标签:移动 family ice 吞吐量 ima space pytorch 反馈 部分
ONCE-FOR-ALL: TRAIN ONE NETWORK AND SPE- CIALIZE IT FOR EFFICIENT DEPLOYMENT ON DIVERSE HARDWARE PLATFORMS
ABSTRACT
我们解决了跨许多设备和各种约束,即从通用硬件到专用加速器的高效深度学习模型部署的挑战性问题。传统的方法要么手工设计,要么使用神经结构搜索(NAS)来找到一个专门的神经网络,然后针对每种情况从头开始训练它,这在计算上是禁止的(将导致多达5辆汽车的寿命周期中排放的CO2,参考Strubell等人(2019)论文),因此不可扩展。为了降低成本,我们的关键思想是将模型训练与架构搜索解耦。为此,我们建议训练一个once-for-all的网络(OFA),它支持不同的体系结构设置(深度、宽度、内核大小和分辨率)。在给定的部署场景中,我们可以通过从OFA网络中进行选择,而不需要进行额外的训练,从而快速地获得一个特定的子网络。为了防止训练过程中多个子网络之间的干扰,我们还提出了一种新的渐进收缩算法,该算法可以同时训练大量的子网络(> 1019)。在各种硬件平台(CPU、GPU、mCPU、mGPU、FPGA加速器)上的大量实验表明,OFA的性能始终优于SOTA NAS方法(与MobileNetV3相比,ImageNet top1的精度提高了4.0%),同时降低了GPU工作时间和二氧化碳排放的数量级。特别是,OFA在移动设置(<600M FLOPs)下实现了新的SOTA 80.0% ImageNet top1精度。代码和预先训练的模型在https://github.com/mit-han-lab/once-for-all发布。
1 INTRODUCTION
深度神经网络(DNNs)在许多机器学习应用中提供了最先进的准确性。然而,随着模型规模和计算成本的爆炸性增长,如何在不同的硬件平台上有效地部署这些深度学习模型也面临着新的挑战,因为它们必须满足不同的硬件效率约束(如延迟、能量)。例如,App Store上的一个移动应用程序必须支持多种硬件设备,从配备专用神经网络加速器的高端三星Note10,到配备速度慢得多的5年前的三星S6。对于不同的硬件资源(例如,片上内存大小、#算术单元),最优的神经网络体系结构差异很大。即使在相同的硬件上运行,在不同的电池条件或工作负载下,最好的模型架构也会有很大的不同。
考虑到不同的硬件平台和效率约束(定义为部署场景),研究人员要么设计专门用于移动设备的紧凑模型(Howard et al., 2017; Sandler et al., 2018; Zhang et al., 2018)或通过压缩加速现有模型(Han et al., 2016; He et al., 2018)进行有效部署。然而,为每个场景设计专门的DNNs是非常昂贵的,无论是使用基于人的方法还是NAS,在计算上都非常昂贵。因为这类方法需要重复网络设计过程,并针对每种情况从零开始重新训练设计的网络。它们的总成本随着部署场景数量的增加而线性增长,这将导致过度的能源消耗和二氧化碳排放(Strubell et al., 2019)。这使得它们无法处理大量的硬件设备(到2018年将有231.4亿物联网设备)和高度动态的部署环境(不同的电池条件、不同的延迟需求等)
本文介绍了一种新的解决方案来应对这一挑战——设计一个once-for-all的网络,其可以直接部署在不同的架构配置下,分摊训练成本。推理是通过只选择once-for-all全部网络中的一部分来执行的。它可以灵活地支持不同的深度、宽度、内核大小和分辨率,而无需重新训练。一个简单的once-for-all(OFA)的例子,如图1(left)所示:
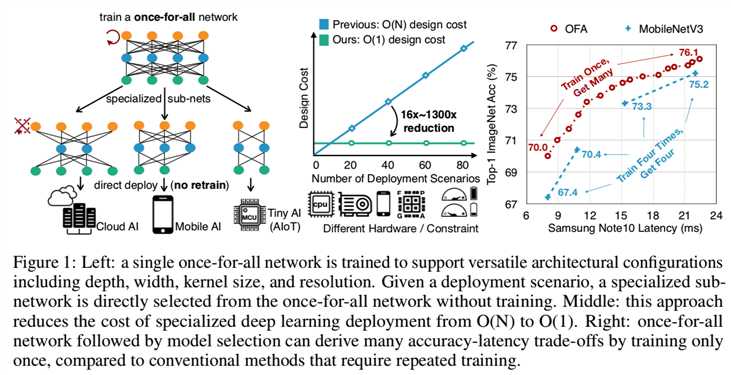
具体来说,我们解耦了模型训练阶段和模型专门化阶段。在模型训练阶段,我们着重于通过选择once-for-all网络的不同部分来提高所有子网络的准确性。在模型专门化阶段,我们对子网络子集进行抽样,以训练准确性预测器和延迟预测器。在给定目标硬件和约束条件下,通过预测引导的体系结构搜索(Liu et al., 2018)得到一个专门的子网络,其代价可以忽略不计。因此,我们将专门的神经网络设计的总成本从O(N)降低到O(1)(如图1,middle所示)。
然而,训练once-for-all网络是一项重要的任务,因为它需要联合优化权值来保持大量子网络的准确性(在我们的实验中超过1019个)。在每个更新步骤中枚举所有的子网络以获得精确的梯度在计算上是禁止的,而在每个步骤中随机抽样几个子网络将导致显著的精度下降。挑战在于不同的子网络相互干扰,使得整个一劳永逸网络的训练过程效率低下。为了解决这个问题,我们提出了一种渐进式收缩算法来训练once-for-all网络。我们建议先训练具有最大深度、宽度和核尺寸的最大神经网络,然后逐步微调这个具有最大深度、宽度和核尺寸的最大神经网络,以支持较小的子网络,这些子网络与较大的子网络共享权值。因此,通过选择较大子网络最重要的权值,提取较小的子网络,可以提供更好的初始化,极大地提高了训练效率。
我们使用了很多硬件平台(CPU、GPU、mCPU、mGPU、FPGA加速器)和效率约束,广泛地评估了OFA在ImageNet上的有效性。在所有部署场景下,与SOTA硬件感知NAS方法相比,OFA始终能够显著提高ImageNet的精度,同时节省GPU的时间、金钱和二氧化碳排放。在ImageNet移动设备上(小于600M FLOPs), OFA以595M FLOPs达到了新的SOTA 80.0% top1精度。据我们所知,这是第一次在移动设置下,SOTA ImageNet top1精度达到80%。
2 RELATED WORK
Efficient Deep Learning. 为了提高硬件效率,提出了许多高效的神经网络架构,如SqueezeNet (Iandola et al., 2016)、MobileNets (Howard et al., 2017; Sandler et al., 2018), ShuffleNets (Ma et al., 2018; Zhang et al., 2018)等。正交于构建高效的神经网络,模型压缩(Han et al., 2016)是高效深度学习的另一种非常有效的技术,包括删除冗余单元的网络修剪(Han et al., 2015)或删除冗余通道(He et al., 2018; Liu et al., 2017),以及降低权重和激活的位宽的量化方法(Han et al., 2016; Courbariaux et al., 2015; Zhu et al., 2017)。
Neural Architecture Search. 神经架构搜索(NAS)关注于架构设计过程的自动化(Zoph & Le, 2017; Zoph et al., 2018; Real et al., 2019; Cai et al., 2018a; Liu et al., 2019)。早期NAS方法(Zoph et al., 2018; Real et al., 2019; Cai et al., 2018b)在不考虑硬件效率的情况下寻找高精度的架构。因此,生成的架构(例如,NASNet、AmoebaNet)在推理时是低效的。最近的硬件感知NAS方法(Cai et al., 2019; Tan et al., 2019; Wu et al., 2019)直接将硬件反馈整合到架构搜索中。因此,它们能够提高推理效率。然而,考虑到新的推理硬件平台,这些方法需要重复架构搜索过程并对模型进行再训练,导致GPU的工作时间、成本和二氧化碳排放都令人望而却步。它们不能扩展到大量的部署场景。单独训练的模型不共享任何重量,导致模型有大的size和高的下载带宽。
Dynamic Neural Networks. 为了提高给定神经网络的效率,一些工作探索了基于输入图像的模型skipping部分的方法。例如,Wu et al. (2018); Liu & Deng (2018); Wang et al. (2018)学习控制器或gating模块自适应drop层;Huang et al. (2018) 在计算图中引入了早期退出分支;Lin et al.(2017)基于输入特征图自适应地对通道进行修剪;Kuen et al.(2018)引入随机下采样点自适应地减小特征图的大小。最近,Slimmable Nets (Yu et al., 2019; Yu & Huang, 2019b) 建议训练一个模型来支持多个宽度乘子(例如,4个不同的全局宽度乘子),以现有的人类设计的神经网络(例如,MobileNetV2的4个乘子:0.35、0.5、0.75、1.0 )为基础。这些方法可以在运行时自适应地适应不同的效率约束,但是,仍然继承了预先设计的神经网络(例如MobileNet-v2),这限制了灵活性的程度(例如,只有宽度乘法器可以适应)和处理预先设计的神经网络不是最优的新部署场景的能力。相比之下,在我们这项工作中,我们实现了更加多样化的架构空间(深度、宽度、内核大小和分辨率)和大量的架构设置(1019 v.s. 4 (Yu et al., 2019))。由于多样性和大的设计空间,我们可以为许多不同的部署场景派生新的专门的神经网络,而不是在现有的神经网络上工作,这限制了优化的空间。然而,训练网络来实现这种灵活性更具挑战性,这促使我们设计渐进收缩算法来应对这一挑战。
3 METHOD
3.1 PROBLEM FORMALIZATION
假设一次性网络的权值为Wo,架构配置为{archi},则可以将问题形式化为:
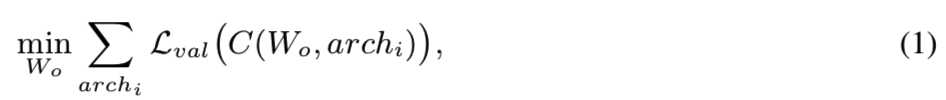
其中C(Wo, archi)表示从once-for-all网络Wo中选择部分模型,形成具有架构配置archi的子网的选择方案。总体的训练目标是优化Wo,使每个被支持的子网络保持与独立训练的具有相同架构配置的网络有相同的精度水平。
3.2 ARCHITECTURE SPACE
我们的once-for-all网络提供了一个模型,但支持许多不同大小的子网络,覆盖了卷积神经网络(CNNs)架构的四个重要维度,即、深度、宽度、内核大小和分辨率。遵循许多CNN模特的惯例(He et al., 2016; Sandler et al., 2018; Huang et al., 2017),我们将CNN模型分成一系列的单元,逐渐减小特征图的大小,增加通道数。每个单元由一系列层组成,只有当第一层的stride为2时,特征图的大小会减小 (Sandler et al., 2018)。单元所有其他层stride为1。
我们允许每个单元使用任意数量的层(表示为弹性深度);对于每个层,我们允许使用任意数量的通道(表示为弹性宽度)和任意大小的内核(表示为弹性内核大小)。此外,我们还允许CNN模型采用任意输入图像大小(表示为弹性分辨率)。例如,在我们的实验中,输入图像的大小在128到224之间,步长为4;每个单元的深度从{2,3,4}中选择;每层的宽度扩展比从{3,4,6}中选择;内核大小从{3,5,7}中选择。因此,5个单元中,我们有大约((3×3)2+(3×3)3 +(3×3)4)5≈2×1019种不同的神经网络结构(即如果一个单元的深度为2,其有两层,该层的宽度有三种选择,内核大小有3种选择,则有(3×3)2种选择;同理如果一个单元的深度为3,则有(3×3)3种选择;同理如果一个单元的深度为4,则有(3×3)4种选择,因此一个单元有(3×3)2+(3×3)3 +(3×3)4种选择,这里是在5个单元中,所以总共有((3×3)2+(3×3)3 +(3×3)4)5种选择),每一种都可以在25种(从128大小开始,步长为4,即下一个输入大小为132、136、140、...、224,一共有25种)不同的输入分辨率下使用。由于所有这些子网络共享相同的权值 (即Wo) (Cheung et al., 2019),我们只需要770万个参数来存储它们。如果没有共享,整个模型的大小将是禁止的。
3.3 TRAINING THE ONCE-FOR-ALL NETWORK
Na ??ve Approach. 将once-for-all网络训练问题转化为一个多目标问题,每个目标对应一个子网络。从这个角度看,一个na??ve训练方法是从头开始使用总体目标的确切梯度来直接优化短暂的网络,其通过列举每个更新步骤的所有子网来生成,如等式1所示。这种方法的成本与子网数量呈线性关系。因此,它只适用于支持有限数量的子网络的场景(Yu et al.,2019),而在我们的情况下,采用这种方法在计算上是禁止的。
另一个na??ve训练方法是每个更新步骤采样几个子网而非列举所有子网,没有成本高昂的问题。然而,由于共享权值的大量子网络相互干扰,我们发现它的精度明显下降。在下一节中,我们将介绍一种解决方案,通过在训练过程中添加渐进收缩训练顺序来解决这一挑战。相应地,我们把na??ve训练方法作为随机顺序。
Progressive Shrinking. once-for-all网络由许多不同大小的子网络组成,小的子网络嵌套在大的子网络中。为了防止子网络之间的干扰,我们建议以渐进的方式将训练指令从大的子网络强制执行到小的子网络。我们将这个训练顺序命名为渐进收缩(PS)。图2提供了PS训练过程的一个例子:
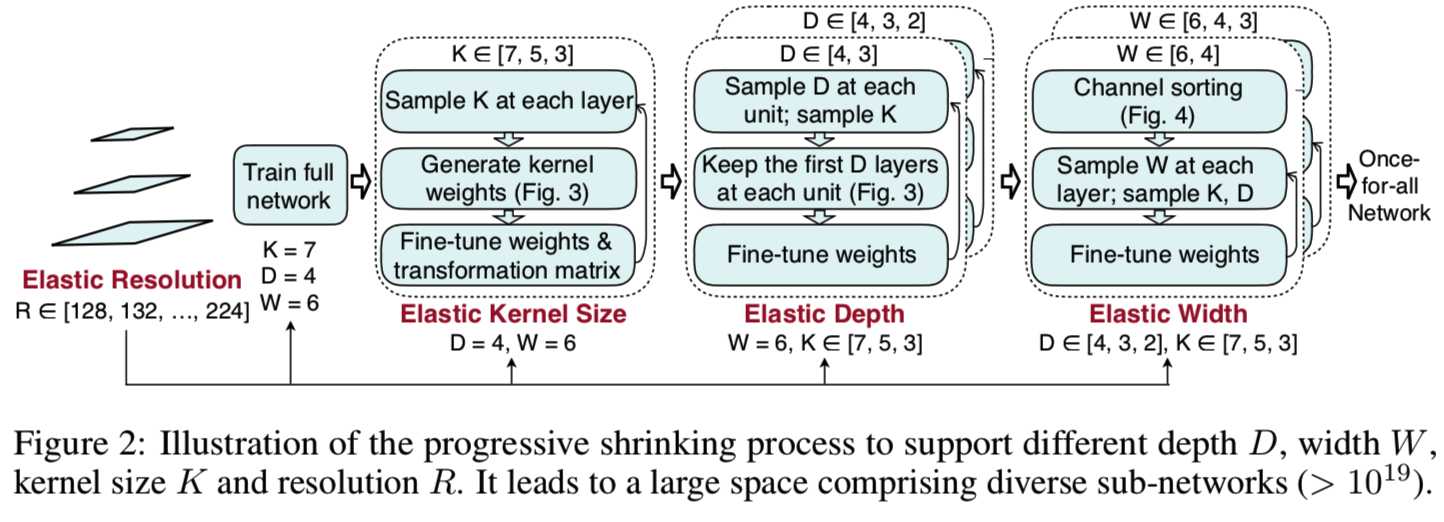
我们从训练最大的神经网络开始,它具有最大的内核大小(即7)、最大的深度(即4)、最大的宽度(即6)。下一步,我们逐步对网络进行微调,以支持较小的子网络,逐步将它们添加到采样空间中(也可以对较大的子网络进行采样)。具体来说,在训练最大的网络后,我们首先支持弹性核的大小,在每一层可以选择{3,5,7},深度和宽度保持最大值。然后,我们依次支持弹性深度和弹性宽度,如图2所示。该分辨率在整个训练过程中是有弹性的,它是通过对每批训练数据采样不同大小的图像来实现的。我们在训练了最大的神经网络后,也使用了知识蒸馏技术(Hinton et al., 2015; Ashok et al., 2018; Yu & Huang, 2019b)。它结合了两个损失项,使用最大的神经网络给出的soft标签和真实的标签
Loss = Losshard? + λLosssoft?
相比na??ve方法,PS阻止小子网干扰大的子网,即当对once-for-all网络微调去支持小的子网络时,大的子网络已经训练好了 。此外,在微调过程中,通过使用较小的学习率和重新访问(即采样)训练好的大的子网络来在训练好的大的子网络周围的局部空间优化模型。对于小的子网络,它们与大的子网络共享权重。因此,PS允许使用训练有素的大型子网络的最重要权值来初始化小型子网络,从而加快了训练过程。我们将PS训练流程的细节描述如下:
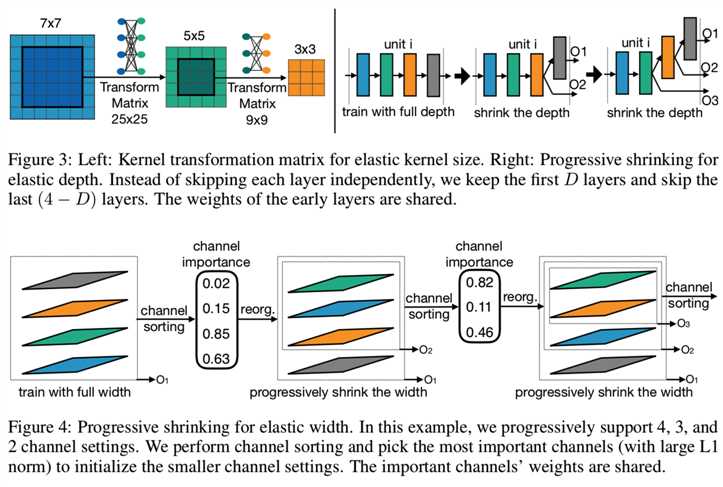
Elastic Kernel Size (Figure 3 left). 我们让一个7x7的卷积核的中心也作为一个5x5的核,它的中心也可以是一个3x3的核。因此,内核大小变得有弹性。挑战在于,中心的子内核(例如,3x3和5x5)是共享的,并且需要扮演多个角色(独立的内核和大型内核的一部分)。中心子核的权值可能需要根据不同的角色有不同的分布或大小。强迫它们相同会降低某些子网络的性能。因此,我们在共享核权值时引入核变换矩阵。我们对不同的层使用不同的核变换矩阵。在每个层中,内核转换矩阵在不同的通道之间共享。因此,我们只需要25×25 + 9×9 = 706个(即将7x7核中间的5x5=25转换为5x5核的值需要25x25个,然后将5x5核中间的3x3=9转换为3x3核的值需要9x9个)额外的参数来存储每一层的核变换矩阵,这是可以忽略不计的。
Elastic Depth (Figure 3 right). 为了在原来有N层的单元中派生出具有D层的子网络,我们保留了前D层并跳过最后N - D层,而不是像当前NAS方法中所做的那样保留任何D层(Cai et al., 2019; Wu et al., 2019)。因此,一个深度设置只对应于一个层的组合。最后,大模型和小模型之间共享第一个D层的权重。
Elastic Width (Figure 4). 宽度表示通道的数量。我们给每一层选择不同通道扩展比例的灵活性。按照逐步缩小的方案,我们首先训练一个全宽模型。然后我们引入一个通道排序操作来支持部分宽度。它根据通道的重要性对通道进行重组,并根据通道权值的L1范数进行计算。L1范数越大越重要。例如,当从4通道层收缩到3通道层时,我们选择最大的3个通道,它们的权值与4通道层共享(图4左、中)。因此,较小的子网络是使用已经过良好的训练的once-for-all网络的最重要的通道来初始化的。这种通道分类操作保持了较大的子网络的准确性。
3.4 SPECIALIZED MODEL DEPLOYMENT WITH ONCE-FOR-ALL NETWORK
在训练了一个once-for-all的网络之后,下一个阶段是为给定的部署场景派生专门的子网络。目标是在优化精度的同时,寻找满足目标硬件效率(如延迟、能量)约束的神经网络。由于OFA将模型训练与架构搜索解耦,因此在这个阶段我们不需要任何的训练成本。此外,我们建立neural-network-twins预测给定的神经网络架构的延迟和准确性,为模型的质量提供一个快速的反馈。它通过将测量精度/延迟替换为预测精度/延迟(twins)来消除重复搜索成本。
具体来说,我们随机样本16k个有着不同的体系结构和输入图像大小的子网,然后在从原始训练集样本采样的10k张验证图像中测量精度。这些[结构、准确性]对 用于训练一个准确性预测器去预测给定结构和输入图像大小的模型的准确性。我们还在每个目标硬件平台上构建了一个延迟查找表(Cai et al., 2019)来预测延迟。考虑到目标硬件和延迟约束,我们进行了基于neural-network-twins的进化搜索(Real et al., 2019),以得到一个专门的子网络。由于使用neural-network-twins进行搜索的成本可以忽略不计,因此我们只需要40个GPU小时来收集数据对,并且无论#部署场景如何,成本都保持不变。
4 EXPERIMENTS
在本节中,我们首先应用渐进式收缩算法来训练ImageNet上的once-for-all网络(Deng et al., 2009)。然后,我们在有着不同延迟限制的不同的硬件平台((Samsung S7 Edge, Note8, Note10, Google Pixel1, Pixel2, LG G8, NVIDIA 1080Ti, V100 GPUs, Jetson TX2, Intel Xeon CPU, Xilinx ZU9EG, and ZU3EG FPGAs)上演示了我们训练过的once-for-all网络的有效性。
4.1 TRAINING THE ONCE-FOR-ALL NETWORK ON IMAGENET
Training Details. 我们使用与MobileNetV3相同的架构空间(Howard et al., 2019)。为了训练整个网络,我们使用带有Nesterov momentum 为0.9和权重衰减为3e−5的标准SGD优化器。初始学习率为2.6,我们使用cosine schedule(Loshchilov & Hutter, 2016)进行学习率衰减。整个网络在32个GPUs上训练了180个epoch,batch size为2048。然后,我们按照图2中描述的时间表进一步调整整个网络。在V100 GPU上,整个训练过程大约需要1200个GPU小时。这是once-for-all的训练成本,可以通过许多部署场景来分摊。
Results. 表1报告了通过我们的渐进收缩(PS)算法和随机顺序训练得到的once-for-all网络的子网的top1精度:
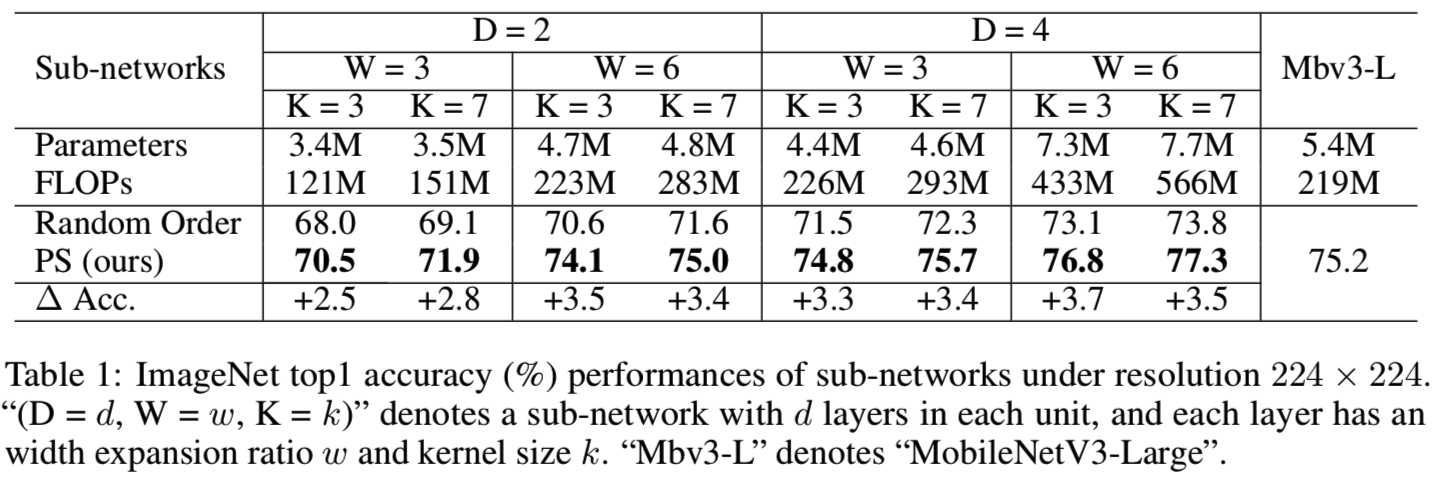
由于空间限制,我们取8个子网络进行比较,每个子网络记为“(D = d, W = w, K = k)”。它表示一个所有单元都有d层的子网络,而所有层的宽度比和内核大小都设置为w和k。与随机顺序相比,PS可以在所有架构设置下显著提高子网的ImageNet精度。具体来说,不进行架构优化,在架构设置(D=4, W=3, K=3)下,使用226M FLOPs, PS可以达到74.8%的top1准确率,与MobileNetV3-Large相当。随机顺序只有71.5%,低了3.3%。
4.2 SPECIALIZED SUB-NETWORKS FOR DIFFERENT HARDWARE AND CONSTRAINTS
我们使用我们训练好的once-for-all网络,为不同的硬件平台提供不同的专用子网络:从云到边缘设备。在云设备上,使用带有Pytorch 1.0+cuDNN的批处理大小为64的NVIDIA 1080Ti和V100测量GPU的延迟。CPU延迟使用批处理大小为1的Intel Xeon E5-2690 v4+MKL-DNN进行测量。在包括手机在内的边缘设备上,我们使用三星、谷歌和带有TF-Lite的LG手机,批处理大小为1;对于移动GPU,我们使用带有Pytorch 1.0+cuDNN的Jetson TX2,批处理大小为16;对于嵌入式FPGA,我们使用Xilinx ZU9EG和带有Vitis AI的ZU3EG FPGA,批处理大小为1。
Comparison with NAS on Mobile Devices. 表2报告了OFA和手机上(Pixel1)最先进的硬件感知NAS方法之间的比较:
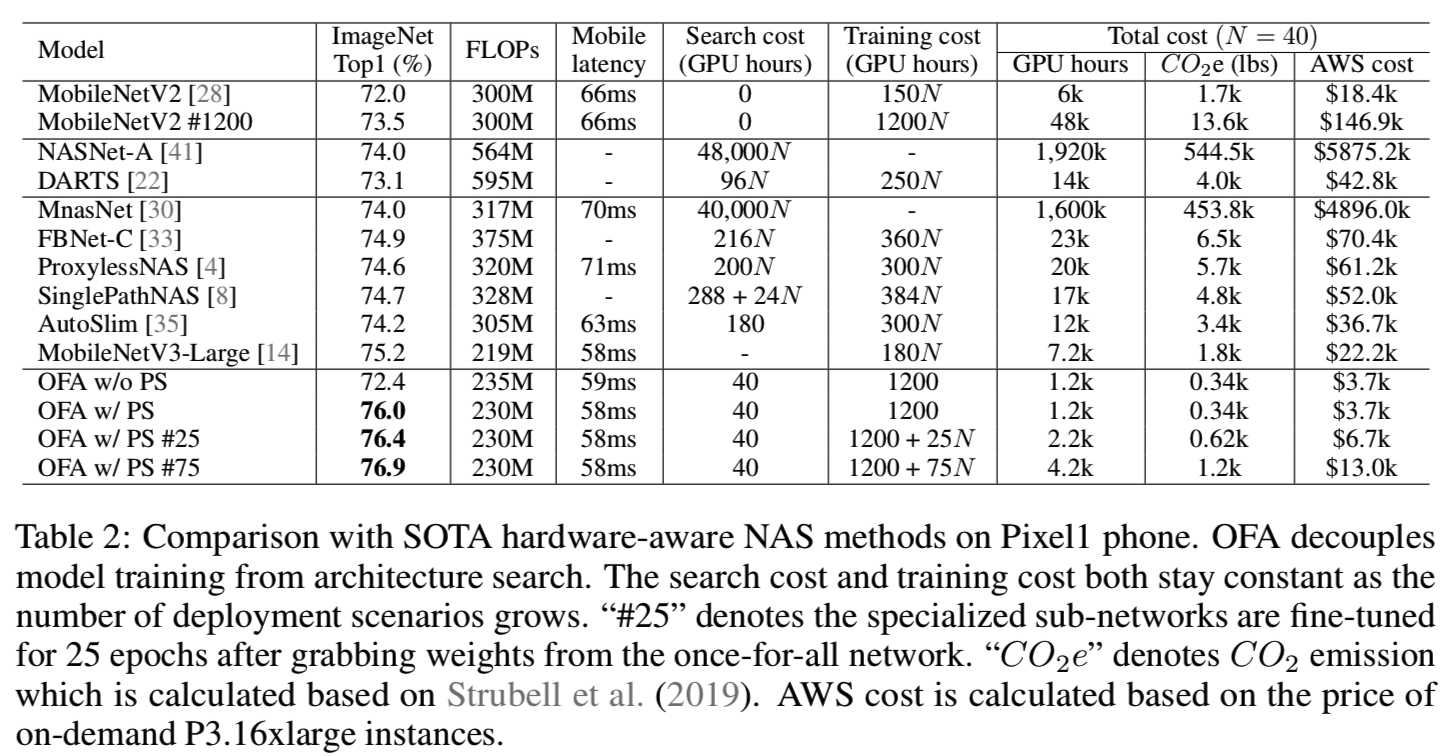
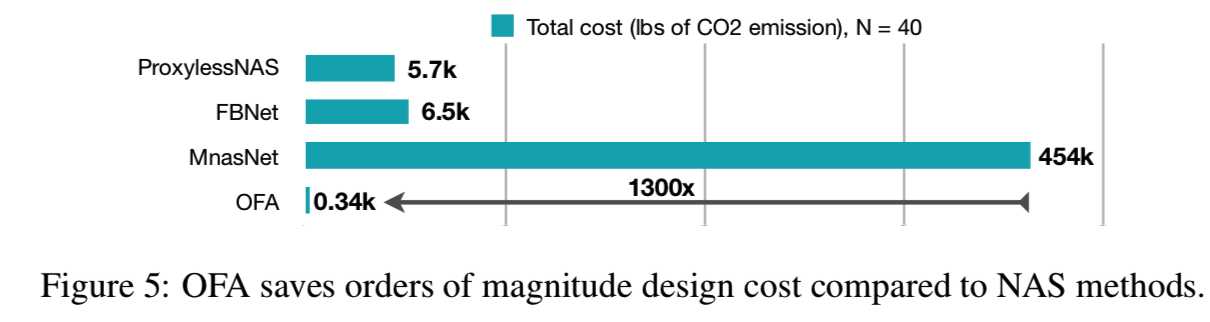
在处理多个部署场景时,OFA比NAS更有效,因为OFA的成本是不变的,而其他的成本是与部署场景的数量(N)线性相关的。N = 40时,OFA的总二氧化碳排放是比ProxylessNAS少16倍的, 比FBNet少19×,比MnasNet少1300×(如图5所示):
没有再训练,OFA能在ImageNet达到 76.0%的top1精度,比MobileNetV3-Large高0.8%,同时能保持相同d的移动延迟。通过对专用子网络微调25个epoch,top1的精度可以进一步提高到76.4%;微调75个epoch,top1的精度可以进一步提高到76.9%。此外,我们还观察到,有PS的OFA的准确率比没有PS的OFA高3.6%,说明PS是有效的。
OFA under Different Computational Resource Constraints. 图6总结了许多OFA在不同的FLOPs和Pixel1延迟约束下的结果。
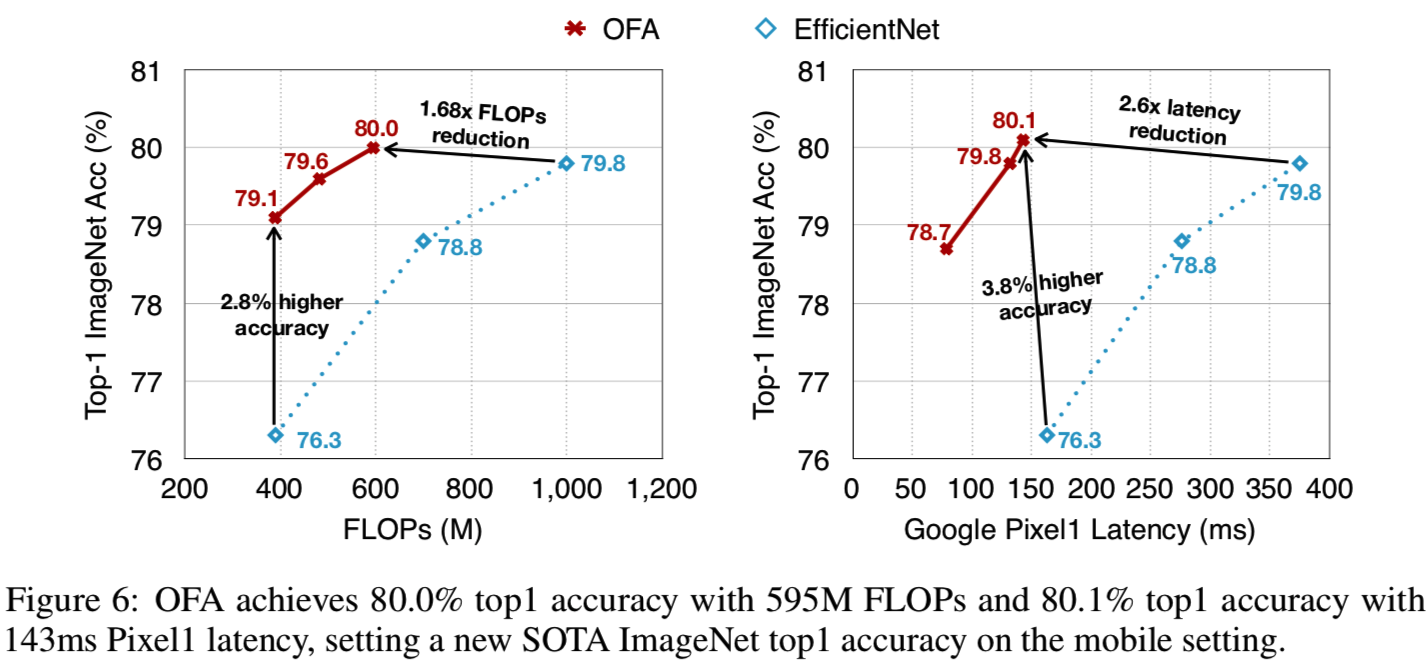
OFA以389M FLOPs达到了ImageNet top1 79.1%的精度,比有着相同的FLOPs的EfficientNet-B0精确2.8%。OFA以595M FLOPs,在移动设置(<600M FLOPs)下,达到新的SOTA 80.0% ImageNet top1精度,比EfficientNet-B2高0.2%,同时仅使用少了1.68×的FLOPs。更重要的是,OFA在硬件上比EfficientNet运行快得多。具体来说,在143ms的Pixel1延迟下,OFA实现了80.1%的ImageNet top1精度,比EfficientNet-B2精度高0.3%,快2.6倍。
图7报告了OFA和MobileNetV3在6个移动设备上的详细比较:
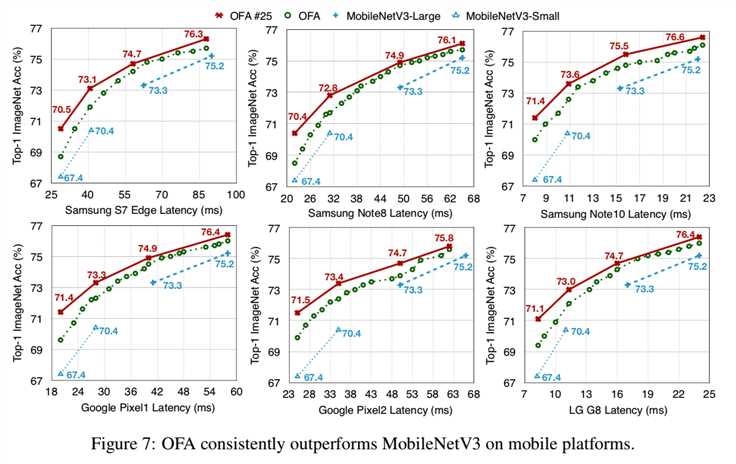
值得注意的是,OFA只需训练一次(绿色曲线),就可以在大范围的延迟约束下生成具有多个点的整条权衡曲线。由于高昂的训练成本,以前的NAS方法是不可能做到这点的(Tan et al., 2019; Cai et al., 2019)
OFA for Diverse Hardware Platforms. 除了移动平台,我们还利用ProxylessNAS架构空间,广泛研究了OFA在6个附加硬件平台上的有效性(图8)(Cai et al., 2019):
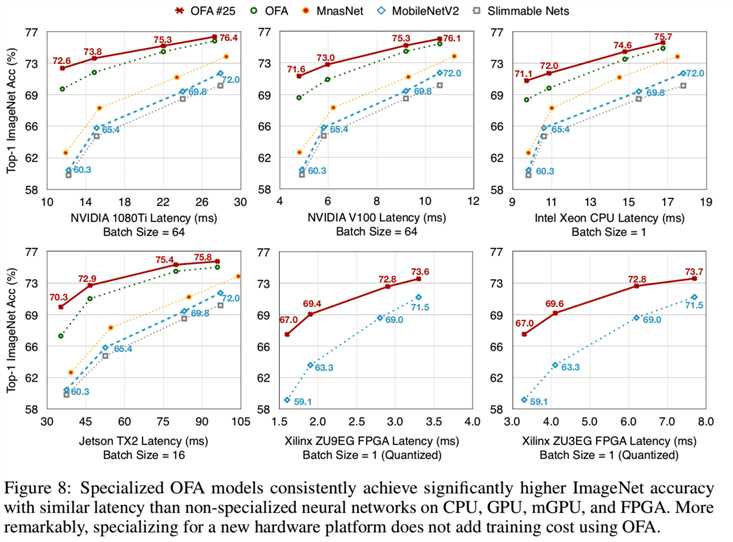
OFA可以显著地改善准确性和延迟之间的平衡,特别是在并行性更好的gpu上。在与MobileNetV2 0.35有类似的延迟时,“OFA #25”提高了ImageNet top1的精度,从1080Ti GPU上MobileNetV2的60.3%提高到72.6%(+12.3%的改进)。我们特定模型的详细架构如图11所示:

它揭示了这样一个观点,即在不同的部署场景中使用相同的模型,只修改宽度乘子,对效率改进的影响有限:随着延迟约束变得更紧,准确性会迅速下降。
OFA for Specialized Hardware Accelerators. 对于用于通用硬件的NAS已经进行了大量的工作,但是很少有工作关注于专门的硬件加速器。我们使用有着8-bit量化的Xilinx Vitis AI对在两个FPGAs加速器 (ZU3EG和ZU9EG)上OFA的性能进行了定量分析,并讨论了两个设计原则。
Principle 1: 内存访问是昂贵的,计算是廉价的。一个高效的CNN应该用很少的内存占用来做同样多的计算。该比率被定义为算术强度(OPs/Byte)。OPs/Byte越高,内存越少,并行化就越容易。由于OFA对子网架构的多样化选择(1019个)(3.3节),以及OFA模型twin可以快速给出精度/延迟反馈(3.4节),进化搜索可以自动找到具有更高算术强度的CNN架构。如图9所示:
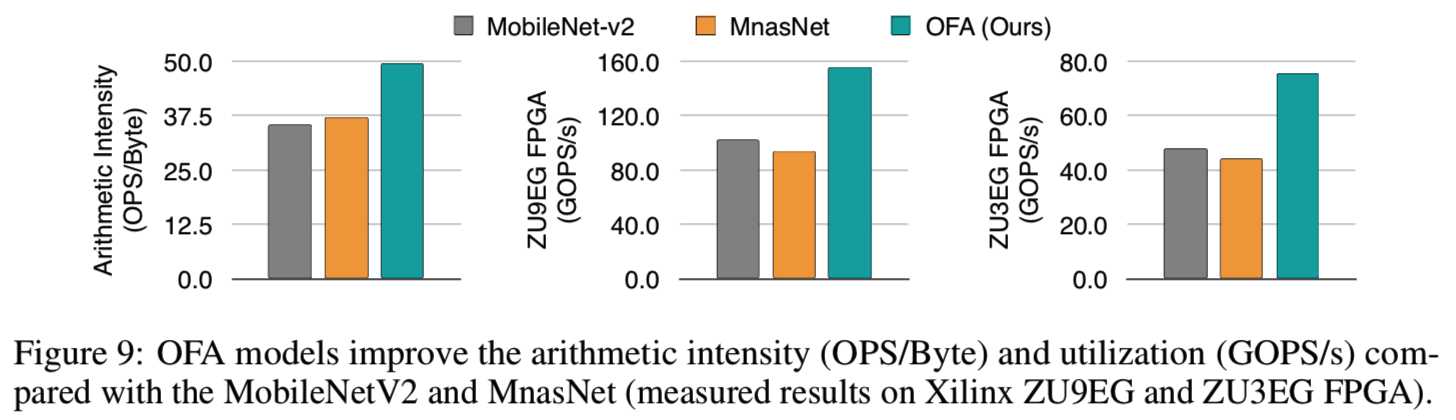
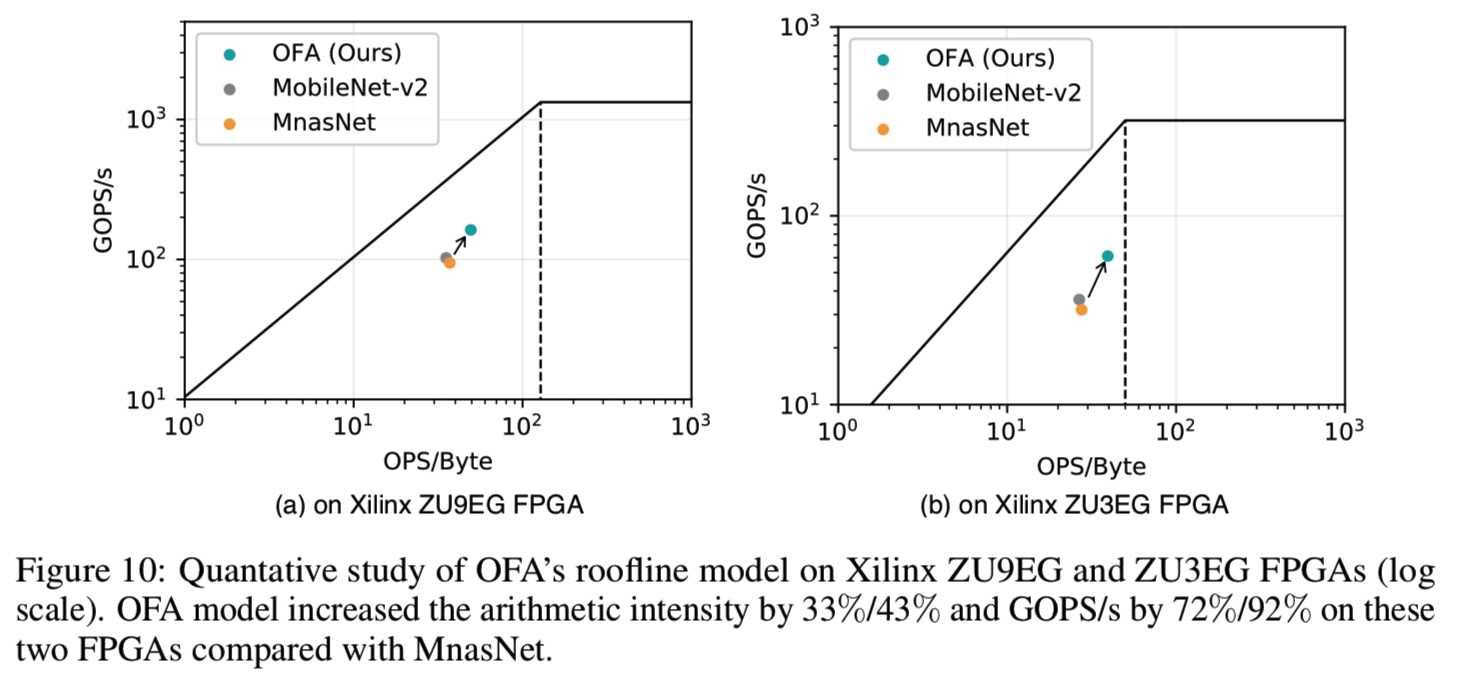
OFA的算法强度比MobileNetV2和MnasNet高48%/43% (Xilinx Vitis AI不支持MobileNetV3)。消除内存瓶颈将导致更高的利用率和GOPS/s提高70%-90%,将操作点推到roofline模型(Williams et al., 2009)中的右上角,如图10所示。(70%-90%在对数尺度上看起来很小,但意义重大)。
Principle 2: CNN架构应该与硬件加速器的成本模型共同设计。FPGA加速器有一个专门的depth-wise的引擎,它与point-wise的引擎是管道连接的。该管道吞吐量与3 * 3大小的内核非常匹配。因此,OFA的搜索模型在FPGA上只有3x3的内核(图11,a),而5x5和7x7的内核也在搜索空间。此外,大内核有时会在FPGA上导致“out of BRAM”错误,从而导致较高的成本。然而,在Intel Xeon CPU上,超过50%的操作是大内核。由于计算阵列的大并行性,FPGA和GPU模型都比CPU宽。
5 CONCLUSION
我们提出了一种once-for-all(OFA)的新方法,它将模型训练从架构搜索中分离出来,从而在大量的硬件平台下实现高效的深度学习部署。与以前为每个部署场景设计和训练神经网络的方法不同,我们设计了一个once-for-all的网络,它支持不同的体系结构配置,包括弹性深度、宽度、内核大小和分辨率。与传统方法相比,它大大降低了训练成本(GPU时间、能源消耗和二氧化碳排放)。为了防止不同规模的子网络受到干扰,我们提出了一种渐进收缩算法,使大量的子网络达到与独立训练相同的精度水平。在各种硬件平台和效率约束上的实验证明了我们方法的有效性。OFA提供了一个自动化的生态系统,在循环中高效地设计带有硬件成本模型的高效的神经网络。
标签:移动 family ice 吞吐量 ima space pytorch 反馈 部分
原文地址:https://www.cnblogs.com/wanghui-garcia/p/12753816.html