标签:大量 异常 data- 子集 image 全局 随机选择 子集合 min
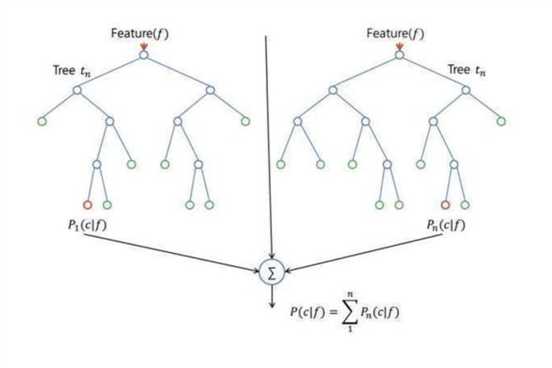
随机森林的构建过程:
1、假设有N个样本,则有放回的随机选择N个样本(每次随机选择一个样本,然后放回后继续选择)。用这选出的N个样本训练一棵决策树,作为决策树根结点处的样本。
2、当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选择出m个属性,满足m<<M。然后从这m个属性中采用某种策略(比如说信息增益)来选择一个属性作为该结点的分裂属性。
3、决策树形成过程中每个节点都要按照步骤2来分裂(如果下一次该结点选出来的哪一个属性时刚刚父结点分裂时用过的属性,则该结点已经达到了叶子节点,无须继续分裂下去)。一直到不能再分裂分止。注意整个决策树形成过程中没有进行剪枝。
4、按照步骤1-3建立大量的决策树,则构成随机森林。
注意这里有两次随机采样,一次是随机选择样本,一次是随机选择属性,因此这里不需要进行剪枝,因为这两次的随机采样,保证了构建的决策树不易出现过拟合问题。
通过分类,子集合的熵小于未分类前的状态,这就带来了信息增益。
决策树的优点:
在数据集上表现良好,两个随机性的引入,使得随机森林不易陷入过拟合,且具有很好的抗噪声能力
能处理高维度(特征很多)的数据,并且不用做特征选择,对数据集的适应能力强
训练速度快
容易做成并行化方法
在训练过程中,能够检测到特征间的互相影响
随机森林主要用于回归和分类。
随机森林的缺陷:
比较难学习到组合特征
解决随机森林过拟合的方法:限制树的深度,限制分裂节点最小样本数,限制叶子节点最小样本数,限制节点分裂所带来的min_impurity_decrease,限制节点分裂所需的最小不纯度都可以缓解过拟合。
参考资料
[1]
标签:大量 异常 data- 子集 image 全局 随机选择 子集合 min
原文地址:https://www.cnblogs.com/mj-selina/p/12757746.html