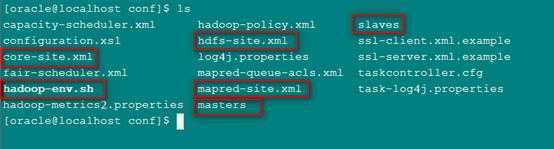
首先配置masters文件:

这里以192.168.12.18做为主节点,也就是namenode节点。
然后配置slaves文件:
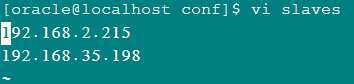
这里以192.168.2.215和192.168.35.198做为datanode节点。
配置hadoop-env.sh文件:

这里是配置java的安装地址。
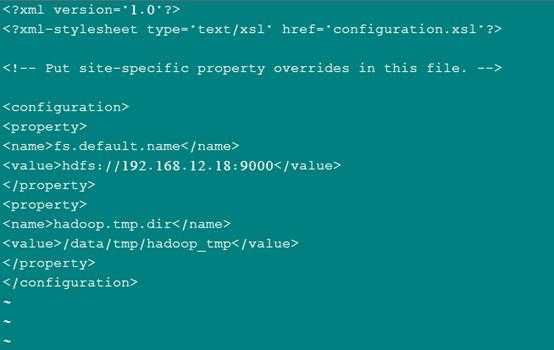
配置hdfs-site.xml文件:
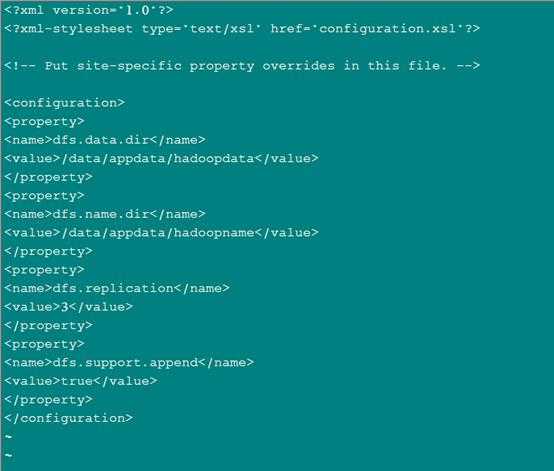
配置core-site.xml:
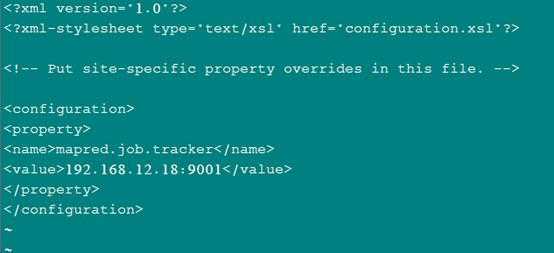
配置mapred-site.xml:
5:把文件复制到其他机器上:
scp -r /data/software/hadoop/ rhel5530g:/data/software/hadoop/
scp -r /data/software/hadoop/ mddb01:/data/software/hadoop/
这里我们是首先在localhost.localdomain机器中配置好文件的,然后再复制到其它机器的。
6:格式化namenode:
cd /data/software/hadoop/hadoop-1.2.1/bin/
./hadoop namenode –format
如果出现……has been successfully formatted,说明格式化成功。
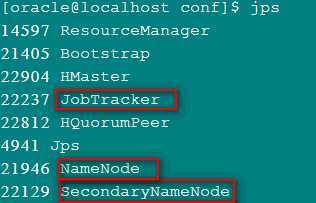
7:启动hadoop,进入bin目录,运行./start-all.sh,执行完成后在master节点运行jps,如果出现以下红色框里的进程,说明执行成功。
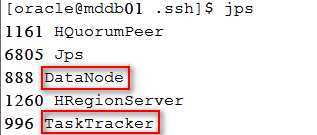
然后在slave节点运行jps,如果出现以下红色框里的进程,说明执行成功。
也可以通过浏览器查看:
http://192.168.12.18:50070/dfshealth.jsp
http://192.168.12.18:50030/jobtracker.jsp
http://192.168.35.198:50060/tasktracker.jsp
http://192.168.2.215:50060/tasktracker.jsp
注意还有可能需要关闭防火墙:
service iptables stop
标签:style blog http color ar os 使用 java for
原文地址:http://www.cnblogs.com/fabulousyoung/p/4078958.html